设立基于Llama-3-8B-Instruct的数据分析新基准
近年来,大语言模型(LLMs)在数学、物理、化学等多个科学领域展现出了令人印象深刻的能力。然而,它们在复杂数据分析任务方面的表现尚未被系统性评估。为弥补这一研究空白,论文[1]提出了一个新基准StatQA(维度有:数据分析任务的全面性和难度、易于进行LLM数据分析能力的评估、高数据品质,且低人力消耗(自动化构造数据集、可延展性),用以测评LLM在统计分析任务上的能力与方法适用性判断能力。
本实践通过对Llama-2-7B、Llama-3-8B和Llama-3-8B-Instruct模型进行微调,得到三次实验的checkpoint,观察同个评估题模型回答情况与Ground Truth差异。
[1]论文:点击链接可查看论文详情。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Llama-2-7B、Llama-3-8B、Llama-3-8B-Instruct | 是 | 本实践基于多模型微调。 |
| 数据集 | 训练数据集:D_train_ft_train.json 评估数据集:mini-StatQA_ft_test.json | 是 | 基于开源数据集进行微调及评估。 |
| GPU | H800*4(推荐) | - | H800*2(最少)。 |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
- Llama-2-7B
- Llama-3-8B
- Llama-3-8B-Instruct
- Llama-3-8B-Instruct原生模型
时长
使用推荐资源(H800*4)进行原生模型Evaluate & Predict,评估过程总时长约13min。
操作详情
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,例如下图所示。
-
单击上图“开始微调”按钮,进入[配置资源]页面,选择GPU资源,卡数填写
4,其他参数保持为默认值,例如下图所示。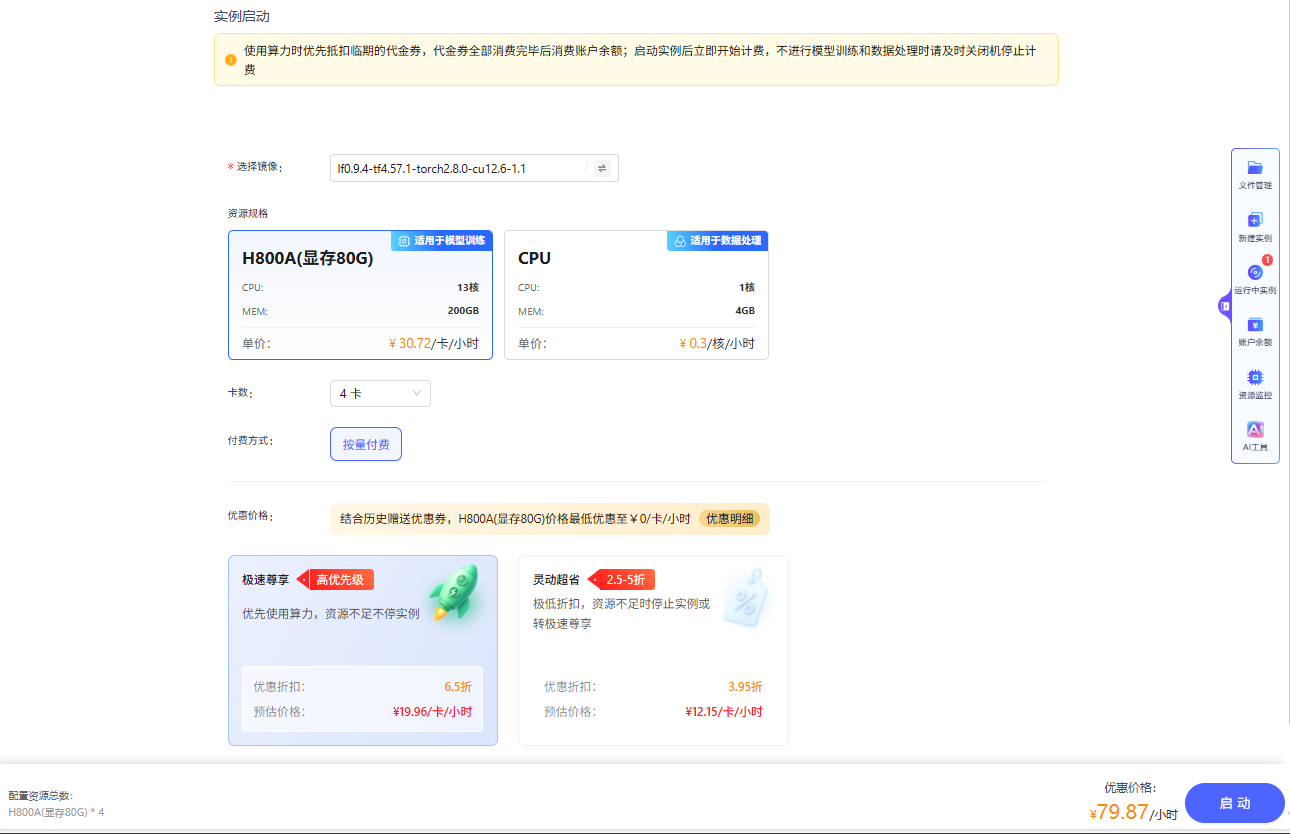
-
单击“启动”按钮,待实例启动后,点击[LlamaFactory快速微调模型]页签,进入LlamaFactory Online在线WebUI微调配置页面,各模型配置如下图所示。
- Llama-2-7B微调
- Llama-3-8B微调
- Llama-3-8B-Instruct微调
语言选择zh,如下图高亮①所示;模型名称选择Llama-2-7B,如下图高亮②所示;系统默认填充模型路径/shared-only/models/meta-llama/Llama-2-7b,数据集选择D_train_ft_train,如下图高亮④所示。

语言选择zh,模型名称选择Llama-3-8B,系统默认填充模型路径/shared-only/models/meta-llama/Meta-Llama-3-8B。
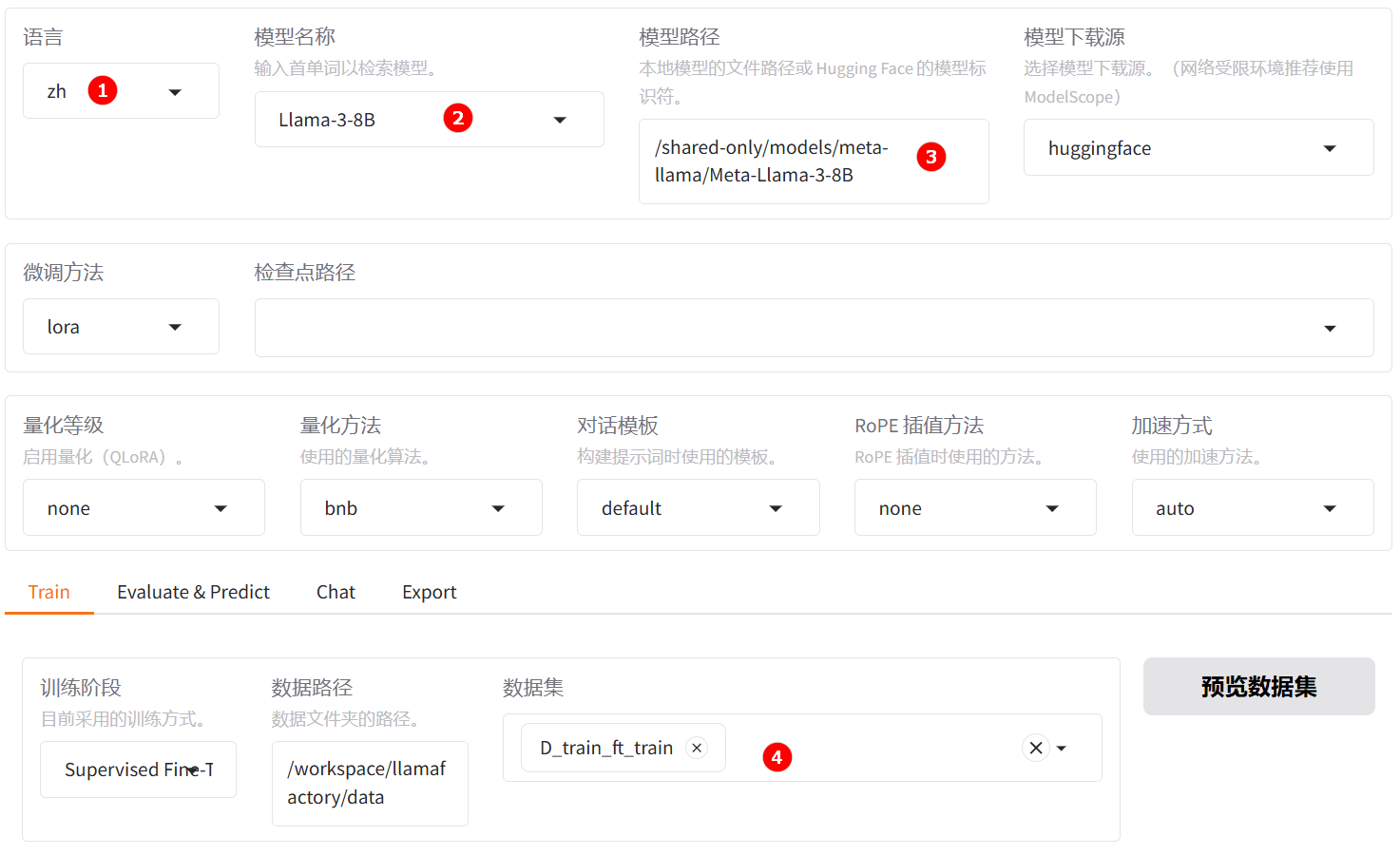
语言选择zh,模型名称选择Llama-3-8B-Instruct,系统默认填充模型路径/shared-only/models/meta-llama/Meta-Llama-3-8B-Instruct。

-
(可选)其余参数可根据实际需求调整,具体说明可参考参数说明,本实践中的其他参数均保持默认值。
-
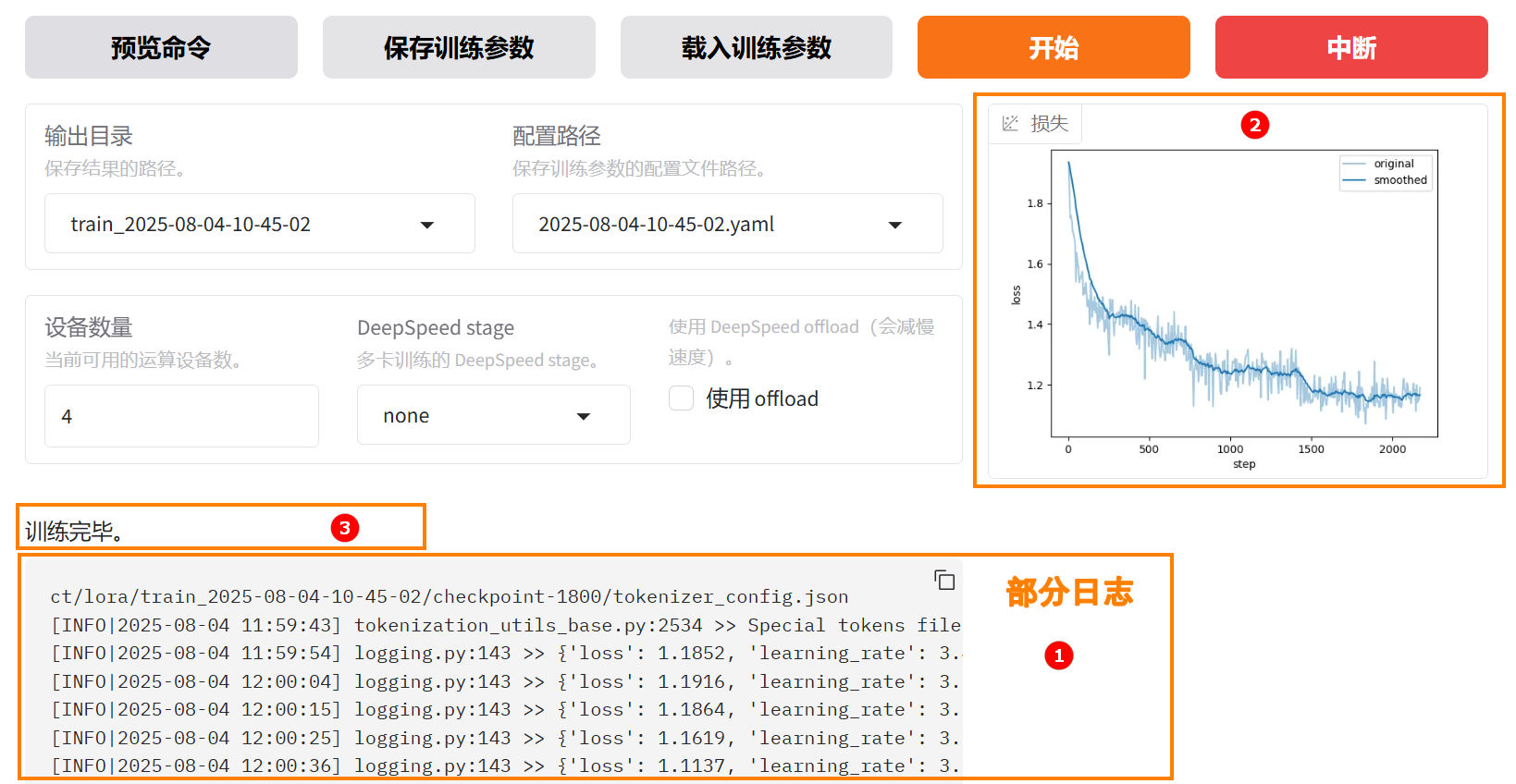
参数配置完成后,点击“开始”按钮启动微调任务。页面底部将实时显示微调过程中的日志信息,例如下图高亮①所示;同时展示当前微调进度及Loss变化曲线。经过多轮微调后,例如下图高亮②所示,从图中可以看出Loss逐渐趋于收敛。微调完成后,系统提示“训练完毕”,例如下图高亮③所示。
- Llama-2-7B微调后模型评估
- Llama-3-8B微调后模型评估
- Llama-3-8B-Instruct原生模型评估
- Llama-3-8B-Instruct微调后模型评估
-
切换至“Evaluate & Predict”页面,选择微调后模型的检查点路径,例如下图高亮①所示;然后选择平台预置的
mini-StatQA_ft_test数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。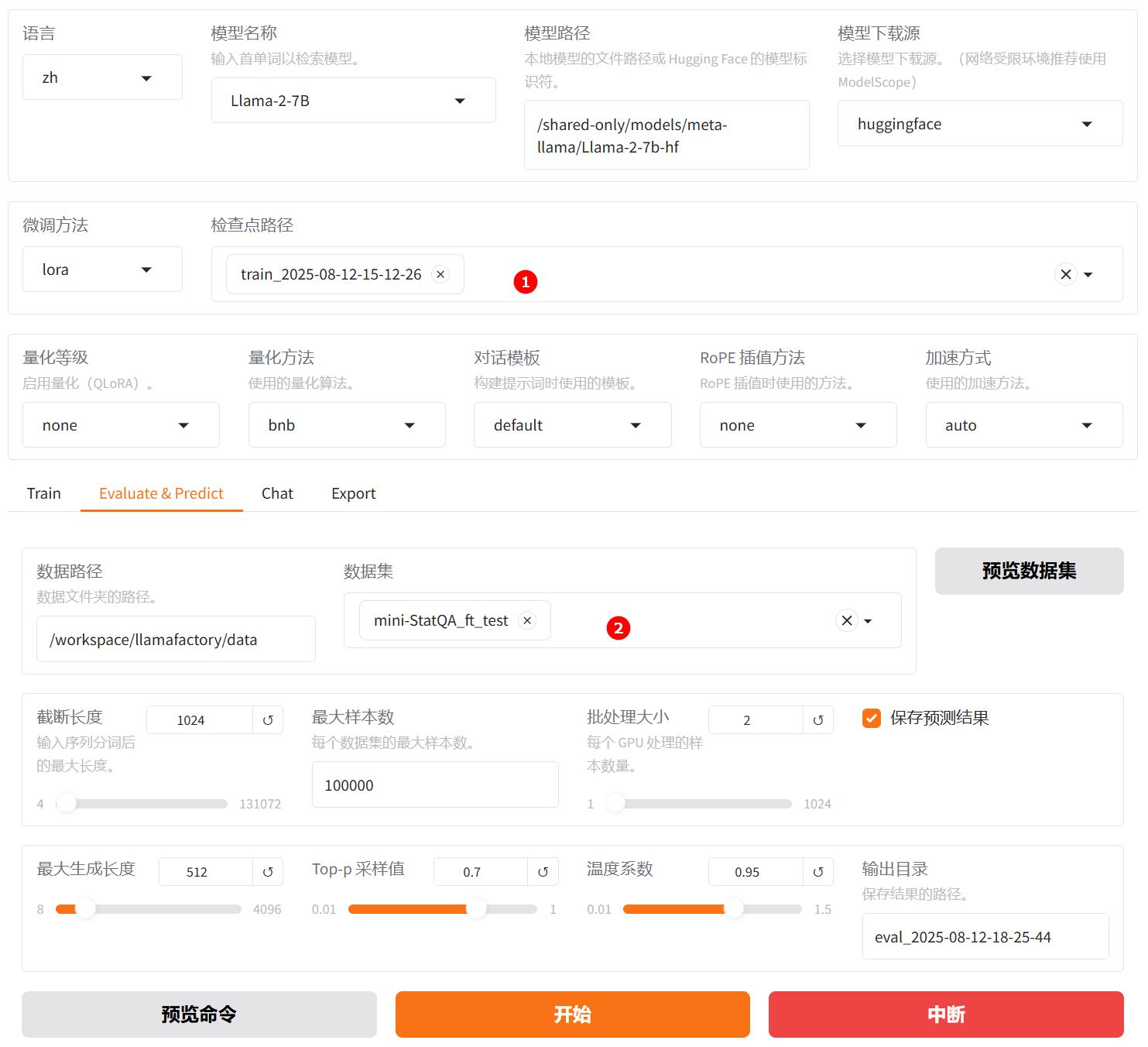
-
参数配置完成后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,系统自动记录评估结果。
-
切换至“Evaluate & Predict”页面,选择微调后模型的检查点路径,例如下图高亮①所示,数据集依旧选择平台预置的
mini-StatQA_ft_test数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。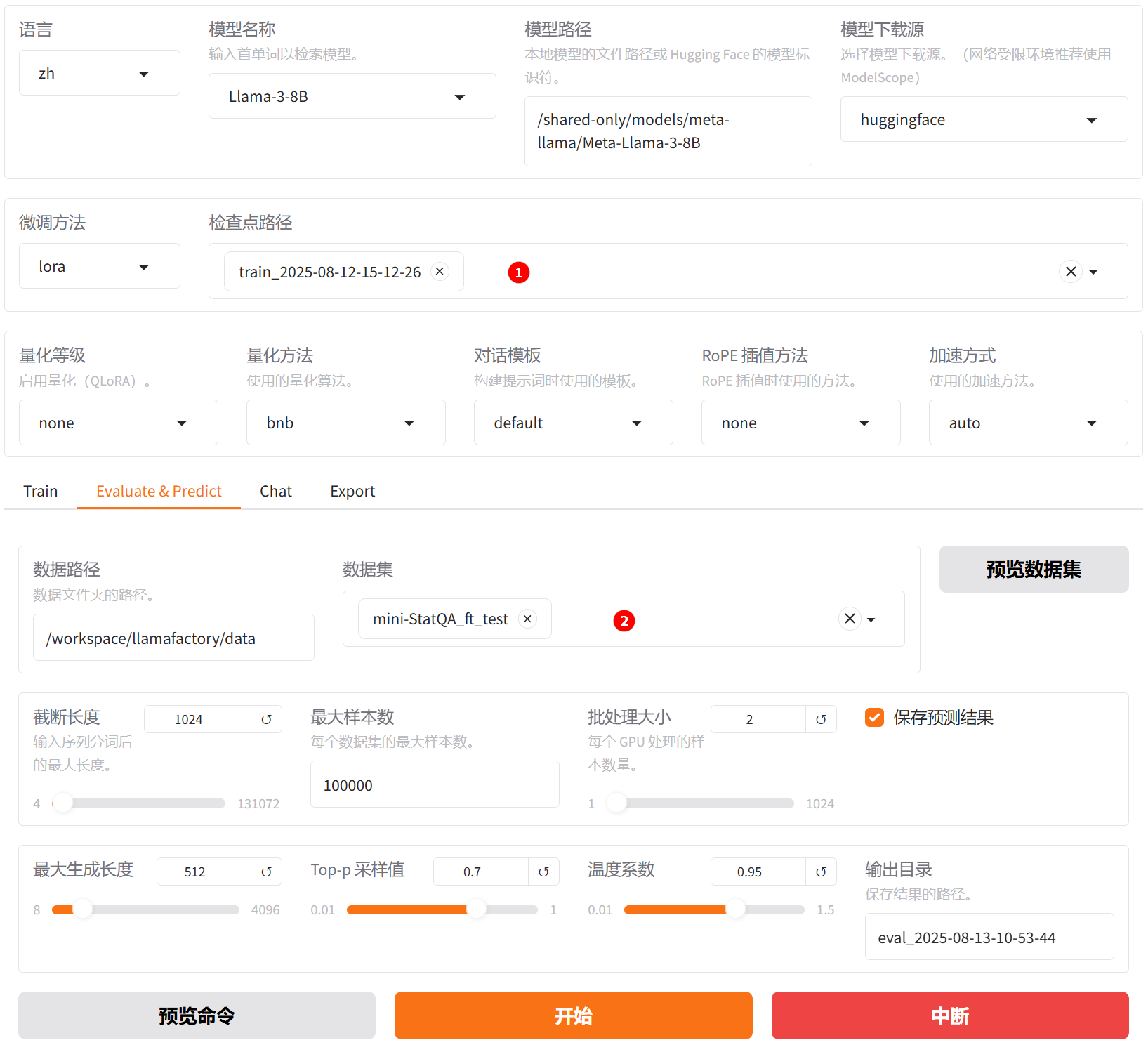
-
完成配置后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,系统自动记录评估结果。
-
切换至“Evaluate & Predict”页面,清除检查点路径,例如下图高亮①所示,数据集依旧选择平台预置的
mini-StatQA_ft_test数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。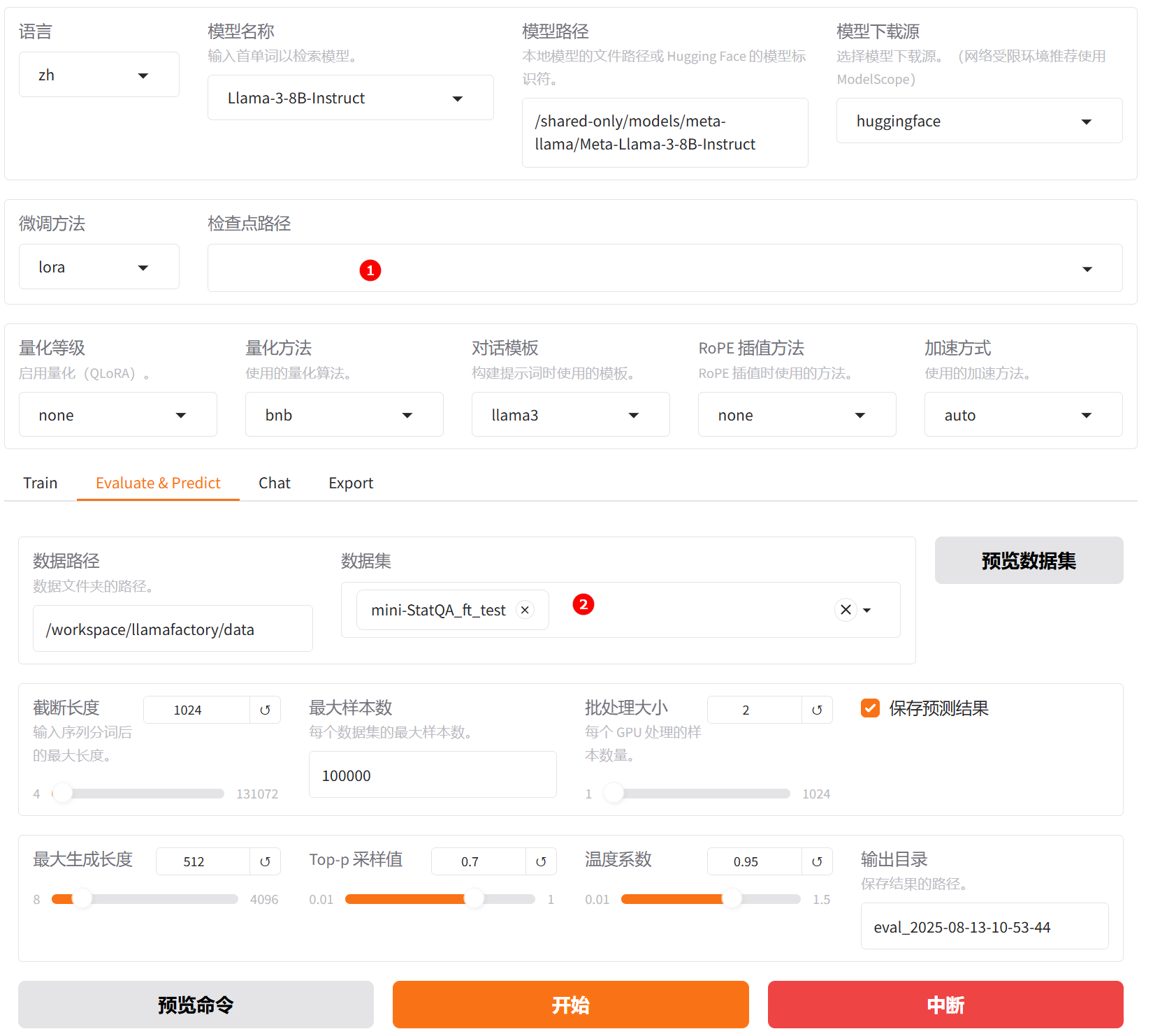
-
完成配置后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,系统自动记录评估结果。
-
切换至“Evaluate & Predict”页面,选择微调后模型的检查点路径,例如下图高亮①所示,数据集依旧选择平台预置的
mini-StatQA_ft_test数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。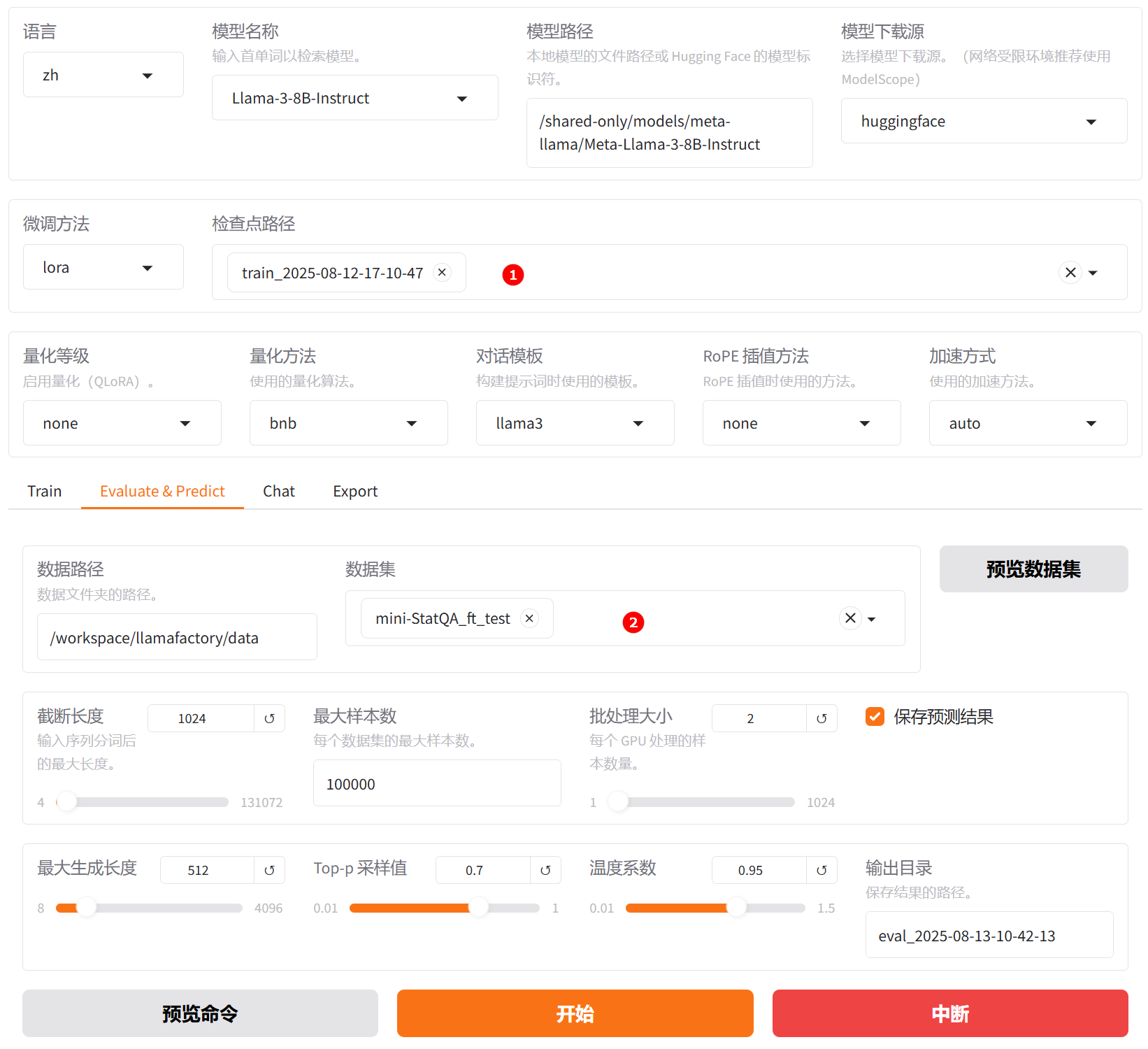
-
完成配置后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,系统自动记录评估结果。
评估完成后,结果将输出至JupyterLab的user-data/model/output目录下对应模型的路径中。例如,评估文件夹可能命名为:eval_2025-08-12-18-25-44。在该文件夹内,打开generated_predictions.jsonl文件即可查看模型微调后的预测结果。
评估完成后,在generated_predictions.jsonl文件中查看模型针对Refined Question生成的答案,将其与Ground Truth进行对比,分析差异。详情如下表所示。
| Title | Detail |
|---|---|
| Dataset | Crop Production Dataset |
| Refined Question | Are the variations in yearly crop yields similar in Japan and Brazil? |
| Relevant Column | [{\"column_header\": \"Japan\", \"is_strata\": false, \"is_control\": false}, {\"column_header\": \"Brazil\", \"is_strata\": false, \"is_control\": false}] |
| Results | [{\"method\": \"Mood Variance Test\", \"result\": \"{\\\"stat\\\": 0.86603, \\\"p value\\\": 0.38648}\", \"conclusion\": \"Variance not significantly difference between them\"}, {\"method\": \"Levene Test\", \"result\": \"{\\\"stat\\\": 0.0424, \\\"p value\\\": 0.84366}\", \"conclusion\": \"Variance not significantly difference between them\"}, {\"method\": \"Bartlett Test\", \"result\": \"{\\\"stat\\\": 0.14323, \\\"p value\\\": 0.70509}\", \"conclusion\": \"Variance not significantly difference between them\"}, {\"method\": \"F-Test for Variance\", \"result\": \"{\\\"stat\\\": 0.93518, \\\"p value\\\": 0.37087}\", \"conclusion\": \"Variance not significantly difference between them\"}] |
| Task | Variance Test |
| Difficulty | easy |
| Ground Truth | {\"columns\": [\"Japan\", \"Brazil\"], \"methods\": [\"Mood Variance Test\", \"Levene Test\", \"Bartlett Test\", \"F-Test for Variance\"]} |
| Llama-2-7B微调后评估 | {"columns": ["Japan", "Brazil"], "methods": ["Mood Variance Test", "Levene Test"]} |
| Llama-3-8B微调后评估 | {"columns": ["Japan", "Brazil"], "methods": ["Mood Variance Test", "Levene Test", "Bartlett Test", "F-Test for Variance"]} |
| Llama-3-8B-Instruct原生评估 | Here is the response: { "columns": ["Nigeria", "Pakistan", "Japan", "United States", "Brazil", "Philippines", "Myanmar", "Thailand", "Vietnam", "Indonesia", "Bangladesh", "India", "China", "Year"], "methods": ["Kolmogorov-Smirnov Test for Normality", "Pearson Correlation Coefficient", "Partial Correlation Coefficient"] } |
| Llama-3-8B-Instruct微调后评估 | {"columns": ["Japan", "Brazil"], "methods": ["Mood Variance Test", "Levene Test", "Bartlett Test", "F-Test for Variance"]} |
总结来看微调能显著提升大语言模型在专业任务上的准确性,Llama-3-8B经微调后已能完全匹配真实结果,正确识别Japan和Brazil两列并应用全部四种方差检验方法,而未微调的同模型版本则产生包含无关列和错误方法的幻觉输出,Llama-2-7B微调后也存在方法遗漏,表明模型规模、架构迭代与针对性训练共同决定了任务表现;新架构的大模型经微调后更能胜任高精度分析需求。
总结
综合看来,大语言模型在专业领域的应用潜力巨大,但其性能表现高度依赖于模型架构的先进性、参数规模的充分性以及是否经过针对性的微调训练。本案例清晰地表明,原生模型Llama-3-8B-Instruct也可能在具体任务中产生误导性输出;唯有结合新架构的优势与精准的微调策略,才能使模型真正理解并准确执行复杂、专业的分析指令。未来,在金融、医疗、科研等高精度要求的场景中,基于先进大模型的定制化微调方案将成为实现可靠人工智能决策的关键路径。