Qwen2.5-72B-Instruct 基于 alpaca_zh 数据集的微调实践
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Qwen2.5-72B-Instruct | 是 | 参数量约720亿 (72B),擅长编码、数学、长文本生成和结构化数据理解等。 |
| 数据集 | alpaca_zh | 是 | 中文指令监督微调数据集 |
| GPU | H800*8(推荐) | - | - |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
- 模型微调时长
- 微调后模型Evaluate & Predict时长
- 原生模型Evaluate & Predict时长
操作详情
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
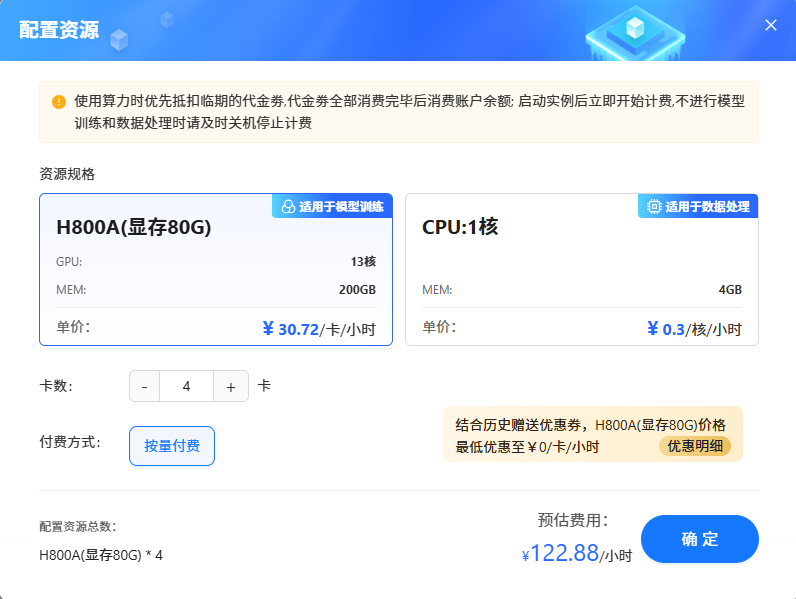
单击上图“开始微调”按钮,进入[配置资源]页面,选择GPU资源,卡数填写
8,点击“确认”,如下图所示。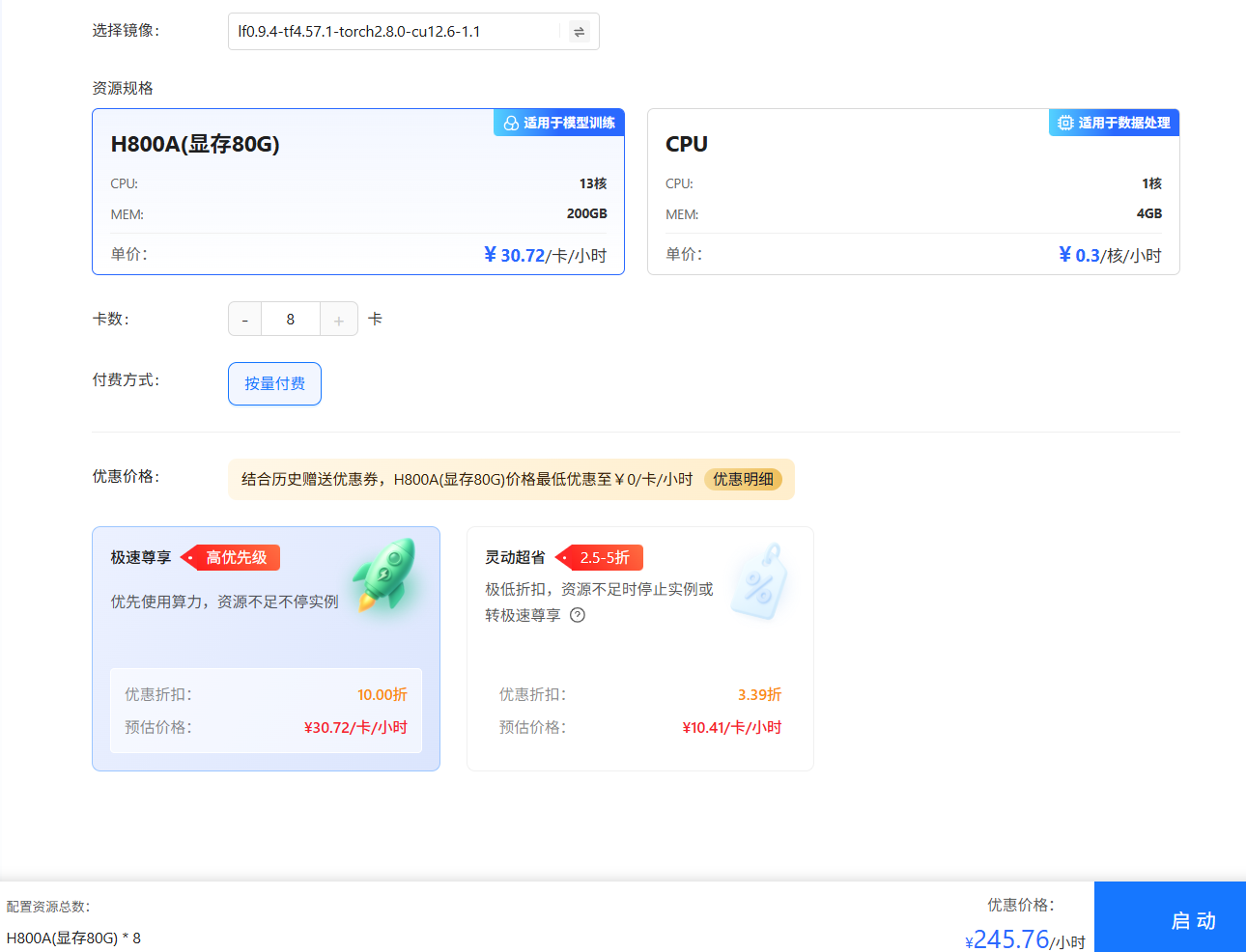
-
进行数据集配置。 本实践所用数据集为平台预置的
alpaca_zh,该数据集数据样本大小为51155条,为节约时间,可只取3000条数据样本。-
单击“实例空间”页面右侧“JupyterLab处理专属数据”,进入JupyterLab。
-
进入目录
llamafactory/data,选中目录中的dataset_info.json文件,在编辑器中打开,如下图高亮①②所示。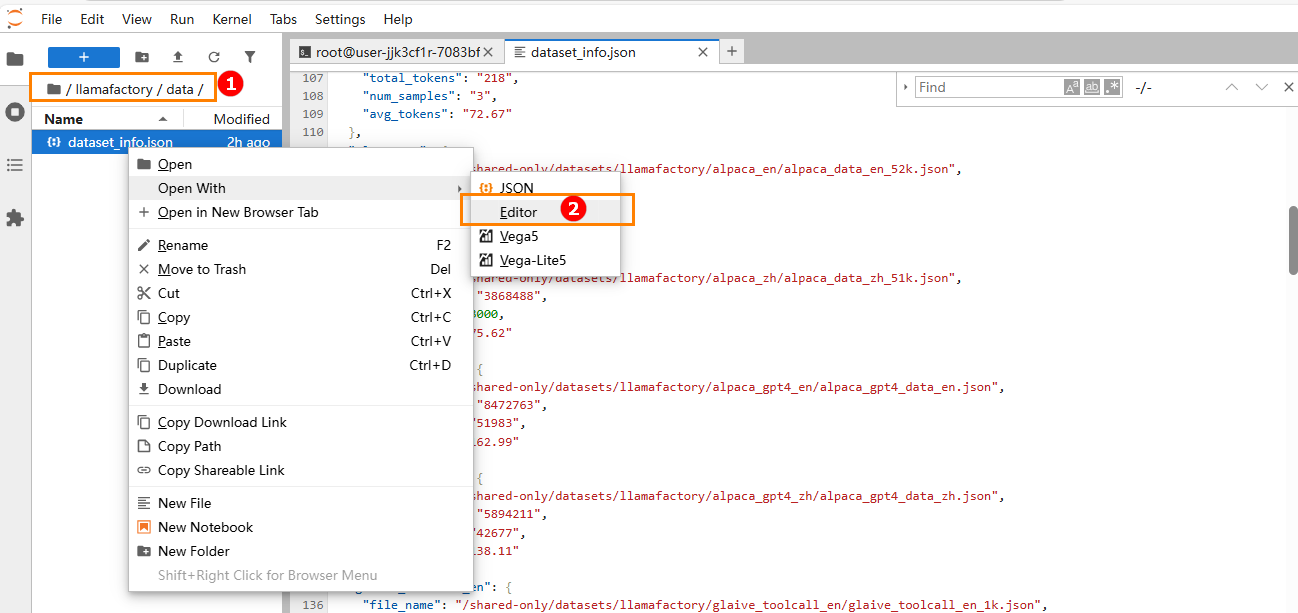
-
找到
alpaca_zh数据集,修改"num_samples"字段为:3000,如下图所示。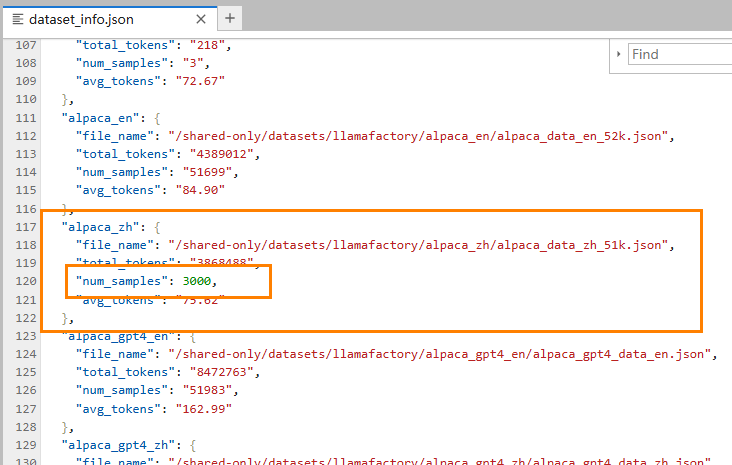
-
-
单击左侧“LlamaFactory快速微调模型”按钮,进入LlamaFactory Online在线WebUI微调配置页面,语言选择
zh,如下图高亮①所示;模型名称选择Qwen2.5-72B-Instruct,如下图高亮②所示;系统默认填充模型路径/shared-only/models/Qwen/Qwen2.5-72B-Instruct,如下图高亮③所示。 -
微调方法选择
lora,如下图高亮④所示;选择“train”功能项,训练方式保持Supervised Fine-Tuning,如下图高亮⑤所示;数据路径保持/workspace/llamafactory/data,如下图高亮⑥所示;数据集选择平台预置的alpaca_zh,如下图高亮⑦所示。另外,由于模型过大(70B参数),还需要进行分布式配置,提高显存利用率,将deepspeed stage设置为“3”,如下图高亮⑧所示。另有个别参数请参考橙色框设置。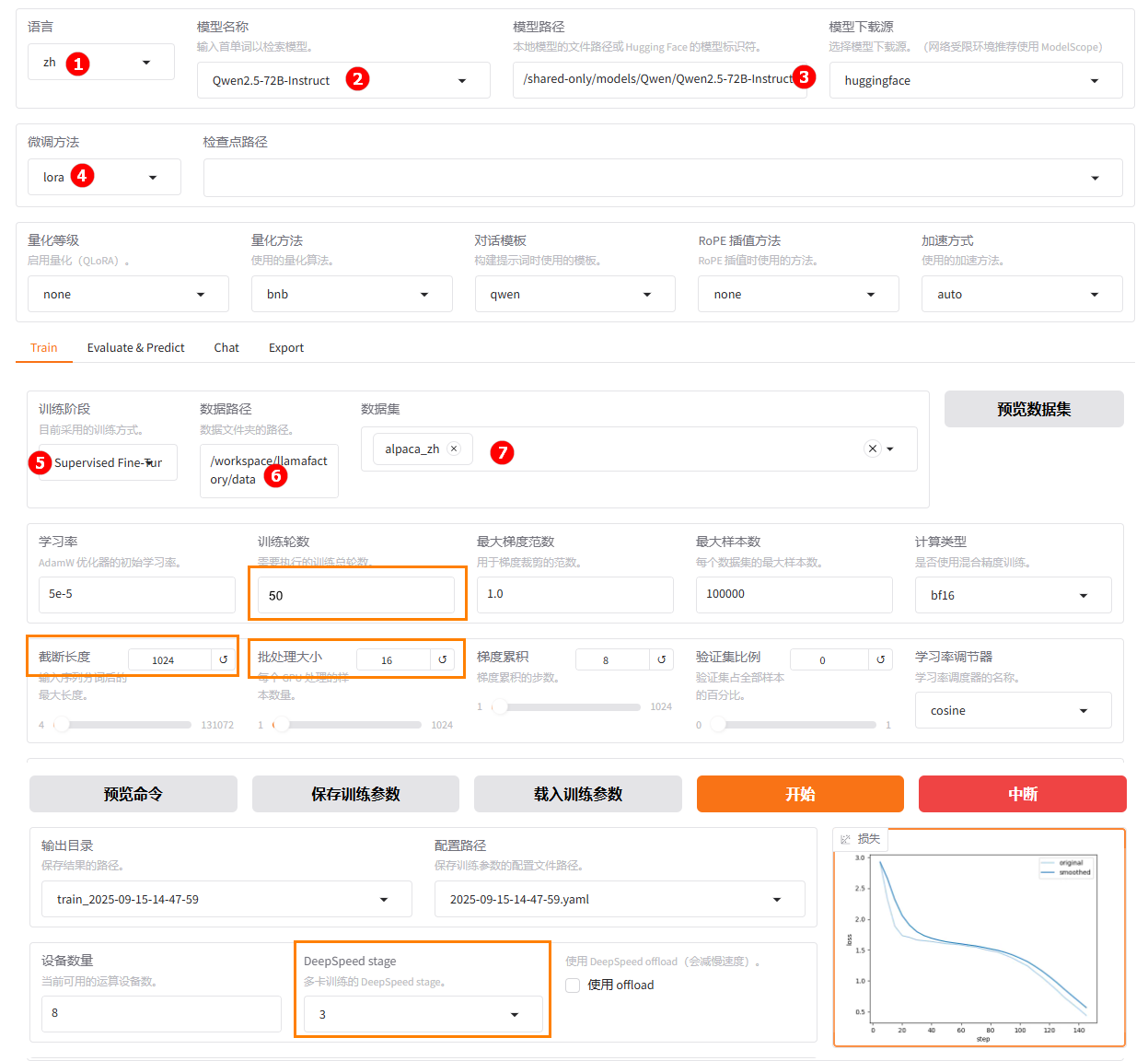
-
(可选)其余参数可根据实际需求调整,具体说明可参考参数说明,本实践中的其他参数均保持默认值。
-
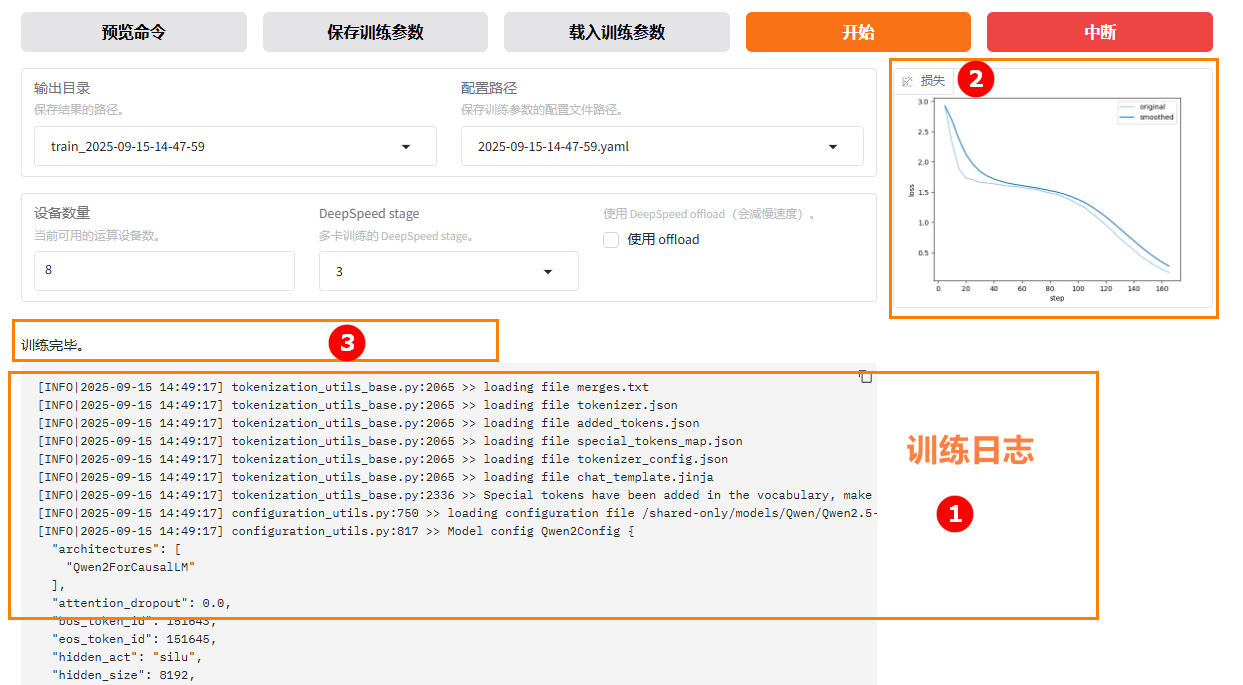
参数配置完成后,点击“开始”按钮启动微调任务。页面底部将实时显示微调过程中的日志信息,例如下图高亮①所示;同时展示当前微调进度及Loss变化曲线,如下图高亮②所示。微调完成后,系统提示“训练完毕”,例如下图高亮③所示。
- 微调后模型对话
- 原生模型对话
-
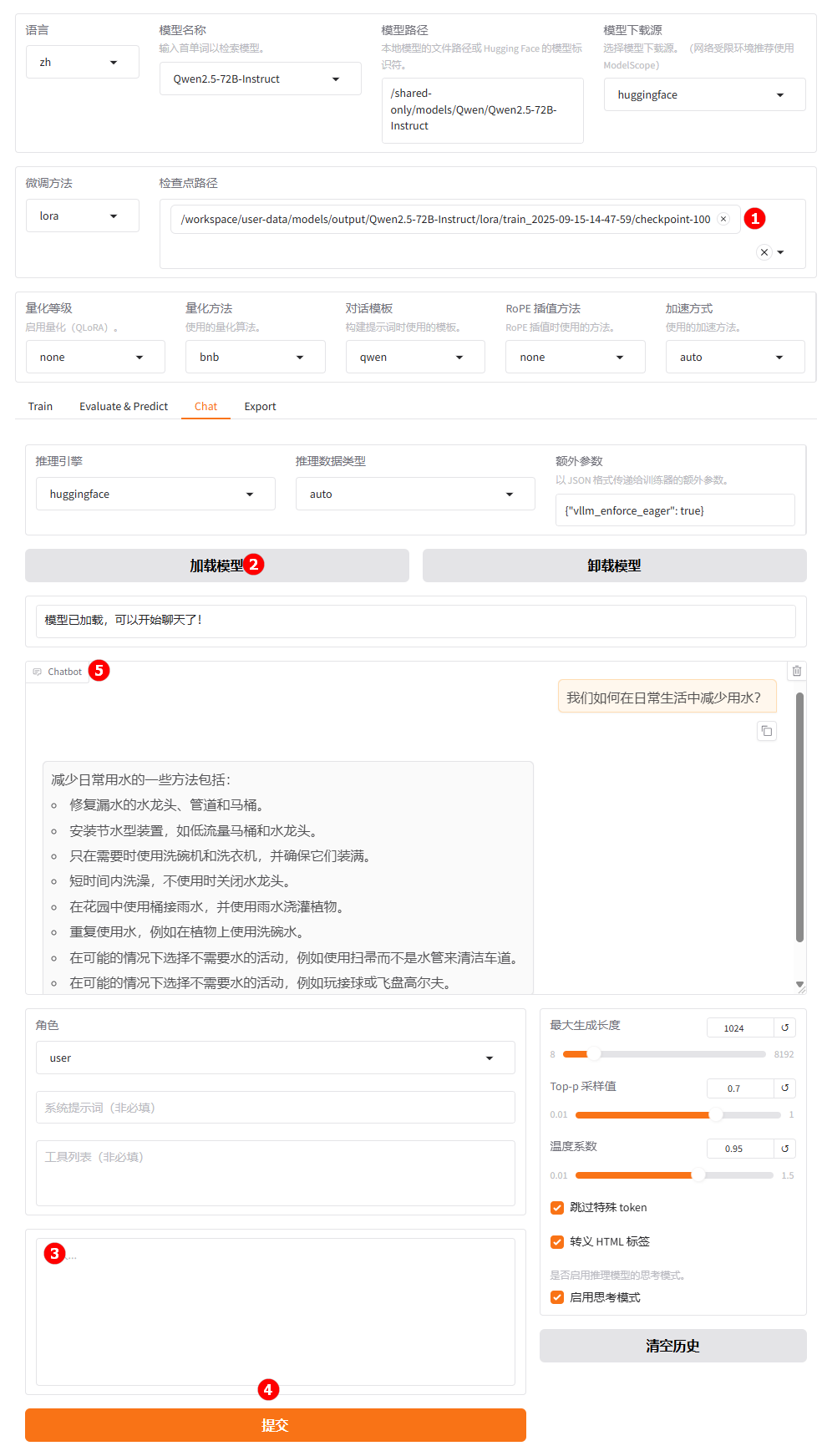
切换至“chat”界面,选择上一步骤已经训练完成的检查点路径,如下图高亮①所示;单击“加载模型”按钮,如下图高亮②所示;微调后的模型加载完成后,在提问框(高亮③)处输入问题;点击“提交”(高亮④);在对话框观察模型回答,如下图高亮⑤所示。
-
单击下图高亮①所示的“卸载模型”按钮,卸载微调后的模型;清空“检查点路径”中的LoRA配置,如下图高亮②所示;模型卸载完成后,单击“加载模型”按钮(高亮③),加载原生的
Qwen2.5-72B-Instruct模型进行对话,其余配置保持不变。用户在高亮④处输入提问,观察模型回答。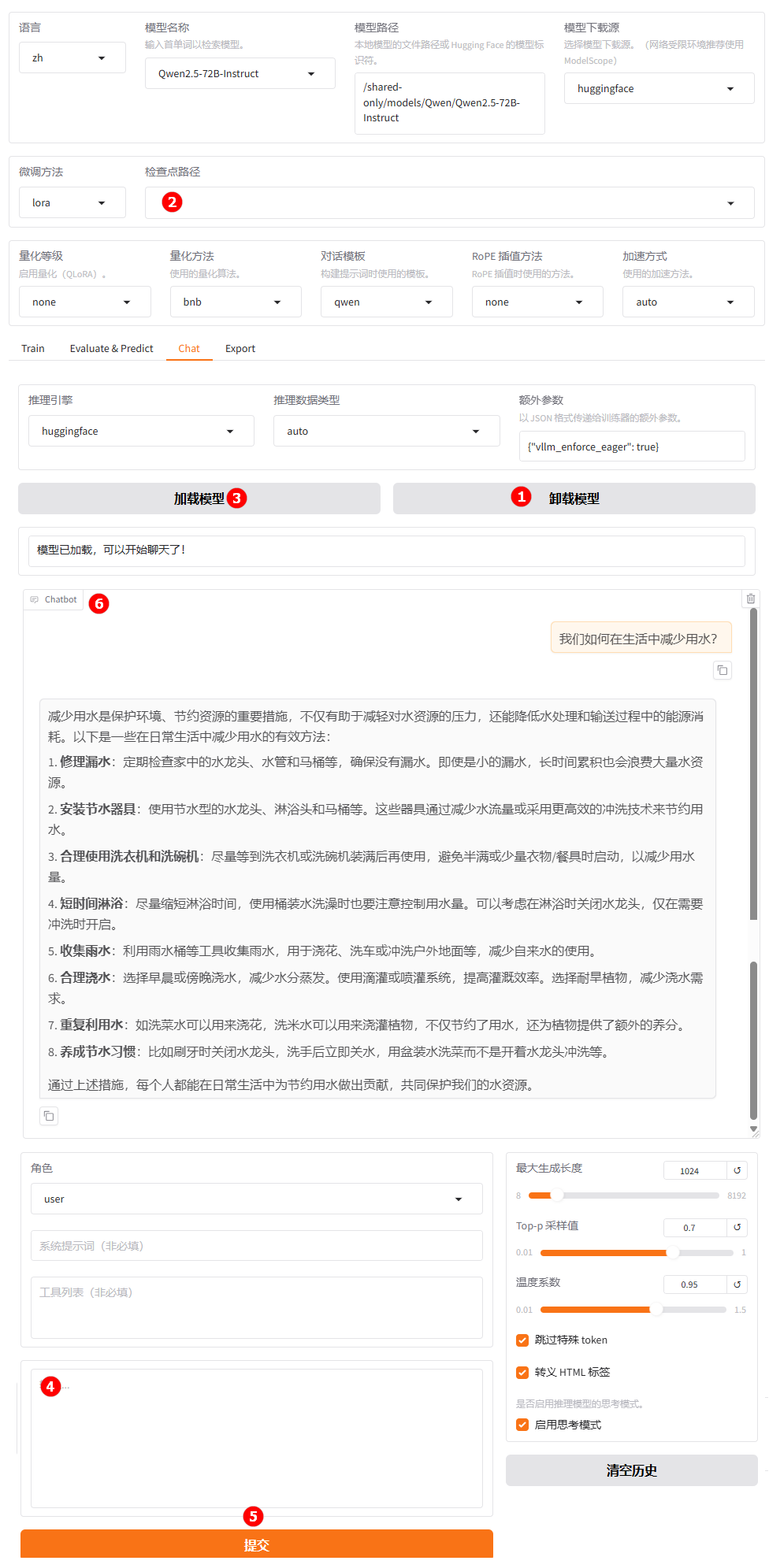
微调后模型在进行模型对话时,生成内容与参考答案的匹配度、覆盖度更接近。原生模型基于基模型本身思考能力回答。
-
返回LlamaFactory Online平台的“实例空间”页面,点击右侧“JupyterLab处理专属数据”,进入jupyterlab工作空间。
注意目前LFO webUI不支持多卡评估,而72B模型单卡无法进行推断,所以需要在jupyterlab的终端内运行LlamaFactory项目中的vllm_infer.py脚本,进行分布式评估。
本次实践的模型评估需要至少4张H800A显卡。
-
在
/workspace路径下新建一个文件夹,命名:Qwen2.5-72B,用作存放评估相关的脚本和输出文件。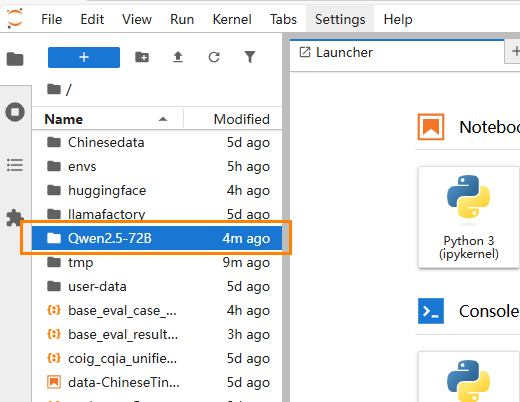
下载LLaMAFactory项目压缩包,拖到
Qwen2.5-72B文件夹下,目录为/workspace/Qwen2.5-72B。
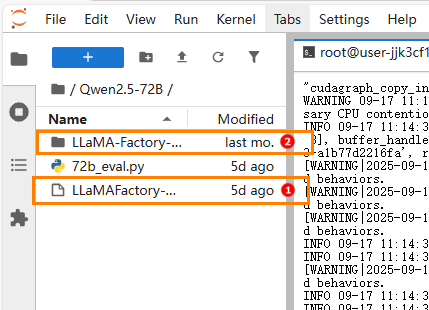
点击jupyterlab页面的Terminal打开终端,使用下面的命令解压下载的压缩包。unzip /workspace/Qwen2.5-72B/LLaMA-Factory-main.zip解压后如下图所示:高亮①处为上传的压缩包,高亮②处为解压后的文件夹。
-
生成评估案例及样本。
- 微调后模型评估
- 原生模型评估
打开jupyter notebook内的终端(Terminal),默认启动的环境名为lf。使用lf环境,运行下列vllm_infer.py的命令,开始进行模型评估样本的生成。
python /workspace/Qwen2.5-72B/LLaMA-Factory-main/scripts/vllm_infer.py \
--model_name_or_path /shared-only/models/models/Qwen/Qwen2.5-72B-Instruct \
--adapter_name_or_path /workspace/user-data/models/output/{your_checkpoint} \
--dataset_dir /workspace/llamafactory/data \
--dataset alpaca_zh \
--template qwen \
--cutoff_len 1024 \
--max_samples 500 \
--save_name /workspace/{your_save_name}.jsonl \
--temperature 0.1 \
--top_p 0.9 \
--top_k 40 \
--max_new_tokens 512 \
--repetition_penalty 1.1 \
--batch_size 8 \
--seed 42 \
--vllm_config '{"tensor_parallel_size": 4}'注意请更改以下参数为自定义值。
adapter_name_or_path:{your_checkpoint}处填入需加载的checkpoint路径(如果对基模型进行评估,请勿传入这一参数)。本实践的checkpoint路径为:/workspace/user-data/models/output/Qwen2.5-72B-Instruct/lora/train_2025-09-11-10-23-19 \save_name: 微调后的模型生成的评估案例保存路径。 本实践的保存路径为:
/workspace/eval_case_Qwen2.5-72B.jsonl \vllm_config: tensor_parallel_size的值与您启动实例时的GPU卡数一致。
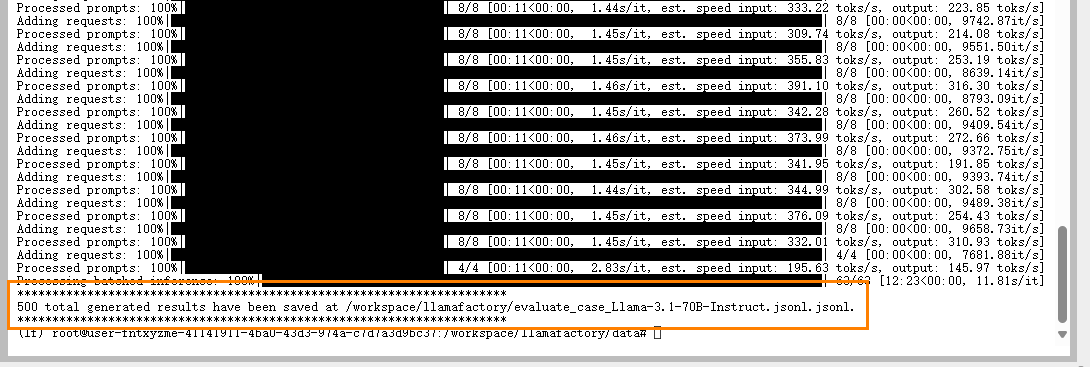
出现如下图所示的输出,表示运行成功。
打开jupyter notebook内的终端(Terminal),默认启动的环境名为lf。使用lf环境,运行下列vllm_infer.py的命令,开始进行模型评估样本的生成。
python /workspace/Qwen2.5-72B/LLaMA-Factory-main/scripts/vllm_infer.py \
--model_name_or_path /shared-only/models/models/Qwen/Qwen2.5-72B-Instruct \
--dataset_dir /workspace/llamafactory/data \
--dataset alpaca_zh \
--template qwen \
--cutoff_len 1024 \
--max_samples 500 \
--save_name /workspace/{your_save_name}.jsonl \
--temperature 0.1 \
--top_p 0.9 \
--top_k 40 \
--max_new_tokens 512 \
--repetition_penalty 1.1 \
--batch_size 8 \
--seed 42 \
--vllm_config '{"tensor_parallel_size": 4}'注意请更改以下参数为自定义值。
save_name: 微调后的模型生成的评估案例保存路径。 本实践的保存路径为:/workspace/base_eval_case_Qwen2.5-72B.jsonl \vllm_config: tensor_parallel_size的值与您启动实例时的GPU卡数一致。
出现如下图所示的输出,表示运行成功。
-
准备评估环境。 创建新环境,为评估模型做准备。
点击jupyterlab页面的
Terminal打开终端,创建新的python环境。(本实践中新环境命名为“evaluate”,python版本为"3.10")conda create -n evaluate python=3.10创建完成后,启动该环境。
conda activate evaluate安装指令评估所需要的python包。
pip install evaluate rouge-score nltk -i https://pypi.tuna.tsinghua.edu.cn/simple -
开始评估。
下载指标评估文件,拖拽到
/worksapace/Qwen2.5-72B目录下。
在新建的“evaluate”环境中,运行以下指令进行评估。
- 微调后模型评估
- 原生模型评估
python Qwen2.5-72B/72b_eval.py \
--pred_file {generated_predictions}.jsonl \
--output_metrics {metrics_save_name}.json注意修改以下参数值:
pred_file:评估案例保存的文件路径。本实践路径为:/workspace/eval_case_Qwen2.5-72B.jsonl \
output_metrics:本次指令评估的结果保存路径。本实践路径为:/workspace/eval_result_Qwen2.5-72B.jsonpython Qwen2.5-72B/72b_eval.py \
--pred_file {generated_predictions}.jsonl \
--output_metrics {metrics_save_name}.json注意修改以下参数值:
pred_file:评估案例保存的文件路径。本实践路径为:/workspace/base_eval_case_Qwen2.5-72B.jsonl \
output_metrics:本次指令评估的结果保存路径。本实践路径为:/workspace/base_eval_result_Qwen2.5-72B.json -
评估结果如下所示。
- 微调后模型评估
- 原生模型评估

{
BLEU-4: 0.1008
ROUGE-1: 0.2247
ROUGE-2: 0.1439
ROUGE-L: 0.2163
}结果解读:BLEU-4为0.1008,模型生成内容与参考答案在短语和字面层面有一定匹配,但整体精确度不高。ROUGE-1、ROUGE-2、ROUGE-L结果说明模型生成内容与参考答案在词汇、短语和句子结构层面有部分重合,覆盖度和连贯性较原生模型更好。
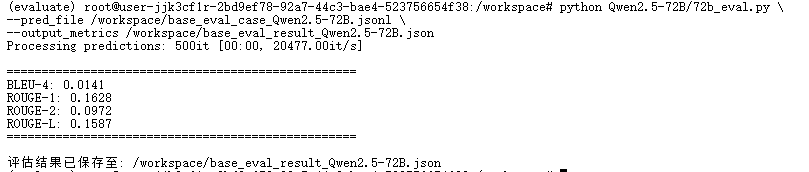
{
BLEU-4: 0.0141
ROUGE-1: 0.1628
ROUGE-2: 0.0972
ROUGE-L: 0.1587
}结果解读:BLEU-4为0.0141,模型生成内容与参考答案在短语和字面层面匹配度很低,精确度较差。ROUGE-1、ROUGE-2、ROUGE-L结果说明模型生成内容与参考答案在词汇、短语和句子结构层面重合度较低,覆盖度和连贯性一般。
微调后模型在各项指标上均优于原生模型,生成内容与参考答案的匹配度、覆盖度和连贯性明显提升,更适合实际应用场景。微调能够有效提升模型的专业性和生成质量。
总结
本实践将数据集alpaca_zh放在基础模型Qwen2.5-72B-Instruct上进行微调训练,并提供了微调后的模型与原生模型在模型对话、模型评估上的对比分析。对比显示:微调后的模型在各项评估指标上明显优于原生模型,生成内容更贴近参考答案,覆盖度和连贯性更好,说明微调显著提升了模型的专业性和实际应用价值。本实践为用户提供了可复现的微调和评估流程,便于后续在特定领域数据集上进一步优化模型效果。
关于License,请按照LlamaFactory的版权要求使用,请参考该链接内容。