构建基于Llama3.1-70B的医疗诊断系统
在大模型技术迅猛发展的背景下,通用人工智能正加速向垂直领域渗透,行业智能化升级的需求日益迫切。面对医疗等专业场景对模型精准性、专业性与可解释性的高要求,通用大模型的泛化能力已难以充分满足实际应用需求——产业界正呼唤更加专业化、场景化、高可靠的AI解决方案。
Llama 3.1-70B是Meta推出的高性能开源大语言模型,拥有700亿参数,具备强大的语言理解与生成能力,适用于医疗等高专业性领域。通过结合高质量行业数据集(如:medical_o1_sft_Chinese_alpaca)进行指令微调,可构建具备深度领域认知的专用模型,精准掌握医学推理逻辑与术语规范。
在微调过程中,Llama 3.1-70B融合了大量医学对话、临床推理案例与专业文本数据,显著提升了其在长上下文中的医学信息记忆能力、诊断逻辑一致性与术语使用准确性。它不仅可作为医生的智能辅助工具,提升诊疗效率,也可用于医学教育中的虚拟病例交互、患者健康咨询机器人等场景。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Llama 3.1-70B-Instruct | 是 | 经过指令微调,参数量约700亿 (70B),专为高精度指令理解与复杂任务执行而优化。 |
| 数据集 | medical_o1_sft_Chinese_alpaca | 是 | 医疗诊断数据集。 |
| GPU | H800*8(推荐) | - | - |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
- 模型微调时长
- 微调后模型Evaluate & Predict时长
- 原生模型Evaluate & Predict时长
操作详情
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
单击上图“开始微调”按钮,进入[配置资源]页面,选择GPU资源,卡数填写
8,点击“启动”,如下图所示。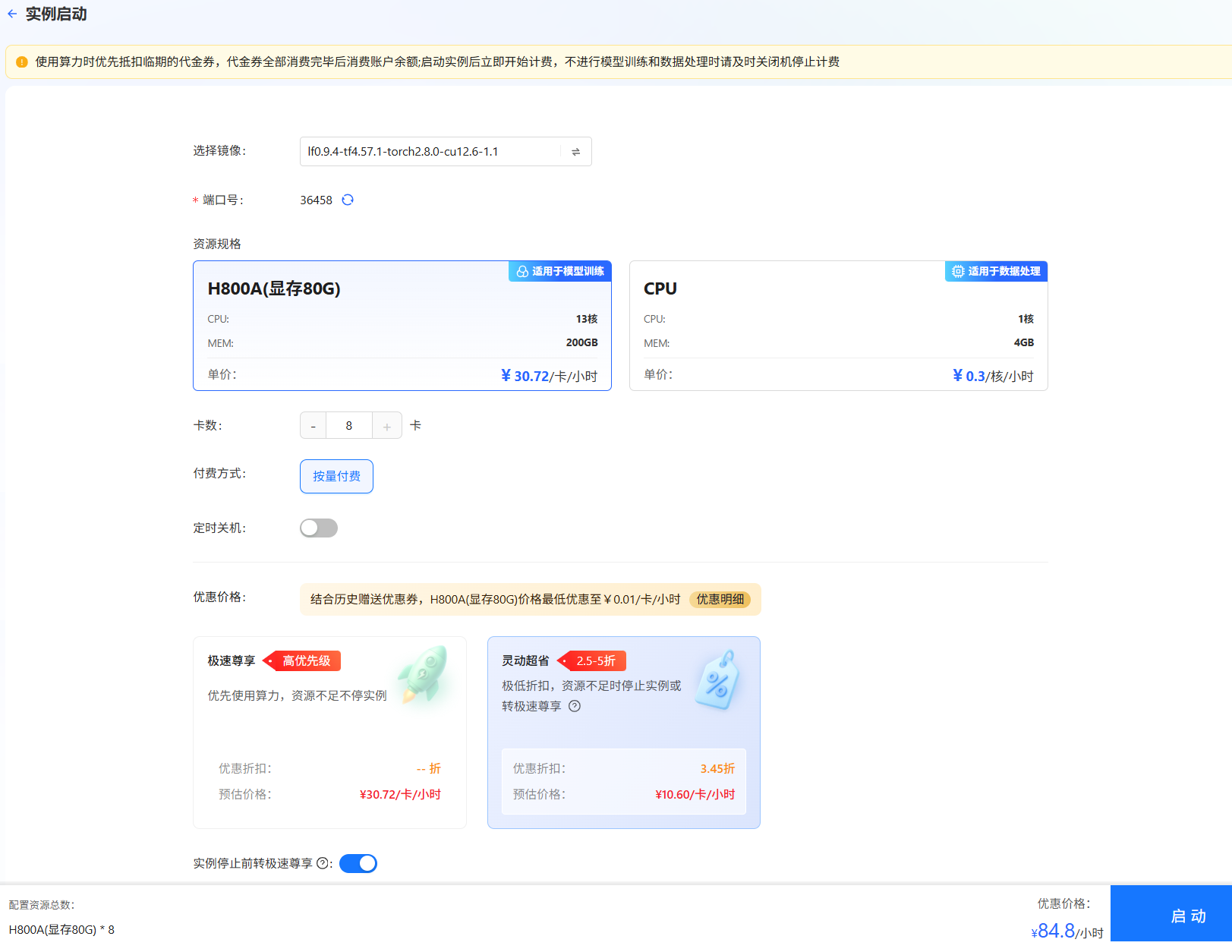
-
待实例启动后,点击[LlamaFactory快速微调模型]页签,进入LlamaFactory Online在线WebUI微调配置页面,语言选择
zh,如下图高亮①所示;模型名称选择Llama-3.1-70B-Instruct,如下图高亮②所示;系统默认填充模型路径/shared-only/models/meta-llama/Llama-3.1-70B-Instruct。 -
微调方法选择
lora,如下图高亮④所示;选择“train”标签,训练方式保持Supervised Fine-Tuning,如下图高亮⑤所示;数据路径保持/workspace/llamafactory/data,如下图高亮⑥所示;数据集选择平台已预置的medical_o1_sft_Chinese_alpaca,如下图高亮⑦所示。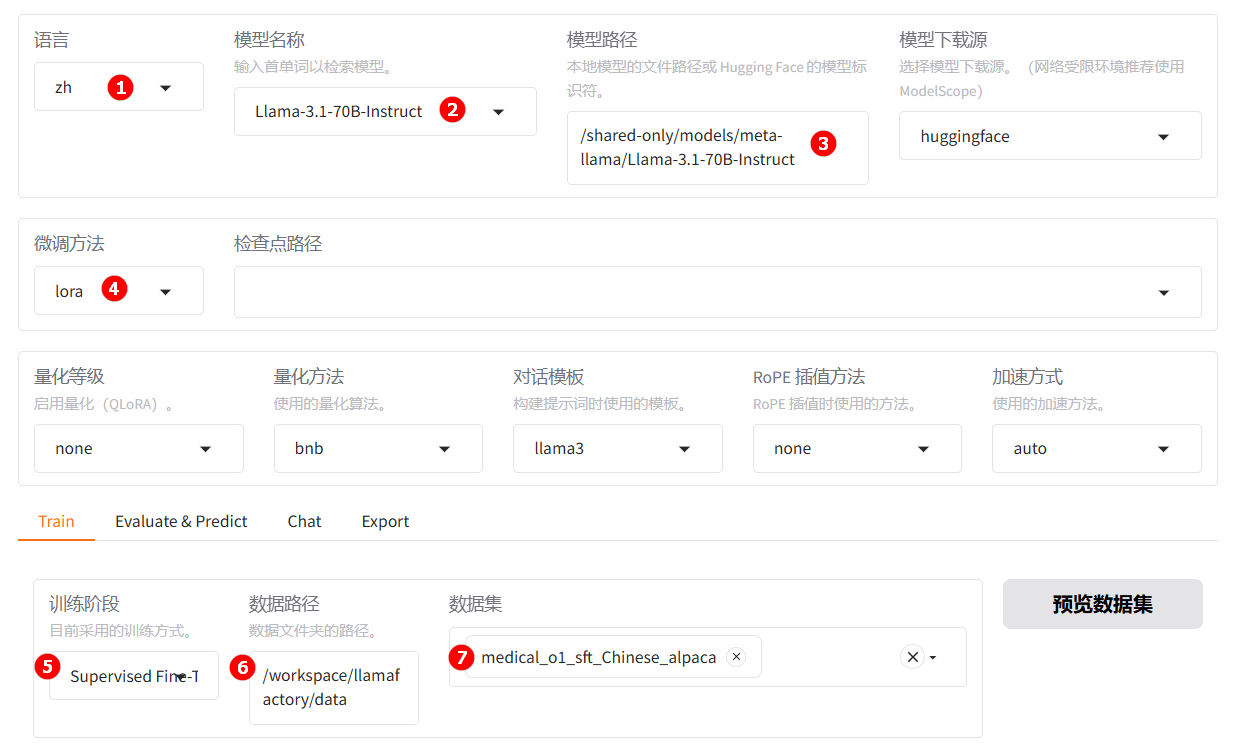
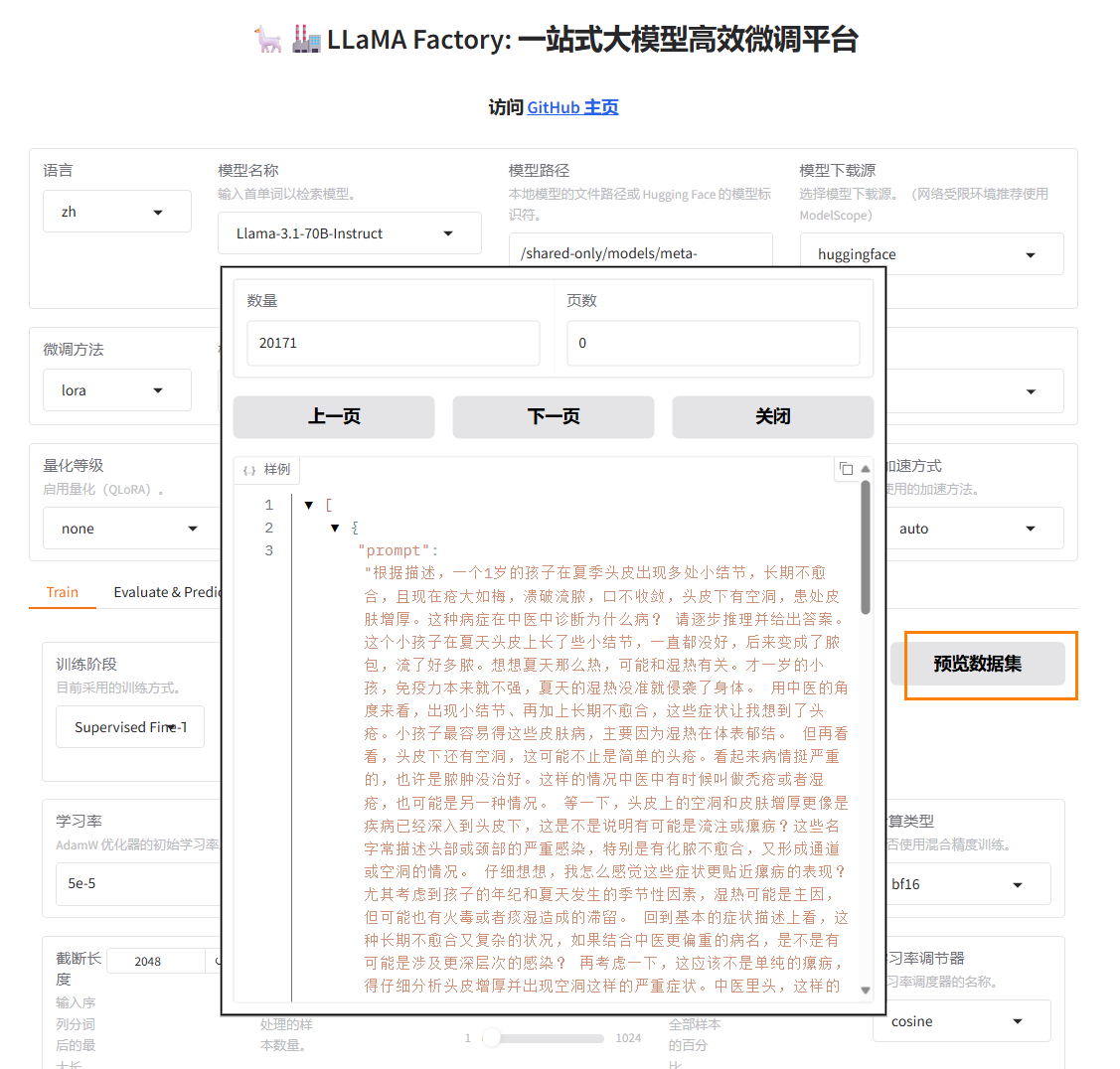
点击“预览数据集”,可以预览数据样例。
-
其余参数可根据实际需求调整,具体说明可参考参数说明。
本实践中的其他参数设置修改如下,其他参数保持默认。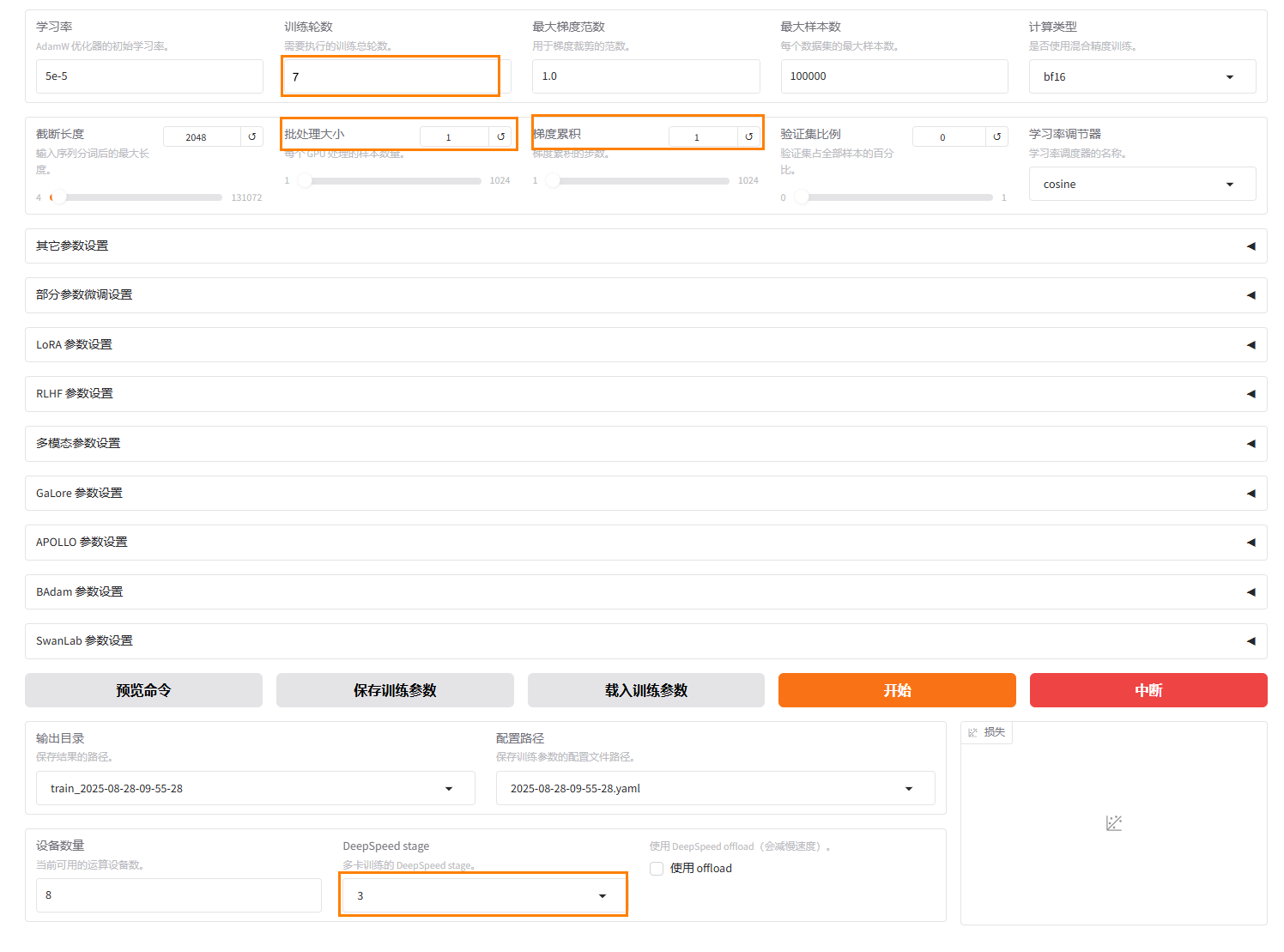
-
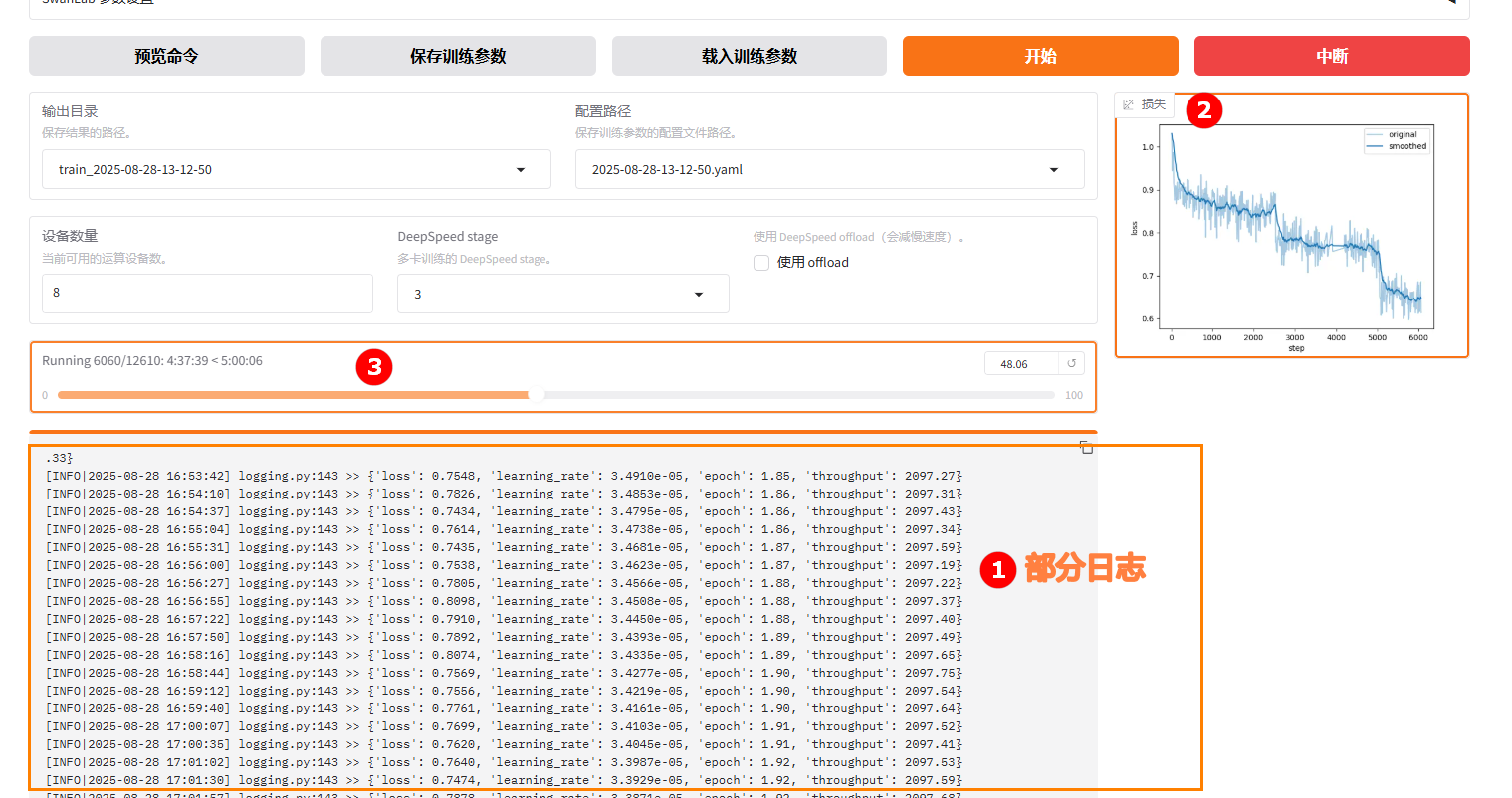
参数配置完成后,点击“开始”按钮启动微调任务。页面底部将实时显示微调过程中的日志信息,例如下图高亮①所示;同时展示当前微调进度及Loss变化曲线,如下图高亮②所示。微调完成后,下图高亮③处会提示:“训练完毕”。
- 微调后模型对话
- 原生模型对话
-
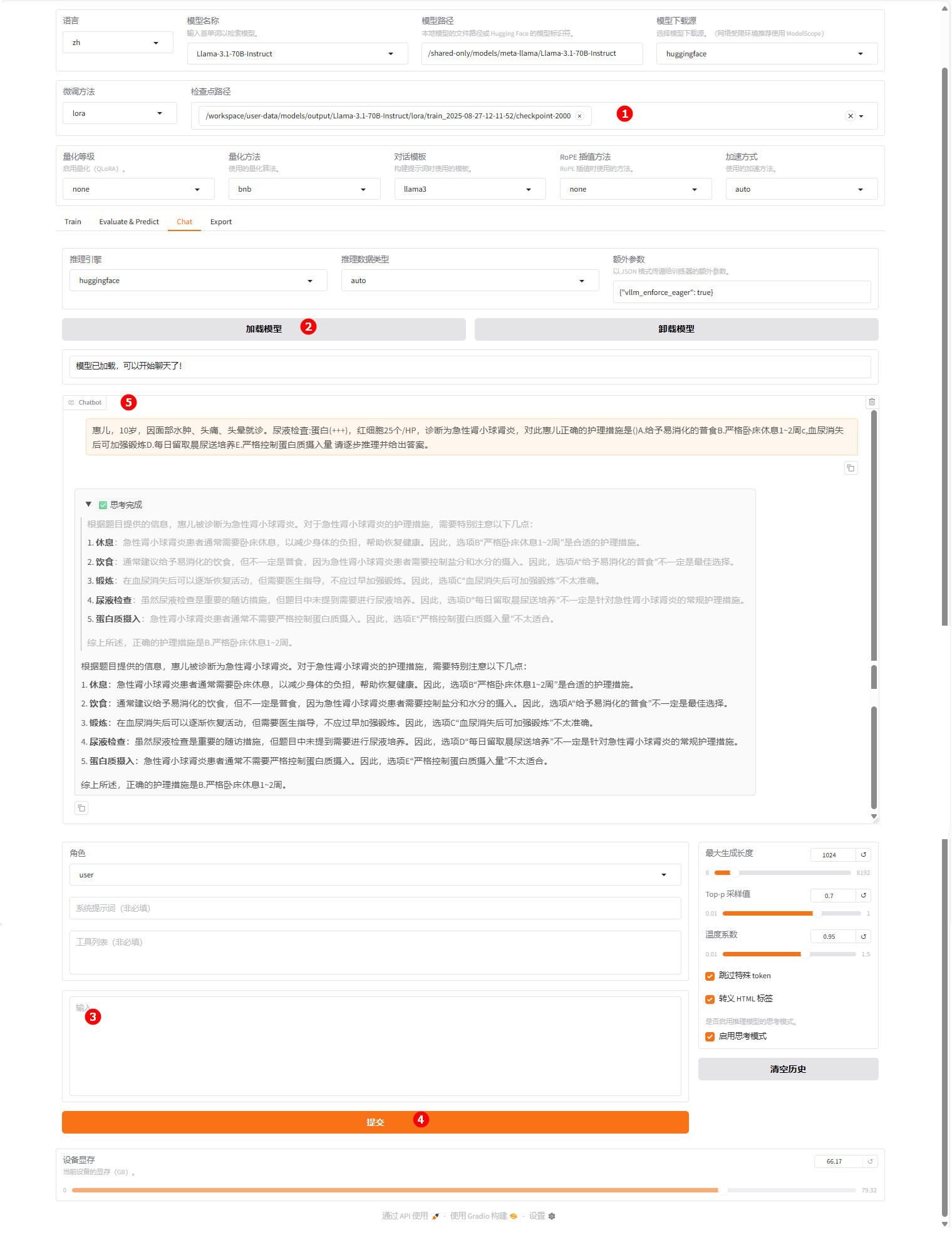
切换至“chat”界面,选择上一步骤已经训练完成的检查点路径,如下图高亮①所示;单击“加载模型”按钮(高亮②),微调的模型加载后,用户输入问题(高亮③)后,点击“提交”(高亮④),观察模型回答,如下图高亮⑤所示。
-
单击下图高亮①所示的“卸载模型”按钮,卸载微调后的模型,清空“检查点路径”中的LoRA配置(高亮②),单击“加载模型”按钮(高亮③),加载原生的
Llama-3.1-70B-Instruct模型进行对话,其余配置保持不变。用户在下图高亮④处输入同样的问题,点击“提交”(高亮⑤),观察模型回答,如下图高亮⑥所示。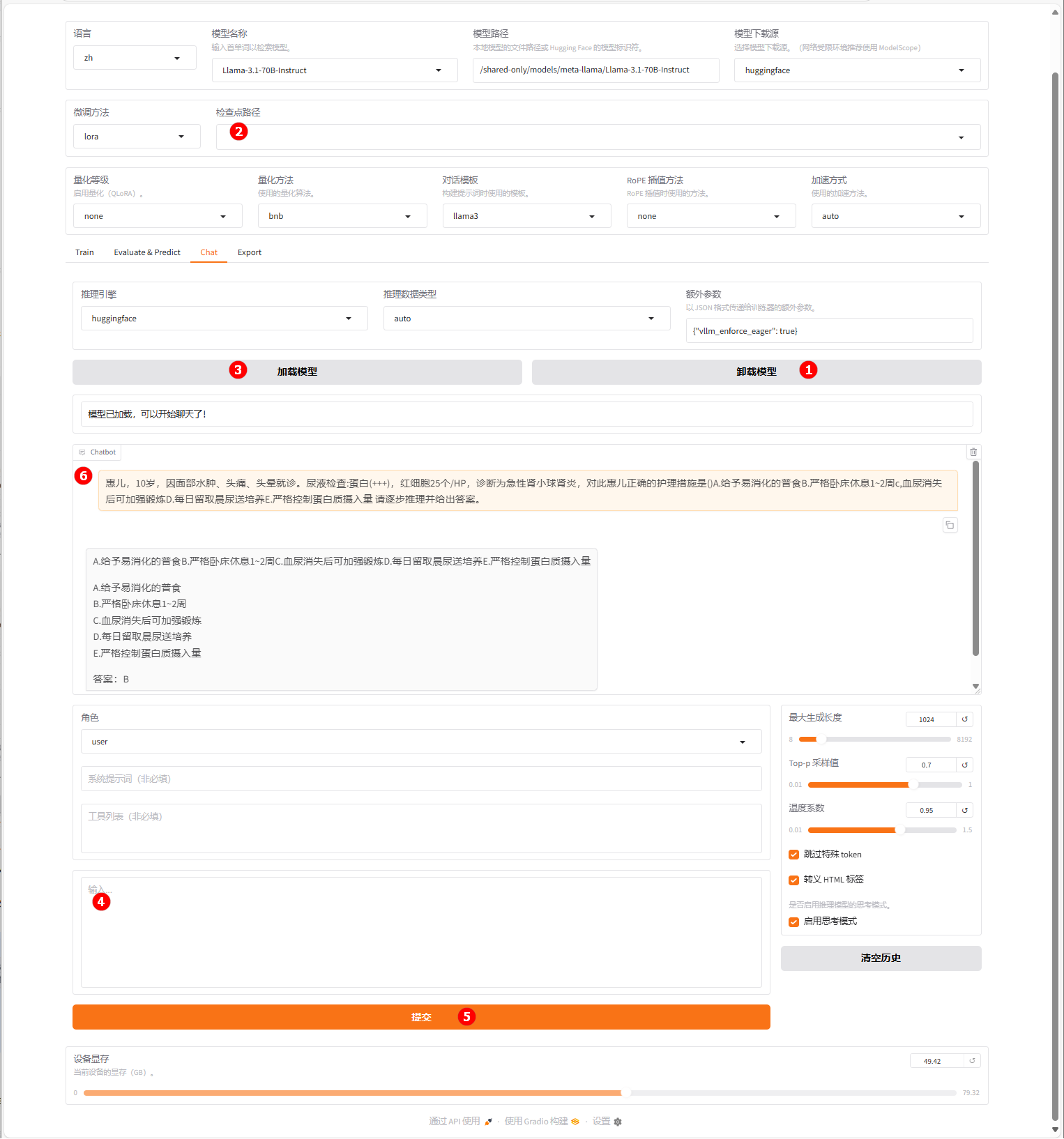
通过对比微调模型与原生模型的对话结果可以发现,微调后的模型按用户要求逐步分析题目信息和选项,最终给出正确选项。其回答条理清晰,简单明了。
-
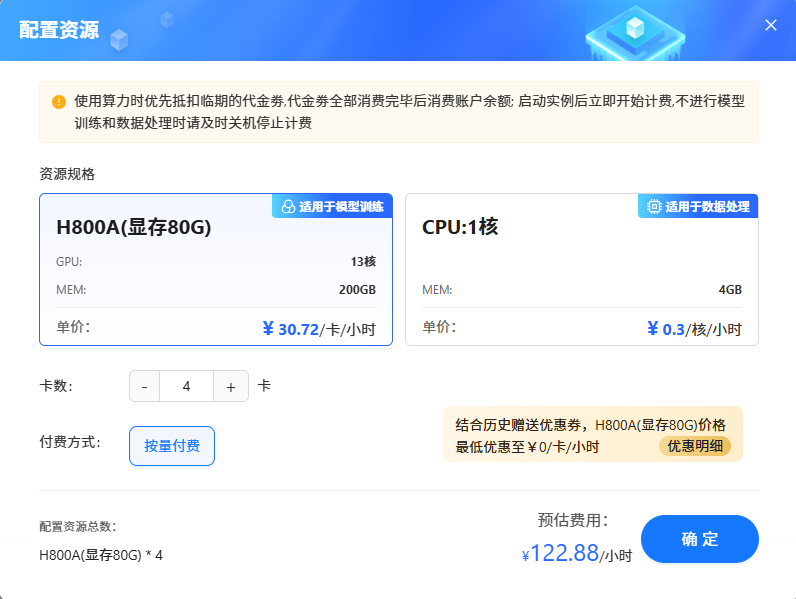
返回LlamaFactory Online平台的“实例空间”页面,点击页面右上角
 按钮重新设置GPU数量为4,如下图所示。然后点击页面右侧“JupyterLab处理专属数据”,进入jupyterlab工作空间。注意
按钮重新设置GPU数量为4,如下图所示。然后点击页面右侧“JupyterLab处理专属数据”,进入jupyterlab工作空间。注意目前LFO webUI不支持多卡评估,而70B模型单卡无法进行推断,所以需要在jupyterlab的终端内运行LlamaFactory项目中的vllm_infer.py脚本,进行分布式评估。
-
在
/workspace路径下新建一个文件夹,命名:medi_eval,用作存放评估相关的脚本和输出文件。
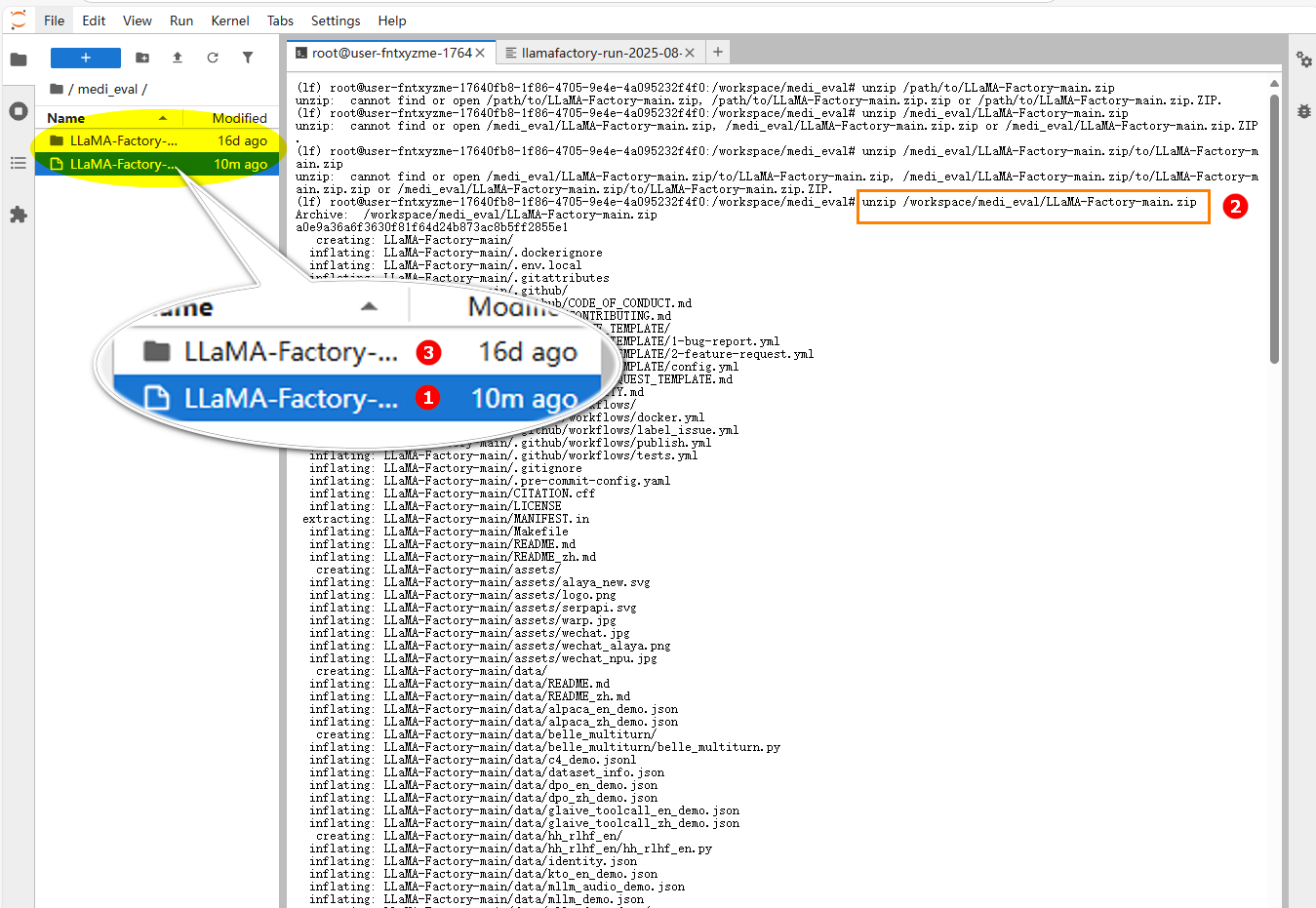
下载LLaMAFactory项目压缩包,拖到
medi_eval文件夹下,目录为/workspace/medi_eval。
点击jupyterlab页面的Terminal打开终端,使用下面的命令解压下载的压缩包。unzip /workspace/medi_eval/LLaMA-Factory-main.zip解压后如下图所示:高亮①处为上传的压缩包,高亮②处为解压的指令,高亮③处为解压后的文件夹。
-
生成评估案例及样本。
- 微调后模型评估
- 原生模型评估
打开jupyter notebook内的终端(Terminal),默认启动的环境名为lf。使用lf环境,运行下列vllm_infer.py的命令,开始进行模型评估样本的生成。
python /workspace/medi_eval/LLaMA-Factory-main/scripts/vllm_infer.py \
--model_name_or_path /shared-only/models/meta-llama/Llama-3.1-70B-Instruct \
--adapter_name_or_path /workspace/user-data/models/output/{your_checkpoint} \
--dataset_dir /workspace/llamafactory/data \
--dataset medical_o1_sft_Chinese_alpaca \
--template llama3 \
--cutoff_len 2048 \
--max_samples 500 \
--save_name /workspace/{your_save_name}.jsonl \
--temperature 0.1 \
--top_p 0.9 \
--top_k 40 \
--max_new_tokens 512 \
--repetition_penalty 1.1 \
--batch_size 8 \
--seed 42 \
--vllm_config '{"tensor_parallel_size": 4}'
请更改以下参数为自定义值。
adapter_name_or_path:{your_checkpoint}处填入需加载的checkpoint路径(如果对基模型进行评估,请勿传入这一参数)。本实践的checkpoint路径为:/workspace/user-data/models/output/Llama-3.1-70B-Instruct/lora/train_2025-08-27-12-11-52/checkpoint-2000 \
save_name: 微调后的模型生成的评估案例保存路径。 本实践的保存路径为:/workspace/llamafactory/evaluate_case_Llama-3.1-70B-Instruct.jsonl \
vllm_config: tensor_parallel_size的值与您启动实例时的GPU卡数一致。
出现如下图所示的输出,表示运行成功。
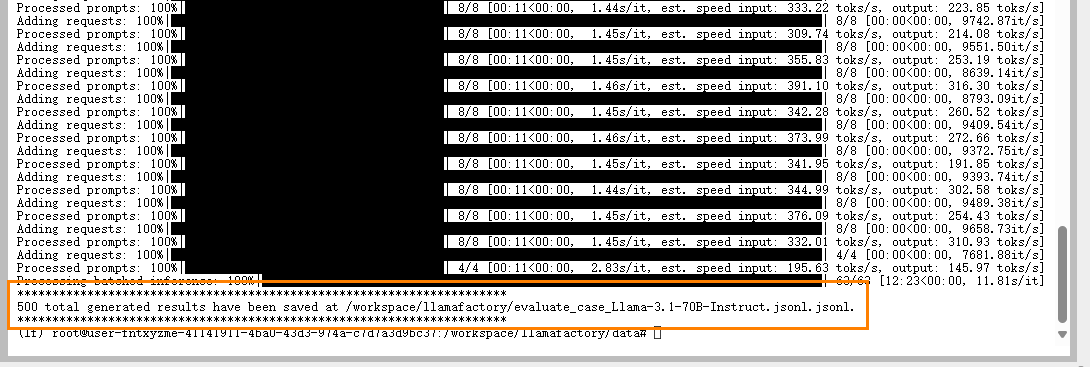
打开jupyter notebook内的终端(Terminal),默认启动的环境名为lf。使用lf环境,运行下列vllm_infer.py的命令,开始进行模型评估样本的生成。
python /workspace/medi_eval/LLaMA-Factory-main/scripts/vllm_infer.py \
--model_name_or_path /shared-only/models/meta-llama/Llama-3.1-70B-Instruct \
--dataset_dir /workspace/llamafactory/data \
--dataset medical_o1_sft_Chinese_alpaca \
--template llama3 \
--cutoff_len 2048 \
--max_samples 500 \
--save_name /workspace/{your_save_name}.jsonl \
--temperature 0.1 \
--top_p 0.9 \
--top_k 40 \
--max_new_tokens 512 \
--repetition_penalty 1.1 \
--batch_size 8 \
--seed 42 \
--vllm_config '{"tensor_parallel_size": 4}'
请更改以下参数为自定义值。
save_name: 微调后的模型生成的评估案例保存路径。 本实践的保存路径为:/workspace/llamafactory/evaluate_case__base_Llama-3.1-70B-Instruct.jsonl \
vllm_config: tensor_parallel_size的值与您启动实例时的GPU卡数一致。
出现如下图所示的输出,表示运行成功。
-
准备评估环境。 创建新环境,为评估模型做准备。
点击jupyterlab页面的
Terminal打开终端,创建新的python环境。(本实践中新环境命名为“evaluate”,python版本为"3.10")conda create -n evaluate python=3.10创建完成后,启动该环境。
conda activate evaluate安装指令评估所需要的python包。
pip install evaluate rouge-score nltk -i https://pypi.tuna.tsinghua.edu.cn/simple -
开始评估。
下载指标评估文件,拖拽到
/worksapace/medi_eval目录下。
在新建的“evaluate”环境中,运行以下指令进行评估。
- 微调后模型评估
- 原生模型评估
python medi_eval/70b_eval_metrics.py \
--pred_file {generated_predictions}.jsonl \
--output_metrics {metrics_save_name}.json注意修改以下参数值:
pred_file:评估案例保存的文件路径。本实践路径为:/workspace/llamafactory/evaluate_case_Llama-3.1-70B-Instruct.jsonl \
output_metrics:本次指令评估的结果保存路径。本实践路径为:/workspace/medi_eval/evaluate_result_Llama-3.1-70B-Instruct.jsonpython medi_eval/70b_eval_metrics.py \
--pred_file {generated_predictions}.jsonl \
--output_metrics {metrics_save_name}.json注意修改以下参数值:
pred_file:评估案例保存的文件路径。本实践路径为:/workspace/llamafactory/evaluate_case__base_Llama-3.1-70B-Instruct.jsonl \
output_metrics:本次指令评估的结果保存路径。本实践路径为:/workspace/medi_eval/evaluate_base_result_Llama-3.1-70B-Instruct.json -
评估结果如下所示。
- 微调后模型评估
- 原生模型评估
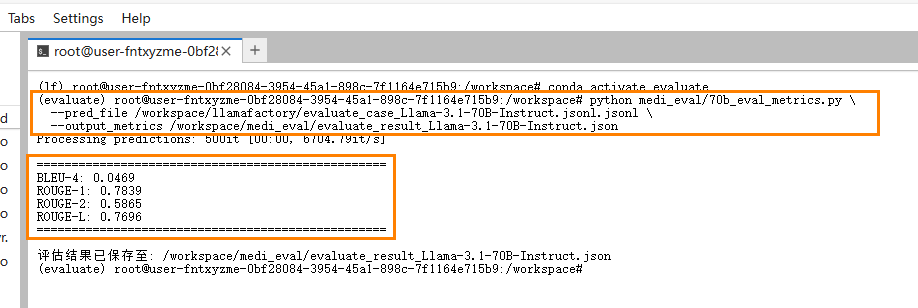
{
BLEU-4: 0.0469
ROUGE-1: 0.7839
ROUGE-2: 0.5865
ROUGE-L: 0.7696
}结果解读:模型生成结果与参考答案在整体内容和结构上较为接近(ROUGE分数高),但在字面和短语精确匹配上还有提升空间(BLEU分数较低)。模型适合生成内容覆盖面广、结构合理的文本,但字面一致性有待加强。
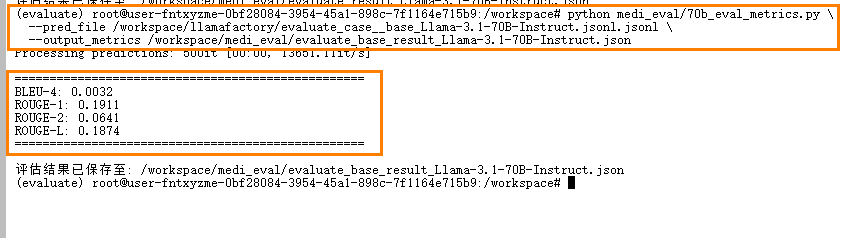
{
BLEU-4: 0.0032
ROUGE-1: 0.1911
ROUGE-2: 0.0641
ROUGE-L: 0.1874
}结果解读:这些分数均处于较低水平,表明当前模型生成内容与参考答案在词汇、短语和句子结构层面匹配度较差,语言流畅性和结构准确性不足,生成质量有待提升。原生模型在医疗诊断任务上的表现较弱,建议通过微调提升模型专业性和生成能力。
微调后模型在医疗诊断任务上的生成质量远高于原生模型,内容覆盖、结构合理性和语义连贯性均有明显提升,更适合实际医疗场景应用。
总结
用户可通过LlamaFactory Online平台预置的模型及数据集完成快速微调与效果验证。从上述实践案例可以看出,基于Llama3.1-70B-Instruct模型,采用LoRA方法在medical_o1_sft_Chinese_alpaca医学诊断数据集上进行指令微调后,模型医学诊断和临床决策领域的专业能力有显著提升。
本实践为构建高质量的医学诊断和临床决策系统提供了可复用的技术路径,适用于智能辅助工具、医学教育中的虚拟病例交互、患者健康咨询机器人等场景。未来可以使用实际业务数据集,对模型进行微调,得到能够解决医疗领域实际问题的本地化大模型。