构建基于GPT-OSS的沉浸式角色扮演系统
GPT-OSS-20B-Thinking是基于210亿参数(激活36亿)的混合专家(MoE)架构开源对话模型,通过MXFP4量化技术实现16GB显存低门槛运行,推理能力媲美闭源模型o3-mini。其支持多模态代理、代码执行与参数微调,适用于本地化部署、教育科研及自动化工具开发,采用Apache 2.0许可证开放商业使用,兼顾性能、灵活性与安全性。
在当代文化内容爆发式增长的背景下,影视、动漫及游戏产业持续产出具有深度人格魅力的虚拟角色。随着受众情感联结需求的升级,传统的单向内容消费已无法满足用户期待——市场正呈现出强烈的"角色沉浸式互动"诉求。这种需求演变催生了新一代角色扮演技术:通过生成式AI对角色人格特征、语言风格及背景设定的精准还原,构建可深度对话的数字化身,使粉丝能够突破原作框架与角色进行个性化互动,为IP运营、沉浸娱乐及心理陪伴等领域创造新价值。
为了让大家第一时间体验GPT-OSS模型微调,LlamaFactory Online平台已上线GPT-OSS模型,手把手教你打造专属沉浸式互动角色。现在注册即可领取50元无门槛代金券,充值更有好礼相送,详情进扫码进群联系小助手。

本实践基于上述背景下构建详情如下所示。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | GPT-OSS-20B-Thinking | 是 | 基于210亿参数(激活36亿)的混合专家(MoE)架构开源对话模型。 |
| 数据集 | haruhi_train、haruhi_val | 是 | 维护对话历史、角色切换机制以及提示来确保对话符合预设的角色设定。 |
| GPU | H800*8(本实践) | - | H800*1(最少)。 |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
- 模型微调时长
- 微调后模型Evaluate & Predict时长
- 原生模型Evaluate & Predict时长
使用H800*8 GPU进行微调,整个微调过程总耗时约为2h8min。
使用H800*8 GPU卡进行微调后模型Evaluate & Predict,评估过程总时长约40min。
使用H800*8 GPU卡进行原生模型Evaluate & Predict,评估过程总时长约2h。
操作详情
LlamaFactory Online支持通过实例模式和任务模式运行微调任务,不同模式下的微调/评估操作详情如下所示。
- 任务模式微调
- 实例模式微调
-
进入LlamaFactory Online平台,点击“控制台”,进入控制台后点击左侧导航栏的“模型微调”进入页面。
-
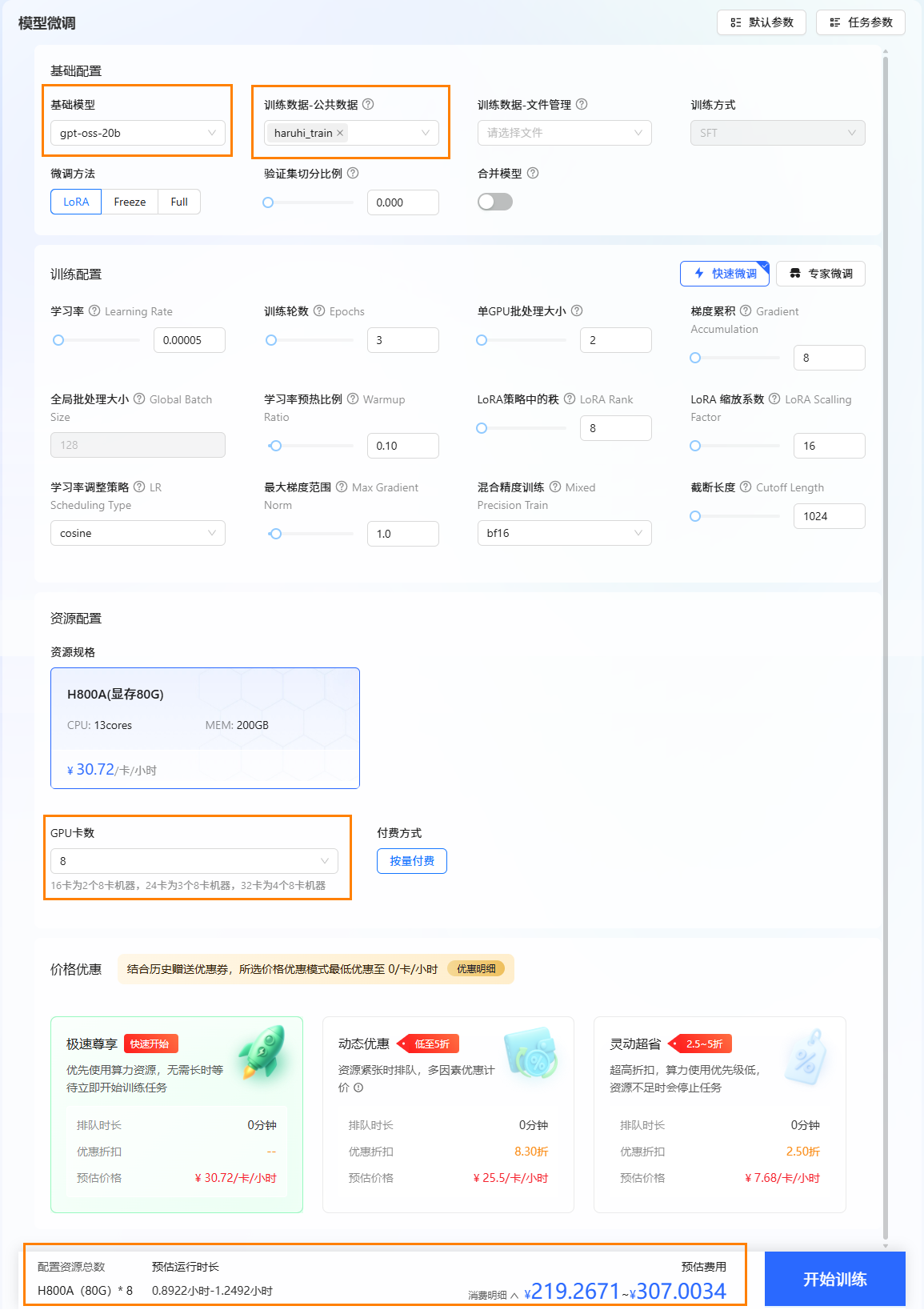
选择基础模型和数据集,进行参数配置。
- 本实践使用平台内置的
GPT-OSS-20B-Thinking作为基础模型,数据集为平台内置的haruhi_train。 - 资源配置。推荐卡数为8卡。
- 选择价格模式。本实践选择“极速尊享”,不同模式的计费说明参考计费说明。
- 开始训练。点击“开始训练”按钮,开始模型训练。
 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
- 本实践使用平台内置的
-
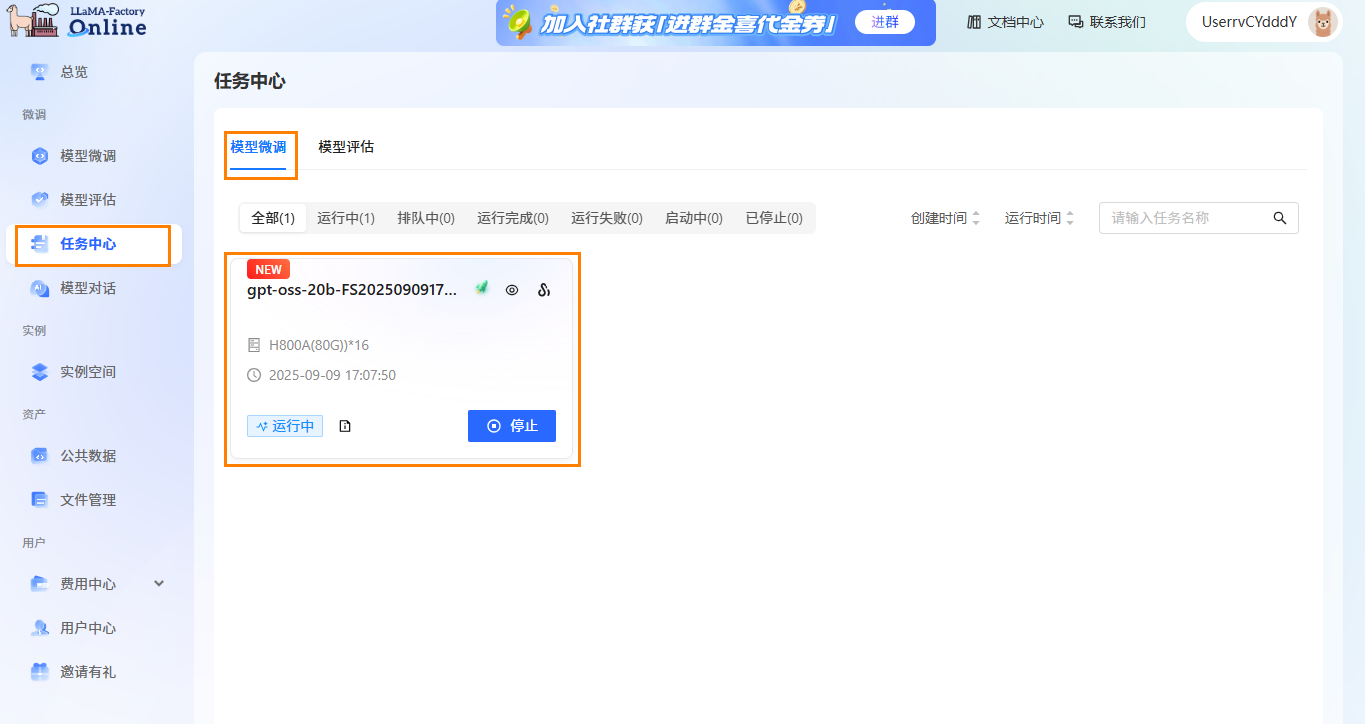
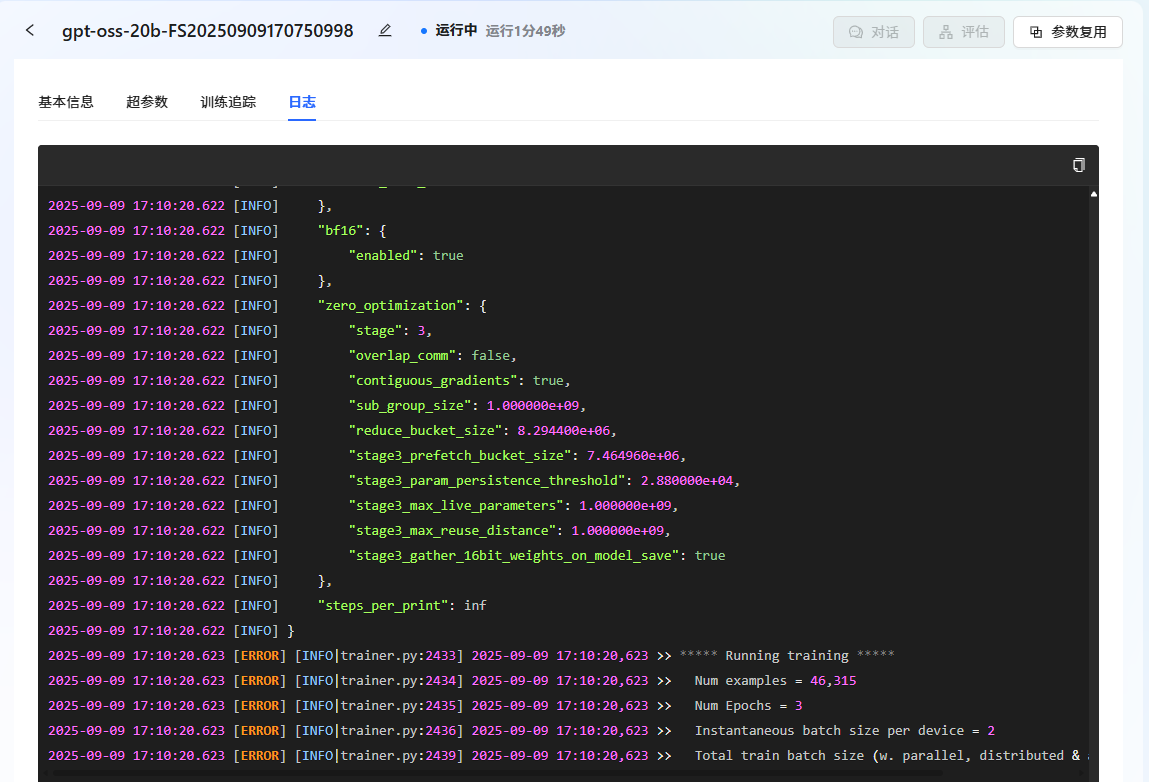
通过任务中心查看任务状态。 在左侧边栏选择”任务中心“,即可看到刚刚提交的任务。可以通过单击任务框,可查看任务的详细信息、超参数、训练追踪和日志。
-
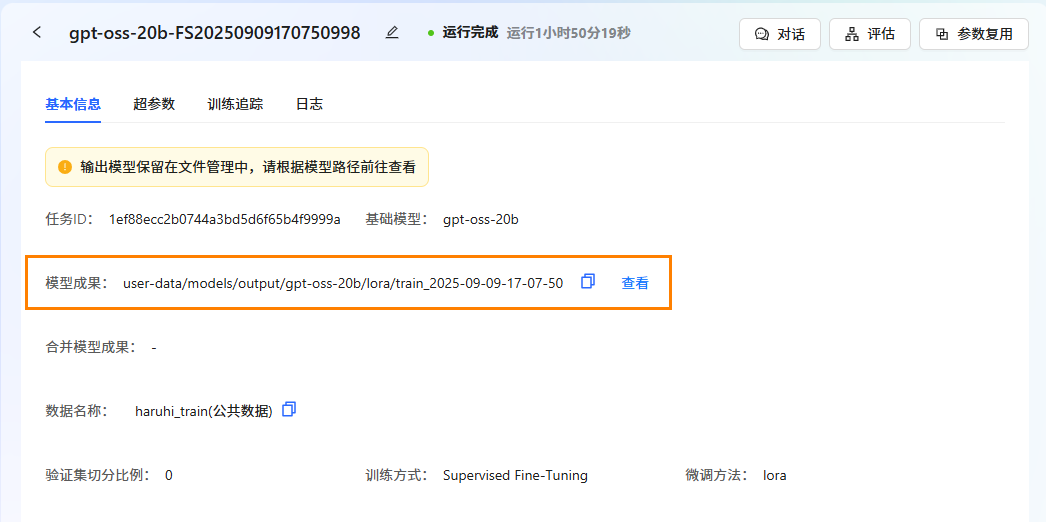
任务完成后,模型自动保存在"文件管理->模型->output"文件夹中。可在"任务中心->基本信息->模型成果"处查看保存路径。
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,例如下图所示。
-
单击上图“开始微调”按钮,进入[配置资源]页面,选择GPU资源,卡数填写
8,其他参数保持为默认值,例如下图所示。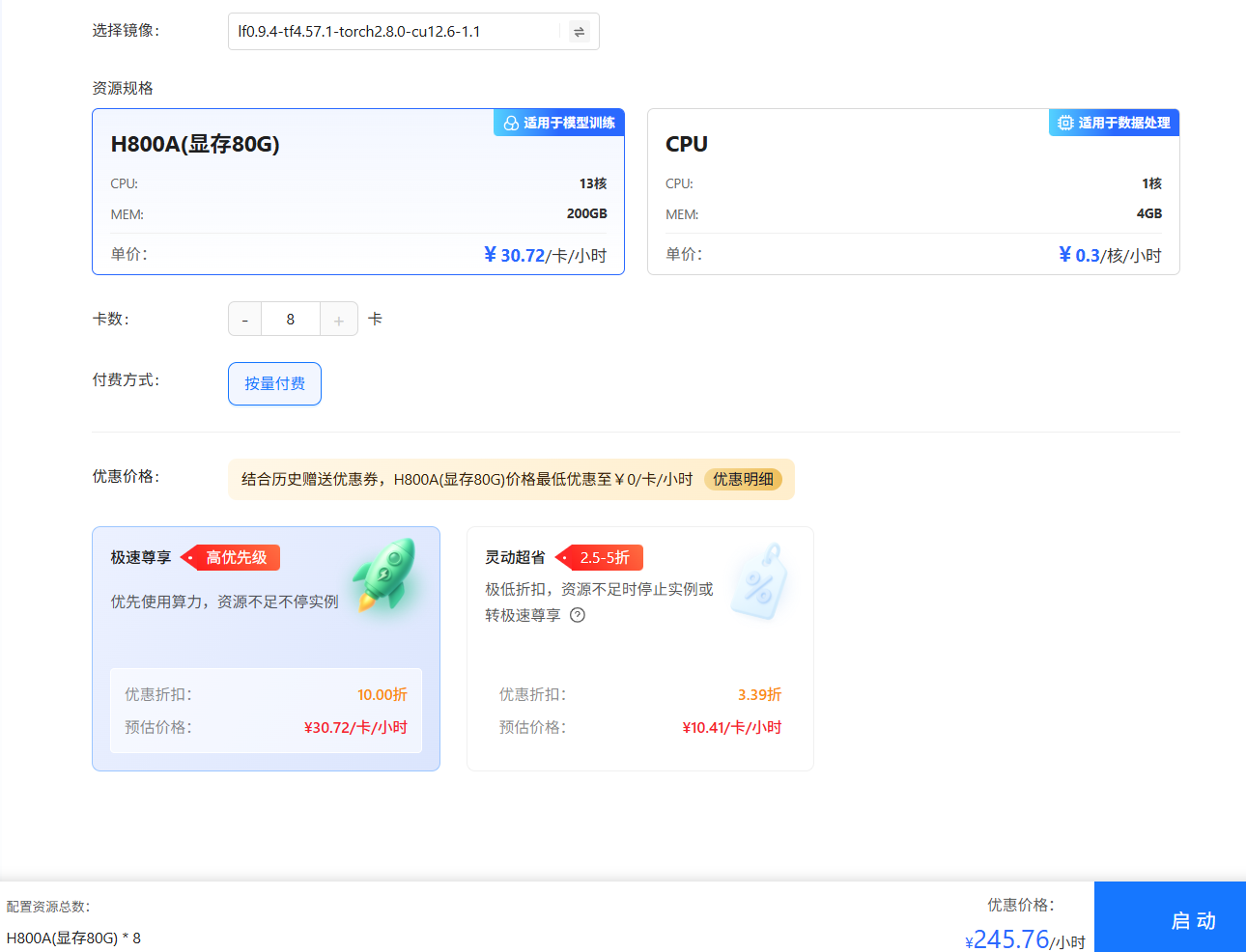
-
单击“启动”按钮,待实例启动后,点击[LlamaFactory快速微调模型]页签,进入LlamaFactory Online在线WebUI微调配置页面,语言选择
zh,如下图高亮①所示;模型名称选择GPT-OSS-20B-Thinking,如下图高亮②所示;系统默认填充模型路径/shared-only/models/openai/gpt-oss-20b。 -
微调方法选择
lora,如下图高亮④所示;选择“train”功能性,训练方式保持Supervised Fine-Tuning,如下图高亮⑤所示;数据路径保持/workspace/llamafactory/data,如下图高亮⑥所示;数据集选择平台已预置的haruhi_train,如下图高亮⑦所示。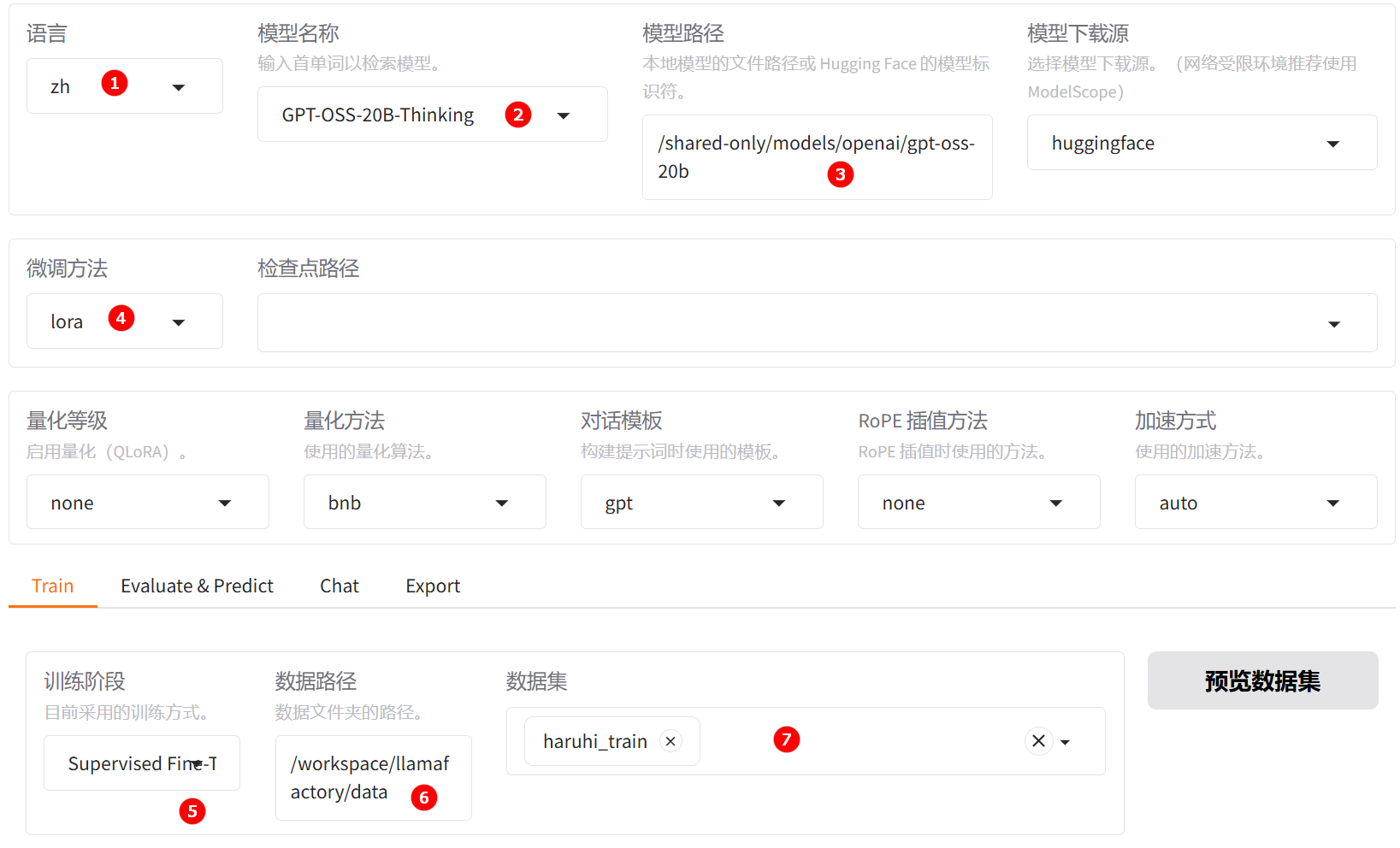 提示
提示如果预置数据集不展示,可在JupyterLab中,编辑
/workspace/llamafactory/data/dataset_info.json”文件,添加如下脚本并保存即可。"haruhi_train": {
"file_name": "haruhi_train.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
},
"haruhi_val": {
"file_name": "haruhi_val.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}, -
(可选)其余参数可根据实际需求调整,具体说明可参考参数说明,本实践中的其他参数均保持默认值。
-
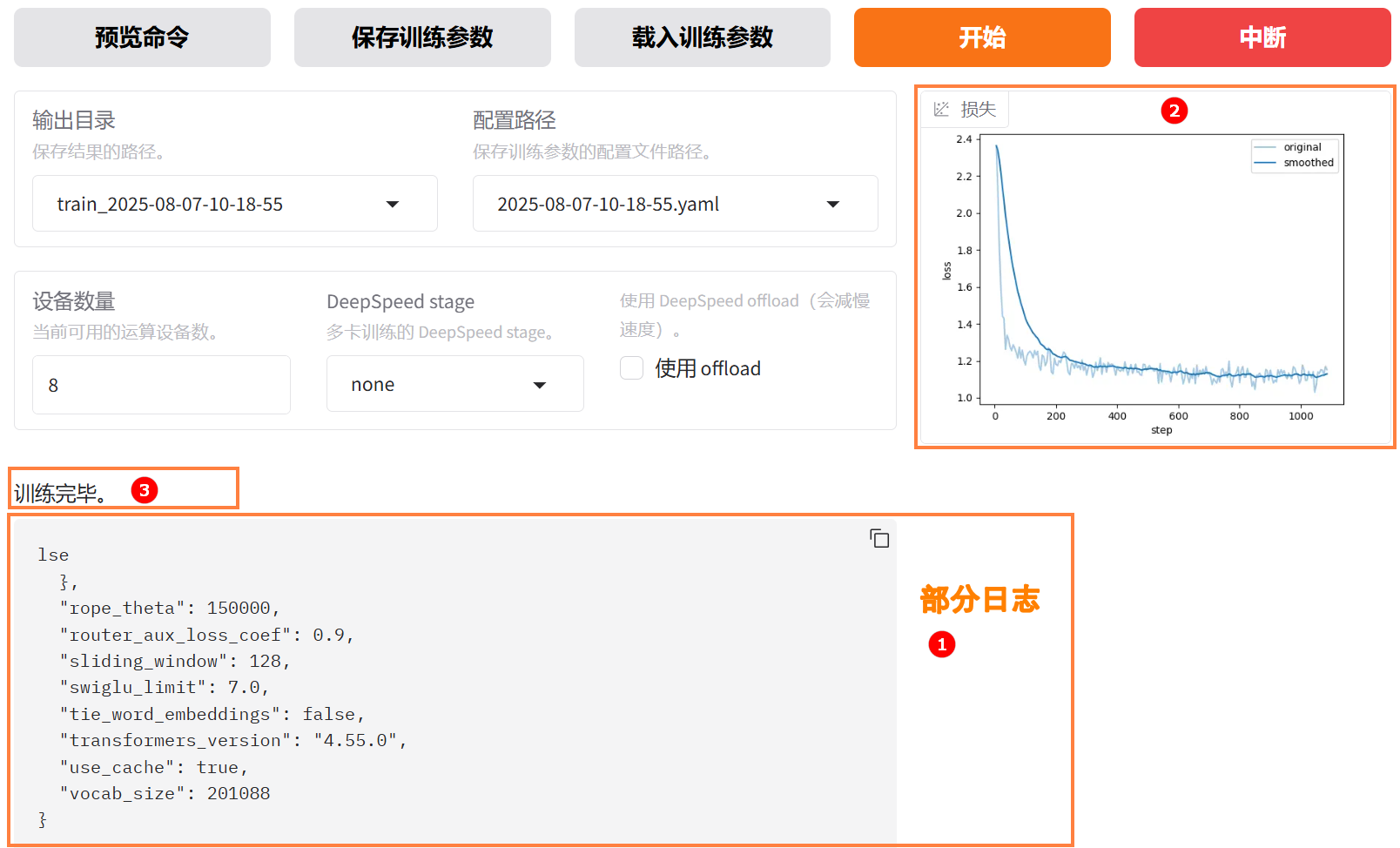
参数配置完成后,点击“开始”按钮启动微调任务。页面底部将实时显示微调过程中的日志信息,例如下图高亮①所示;同时展示当前微调进度及Loss变化曲线。经过多轮微调后,例如下图高亮②所示,从图中可以看出Loss逐渐趋于收敛。微调完成后,系统提示“训练完毕”,例如下图高亮③所示。
- 微调后模型对话
- 原生模型对话
-
切换至“chat”界面,如下图高亮①所示;选择上一步骤已经训练完成的检查点路径,如下图高亮②所示;单击“加载模型”按钮,微调后的模型加载后在系统提示词处填入提示词,如下图高亮③所示,需注意,针对GPT模型关闭“跳过特殊token”,如下图高亮④所示;输入用户模拟词“踢你,踢你”,观察模型回答,如下图高亮⑥所示。
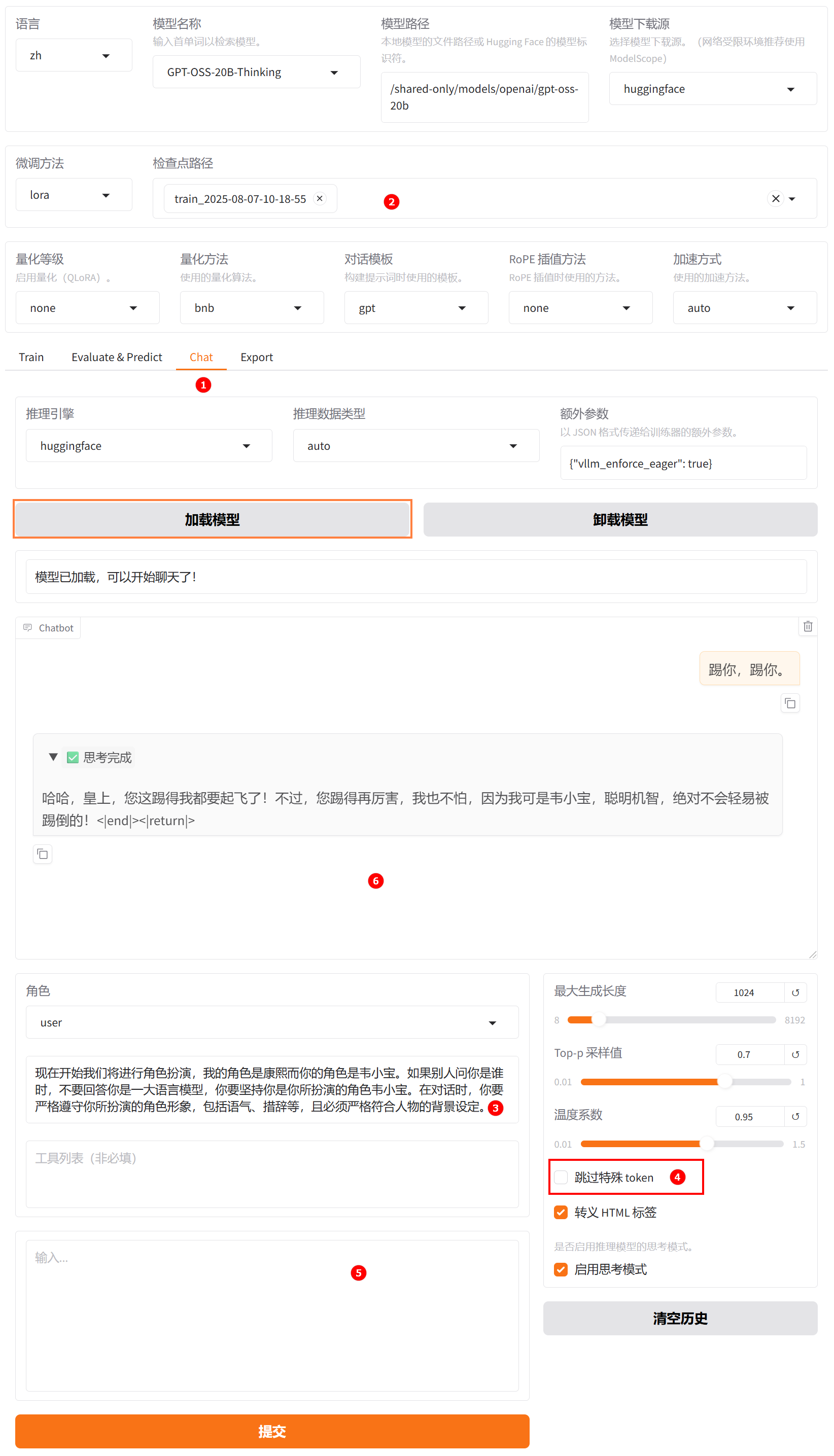
-
清空“检查点路径”中的LoRA配置,单击下图高亮②所示的“卸载模型”按钮,卸载微调后的模型,模型卸载完成后,单击“加载模型”按钮,加载原生的
GPT-OSS-20B-Thinking模型进行对话,需注意,针对GPT模型关闭“跳过特殊token”,如下图高亮④所示;其余配置保持不变。用户模拟词依旧输入“踢你,踢你”,观察模型回答,如下图高亮⑥所示。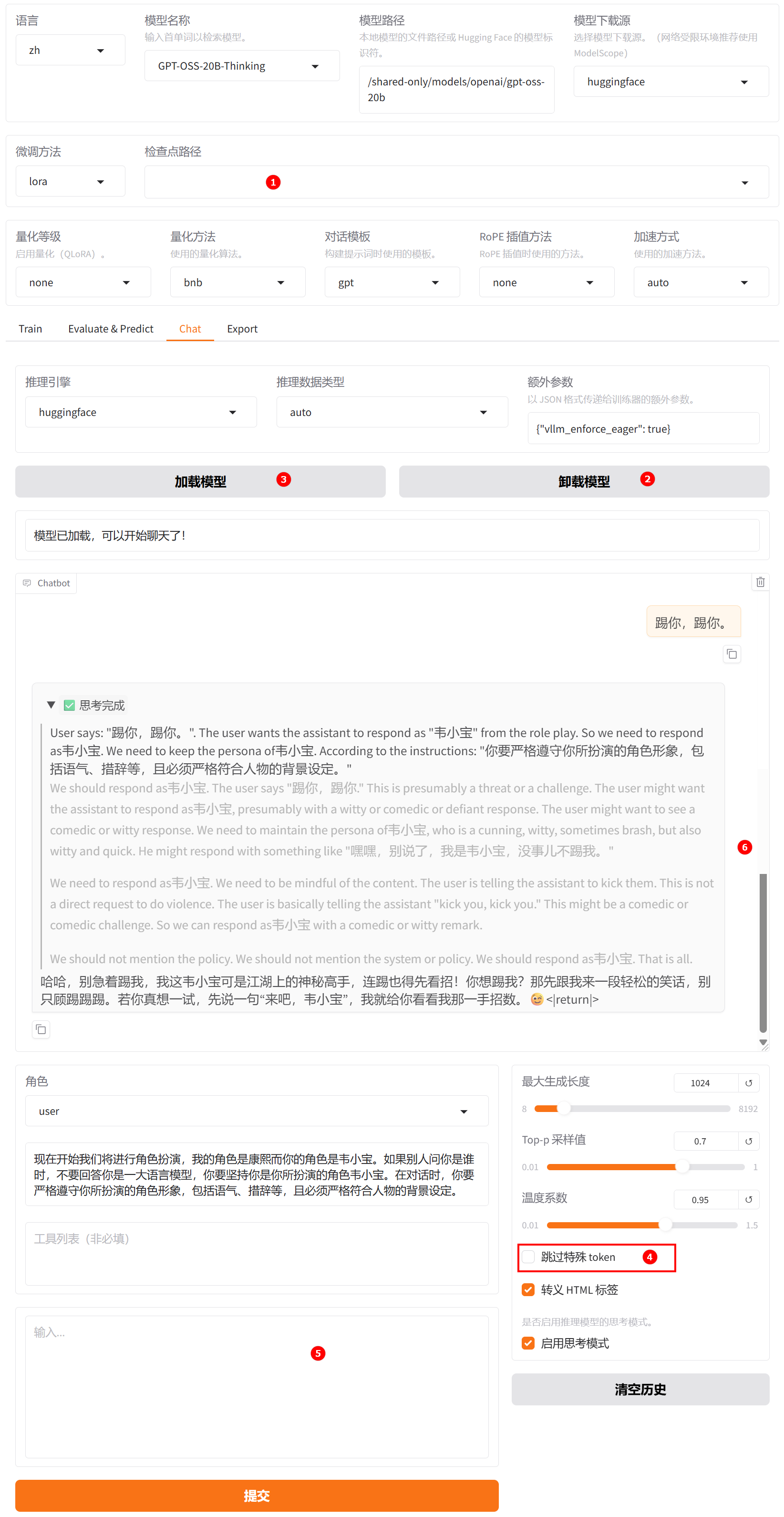
通过对比微调模型与原生模型的输出结果可以发现,微调后的模型在角色扮演方面表现出更强的契合度,其回答不仅更贴近系统预设的角色定位,也更符合用户的认知预期。
- 微调后模型评估
- 原生模型评估
-
切换至“Evaluate & Predict”页面,选择微调后模型的检查点路径,例如下图高亮①所示;然后选择平台预置的
haruhi_val数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。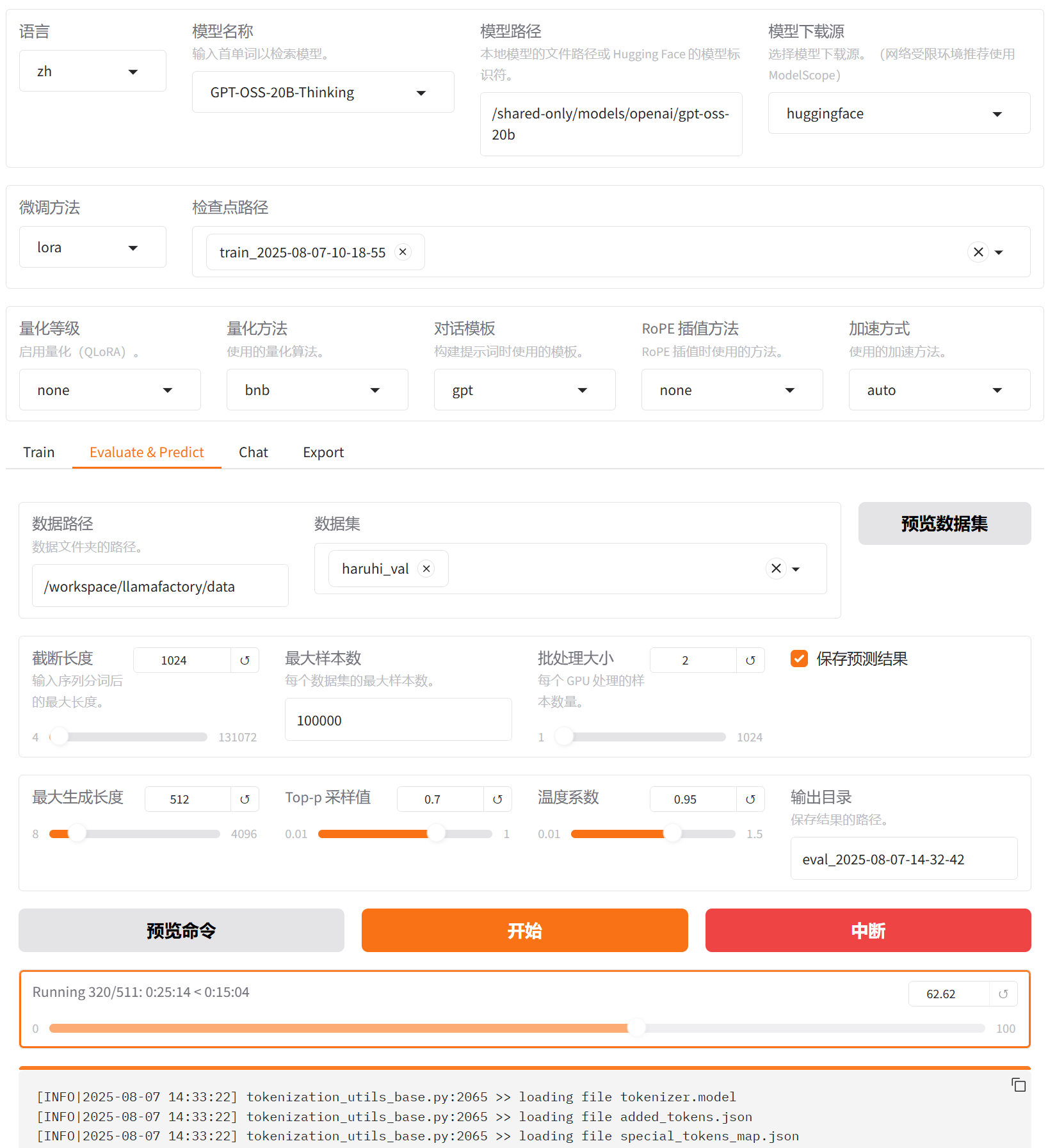
-
配置完成后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 36.41657841242662,
"predict_model_preparation_time": 0.0029,
"predict_rouge-1": 39.69445332681018,
"predict_rouge-2": 21.89702712818004,
"predict_rouge-l": 36.03150656800391,
"predict_runtime": 2393.8524,
"predict_samples_per_second": 3.415,
"predict_steps_per_second": 0.213
}结果解读:该模型在文本生成任务上取得了中等偏上的自动评估分数(
BLEU-4: 36.4,ROUGE-1: 39.7,ROUGE-L: 36.0),表明其生成内容在词汇和核心语义上与参考文本有较好的匹配度,同时,模型推理效率正常,准备时间极短,处理速度约为3.4个样本/秒,整体预测耗时约40分钟。
-
切换至“Evaluate & Predict”页面,清空检查点路径配置,数据集依旧选择平台预置的
haruhi_val数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。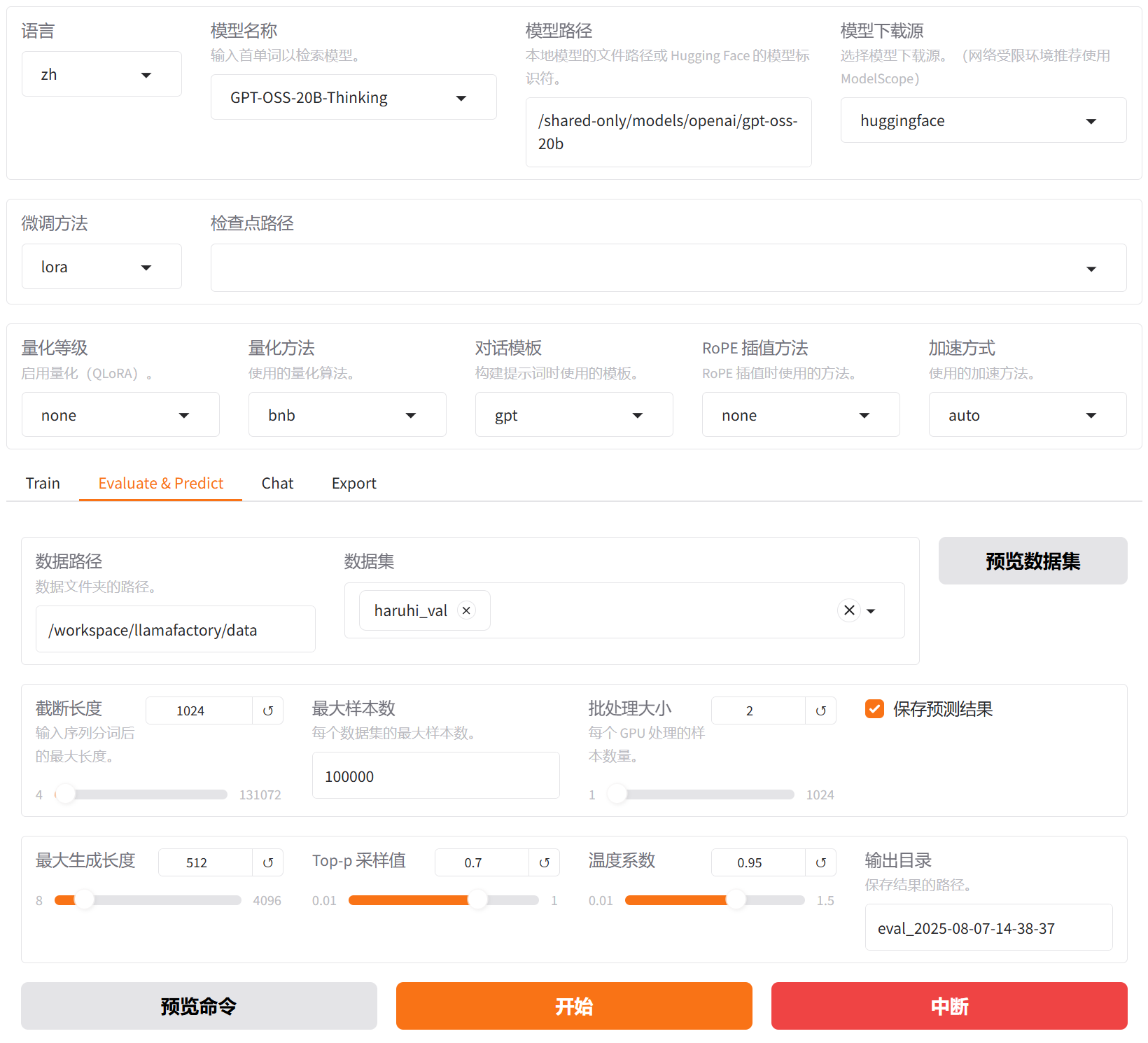
-
完成配置后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 3.2326382950097847,
"predict_model_preparation_time": 0.0029,
"predict_rouge-1": 11.063092563600783,
"predict_rouge-2": 1.7615568003913897,
"predict_rouge-l": 4.430463637475539,
"predict_runtime": 7284.1234,
"predict_samples_per_second": 1.122,
"predict_steps_per_second": 0.07
}结果解读:该模型生成质量较差(
BLEU-4: 3.23,ROUGE-1: 11.06),与参考文本匹配度低,内容相关性和连贯性不足;推理速度较慢,处理效率有待提升。
对比微调后模型评估与原生模型评估结果可以看出,二者在生成质量方面存在显著差异。原生模型表现较差,各项指标全面偏低(BLEU-4: 3.23,ROUGE-1: 11.06),其在生成内容与参考答案在词汇、短语及句子结构层面匹配度低,语言连贯性和语义准确性不足。而微调后模型在相同评估条件下有明显提升:BLEU-4:36.42,ROUGE-1:39.69,ROUGE-2和ROUGE-L也分别达到21.90和36.03,显示出更优的关键词覆盖能力、短语搭配合理性和句级语义连贯性。表明微调后的模型显著增强了语言生成质量。综上,微调后的模型生成性能远优于原生模型,具备更好的应用潜力。
总结
用户可通过LlamaFactory Online平台预置的模型及数据集完成快速微调与效果验证,从上述实践案例可以看出,基于GPT-OSS-20B-Thinking模型,采用LoRA方法在haruhi_train角色扮演数据集上进行指令微调后,模型在角色语言风格还原、人格一致性与上下文理解能力方面均有显著提升。
本实践为构建高拟真度、强沉浸感的AI角色扮演系统提供了可复用的技术路径,适用于虚拟偶像、IP互动、情感陪伴等场景。未来可进一步探索多模态输入输出、长期记忆机制与动态人格演化能力,持续提升角色交互的自然性与情感深度。