基于ComfyUI调用Flux文生图模型生成动漫风格图像
ComfyUI作为一款基于节点式工作流的开源AI图像生成工具,为创作者实现多样化风格图像生成提供了高度灵活的技术支撑。其核心优势在于通过可视化节点拆解图像生成全流程,让不同风格的创作需求能够被精准转化为可调控的技术参数链条。
文生图(Text to Image)是AI绘图的核心基础能力,核心逻辑是通过输入文本描述(包含正向提示词、负向提示词),让AI模型将文字信息转化为对应的可视化图像,是当前AI绘图场景中最常用、最易上手的功能之一。可以通俗理解为:您作为需求方,把具体的绘图要求(比如 “暖色调的日系街道,樱花飘落,便利店亮着暖黄灯光” 这类正向描述,以及 “模糊、低画质、人物变形” 这类需规避的负向描述)清晰告知AI“画家”,而这个 “画家”(即文生图模型)会依据文本中的细节要求,生成符合您预期的图像成果。
本文档指导您如何在LlamaFactory Online平台基于ComfyUI调用Flux文生图模型生成动漫风格图像。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
步骤一:安装ComfyUI
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
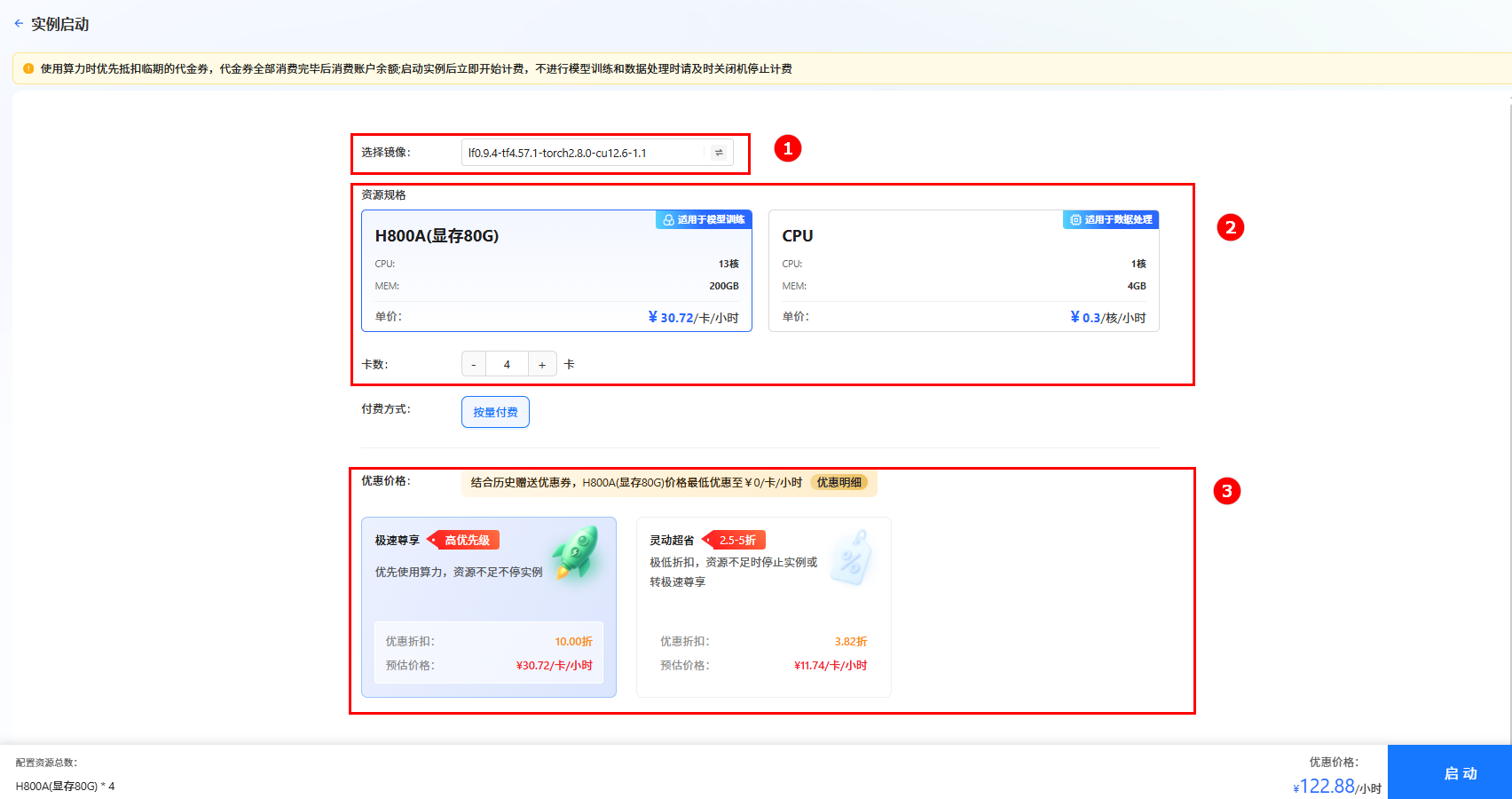
单击上图“开始微调”按钮,进入[实例启动]页面,配置以下参数,然后单击“启动”按钮,启动实例。
- 选择镜像:系统默认镜像
lf0.9.4-tf4.57.1-torch2.8.0-cu12.6-1.1(如图①)。 - 资源配置:选择GPU,推荐卡数为4卡(如图②)。
- 选择价格模式:本实践选择“极速尊享”(如图③),不同模式的计费说明参考计费说明。
 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
- 选择镜像:系统默认镜像
-
实例启动后,单击[VSCode处理专属数据]页签,进入VSCode编辑页面。
-
下载ComfyUI。
a. 在VSCode页面,新建一个终端。
b. 然后进入/workspace目录执行以下命令,下载ComfyUI(如图①),下载完成后默认生成一个ComfyUI目录(如图②)。
git clone https://github.com/comfyanonymous/ComfyUI.git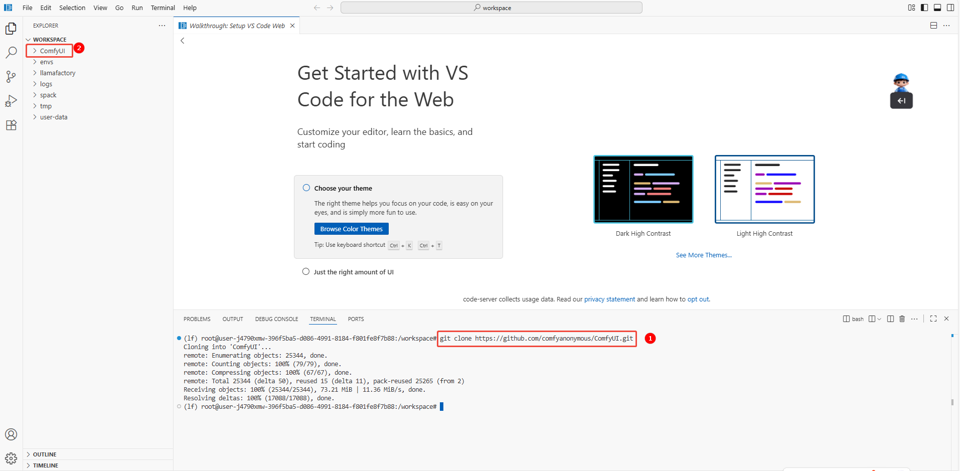
-
配置环境并安装ComfyUI。
a. 执行如下命令,为ComfyUI单独创建一个虚拟环境。
conda create -n comfyui python=3.12 -y
conda activate comfyuib. 执行如下命令,进入ComfyUI目录,在新创建的虚拟环境中安装依赖包。
cd ComfyUI
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/提示整个安装过程大约需要2min。
-
执行如下命令,启动ComfyUI。
cd ComfyUI
python main.py --listen 0.0.0.0 --port 6666 -
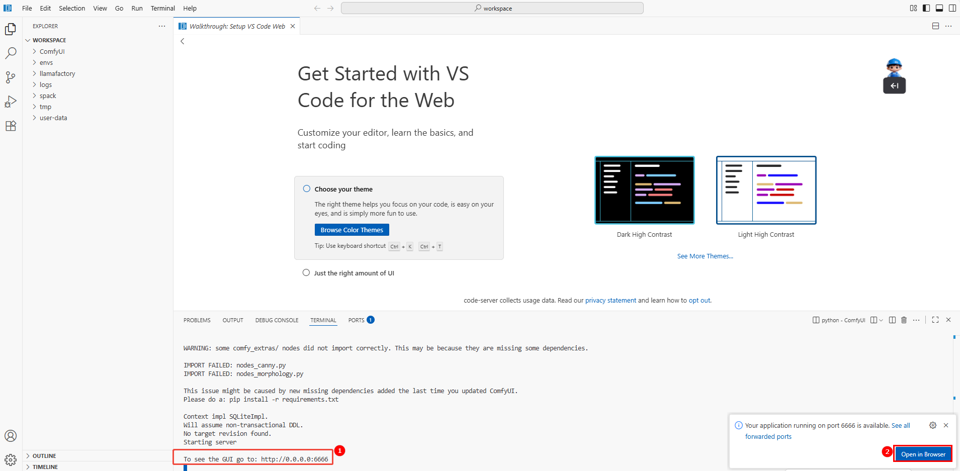
访问ComfyUI,出现以下提示(如图①),说明ComfyUI启动成功,单击右下角的“Open in Browser”链接(如图②),即可访问ComfyUI。
-
访问成功的ComfyUI界面如下图所示。
步骤二:使用ComfyUI生成图像
-
您已按照上述步骤一成功安装并访问ComfyUI界面。
-
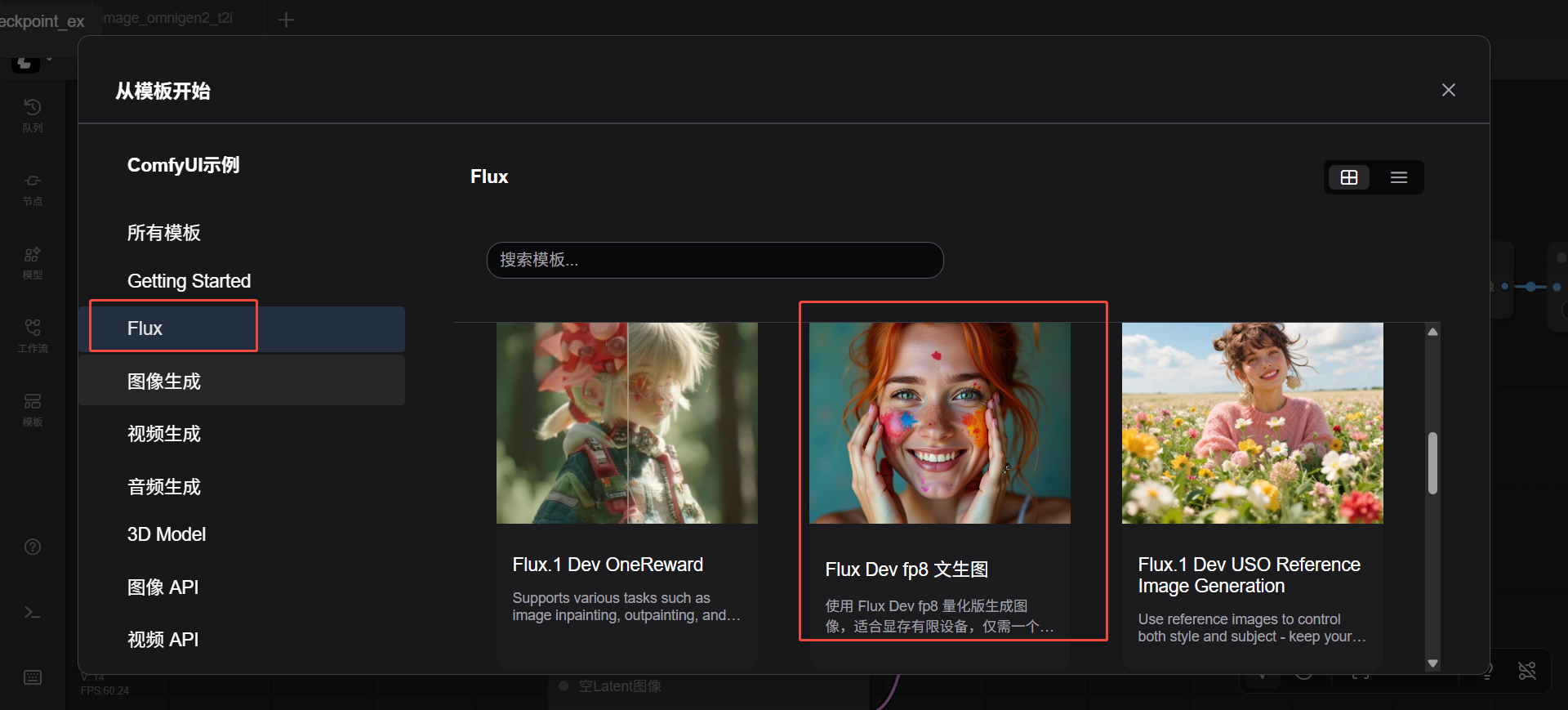
加载默认Flux文生图工作流。
在弹出的对话框中,选择左侧导航栏的“Flux”,然后单击“Flux Dev fp8文生图”模版,如下图所示。
-
安装绘图模型。
a. 打开模板后,如果缺少对应模型,则会弹出以下提示信息,您可以单击“复制链接”按钮,获取对应的模型名称,以便后续下载安装模型。
复制的链接为:
https://huggingface.co/Comfy-Org/flux1-dev/resolve/main/flux1-dev-fp8.safetensors?download=true根据复制的链接地址,获取到的模型名称为:flux1-dev-fp8.safetensors。
 提示
提示您也可以通过 “复制链接” 直接下载模型,但该方式下载耗时通常较长;为更高效地节省您的时间,建议优先使用本示例中提供的方法下载模型。
b. 在终端执行如下命令,下载模型至指定的文件夹。
export HF_ENDPOINT=http://hfmirror.xn-01.zetyun.cn:8082
pip install -U huggingface_hub==0.35.3
huggingface-cli download --resume-download Comfy-Org/flux1-dev --include "flux1-dev-fp8.safetensors" --local-dir /workspace/ComfyUI/models/checkpoints注意其中,命令中的“flux1-dev-fp8.safetensors”则为上一步骤中获取到的模型名称,您可以根据实际获取到的模型名称结果进行替换。
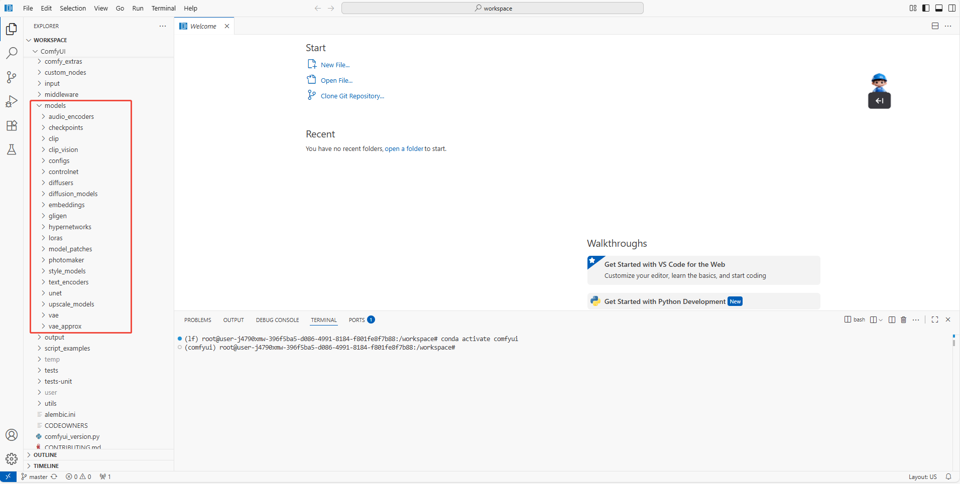
如下图所示,下载的模型会统一保存至指定的
ComfyUI/models/文件夹。该目录下按模型功能分类了多个子文件夹,便于管理:checkponts:存放基础生成模型(如 Flux、Stable Diffusion 系列);embeddings:存储文本嵌入文件(用于优化提示词效果);vae:负责图像解码(影响生成图像的色彩与细节还原);loras:用于风格微调(快速切换动漫、写实等特定风格);upscale_models:实现图像放大(提升生成图的分辨率)。
 提示
提示整个下载安装过程大约需要12min。
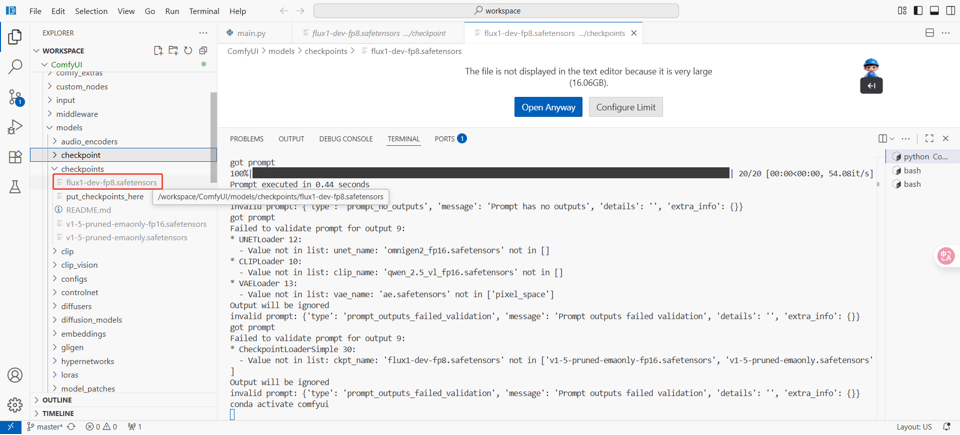
ComfyUI启动时,会自动检测
upscale_modelmodels/目录下各子文件夹中的模型文件(如.safetensors、.ckpt格式);若需加载自定义路径的模型,可在extra_model_paths.yaml文件中配置额外路径,系统会同步加载该路径下的模型,确保所有可用模型都能在节点中选择使用。如下图左侧高亮所示出现“flux1-dev-fp8.safetensors”,表示模型下载完成。
c. 模型下载完成后,请执行如下命令重启ComfyUI服务,确保系统能识别到新安装的模型。
cd ComfyUI
python main.py --listen 0.0.0.0 --port 6666 -
加载模型并生成图像。
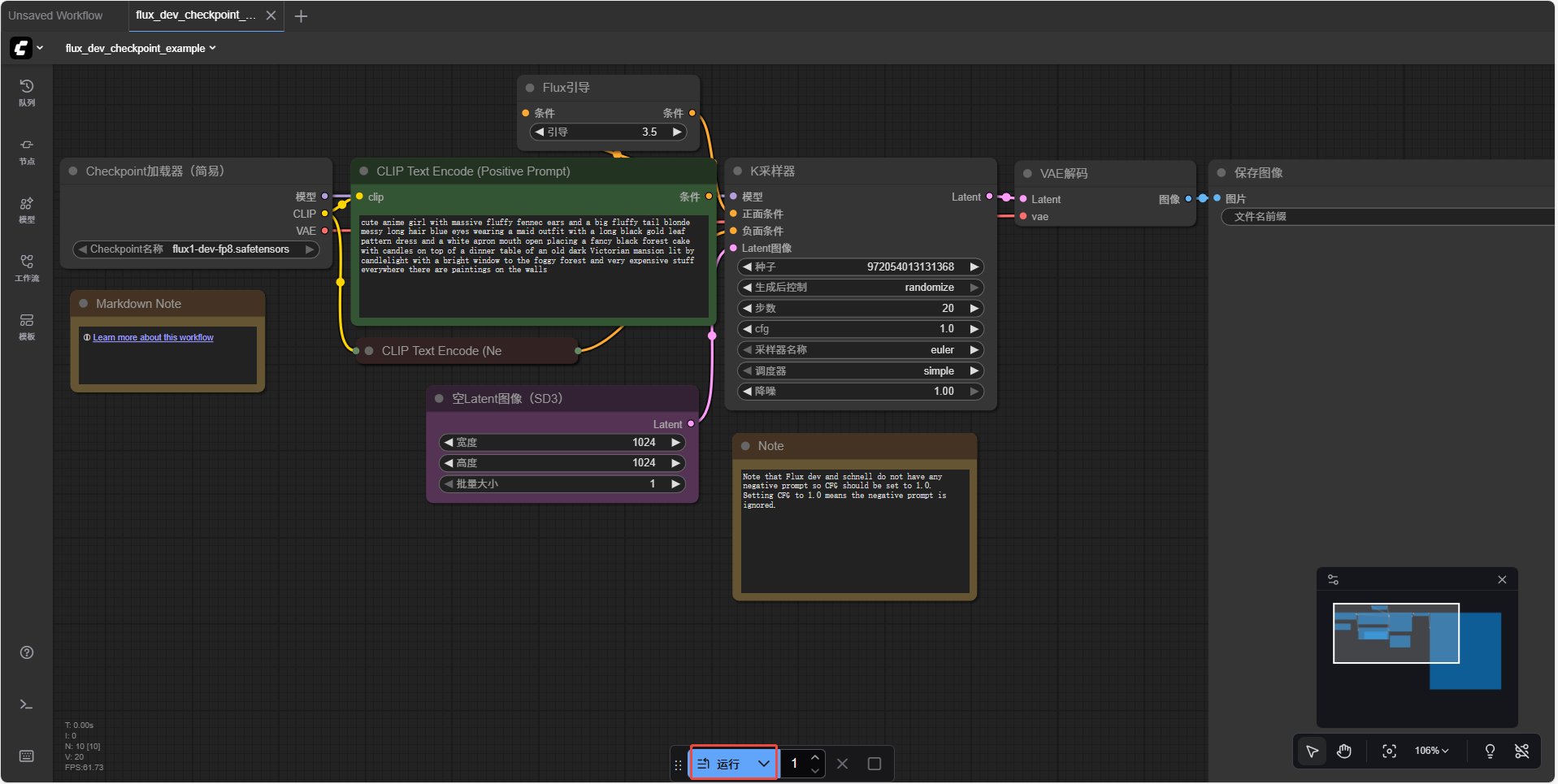
a. 模型检测正常后,如下图所示,在“Load Checkpoint”节点中选择已安装的“flux1-dev-fp8.safetensors”模型,确认所有节点连线无误后,单击“运行”,启动图像生成流程。
 提示
提示-
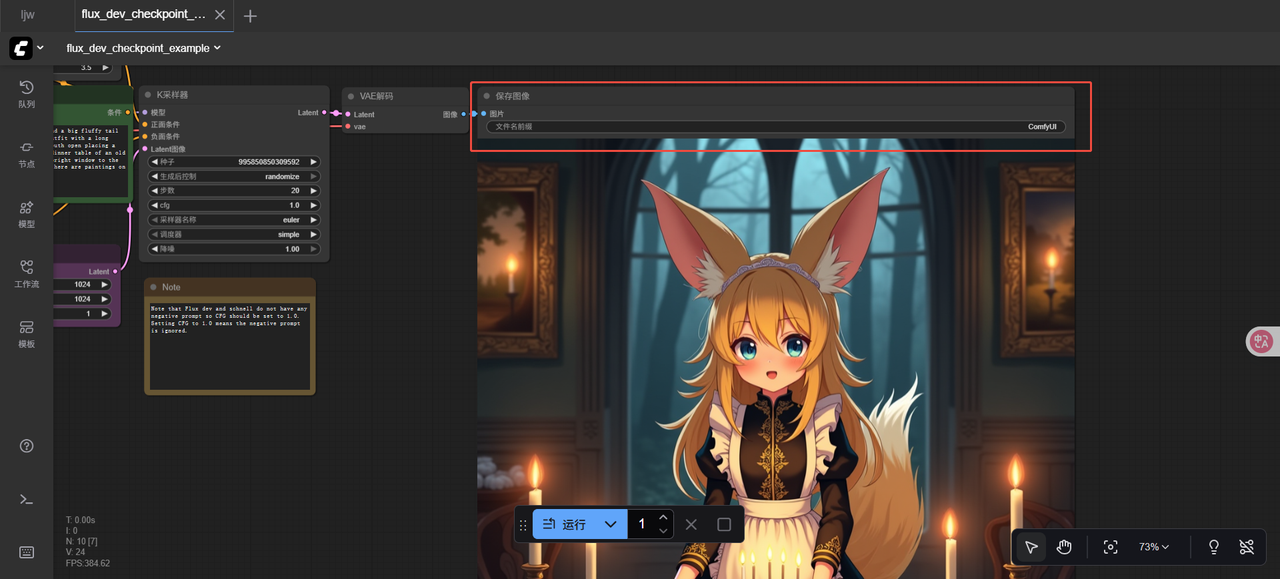
ComfyUI初次使用文生图模型时,会通过默认节点配置提供一套基础的图像生成参数,帮助用户快速入门。用户加载模型后无需手动配置所有节点,即可直接生成第一张图像。本示例中,默认配置会生成符合描述的动漫女孩插画,画面包含蓬松的耳廓狐耳朵、金色长发、女仆装以及维多利亚风格房间内的黑森林蛋糕场景。
-
这些预制参数仅为基础配置,您需根据具体模型类型(如动漫、写实风格)和实际需求进行调整。
b. 等待工作流执行完成后,您可以在界面右侧的“保存图像(Save Image)”区域查看生成的图像预览,同时可以右键保存图像至本地。
 提示
提示本次图像生成过程大约用时19.26s。
-
常见问题
问题1
如果Load Checkpoint节点没有任何模型可以选择,或者显示为null,如何排查处理?
解决方案
请先确认您的模型安装位置是否正确,若安装位置正确,请尝试刷新/重启ComfyUI,使得对应文件夹下的模型可以被ComfyUI检测到。
总结
当前,ComfyUI已成为数字艺术创作领域的核心工具,其内置的风格化工作流模板覆盖古典绘画、现代设计、未来主义等数十种风格体系,能精准适配游戏美术、广告设计、影视概念图等多元场景的风格化需求,为创作者提供了从技术实现到艺术表达的全链路解决方案,而用户可借助LlamaFactory Online平台提供的VSCode自定义构建环境,快速落地基于ComfyUI的图像生成能力,高效打通 “工具配置-创作落地” 的全流程。