基于Llama-3-8B的动态多角色交互式学术论文评审模型
近年来,大语言模型(LLM)在学术论文同行评审中的应用逐渐引起关注。现有LLM仅限于静态评论生成,未能捕捉真实评审的动态迭代和多角色交互特性。这种局限不仅削弱了模型对长语境信息的利用能力,也限制了其对评审质量与公平性的提升作用。与此同时,传统同行评审机制仍面临效率低下、潜在偏见和透明度不足等问题,亟需新的技术路径加以改进。这种需求催生了多轮、多角色、长语境驱动的交互式对话框架。
Llama-3-8B(微调后)是针对学术论文评审的多角色对话模型,通过用户输入的评审建议和角色设定(评审人、作者、决策者),生成符合角色特征的评审意见。该模型框架明确了评审人负责评估与反馈、作者负责澄清与修订、决策者负责综合判断的分工,并构建了清晰的交互逻辑。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Llama-3-8B | 是 | 经过指令微调,参数量约80亿 (8B),专为遵循指令和对话任务优化。 |
| 数据集 | 训练:ICLR_2024 评估:iclr_test_data | 是 | 维护对话历史、角色切换机制以及提示来确保对话符合预设的角色设定。 |
| GPU | H800*4(推荐) | - | H800**2(最少)。 |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
- 模型微调时长
- 微调后模型Evaluate & Predict时长
- 原生模型Evaluate & Predict时长
操作详情
LlamaFactory Online支持通过实例模式和任务模式运行微调任务,不同模式下的微调/评估操作详情如下所示。
- 任务模式微调
- 实例模式微调
-
进入LlamaFactory Online平台,点击“控制台”,进入控制台后点击左侧导航栏的“模型微调”进入页面。
-
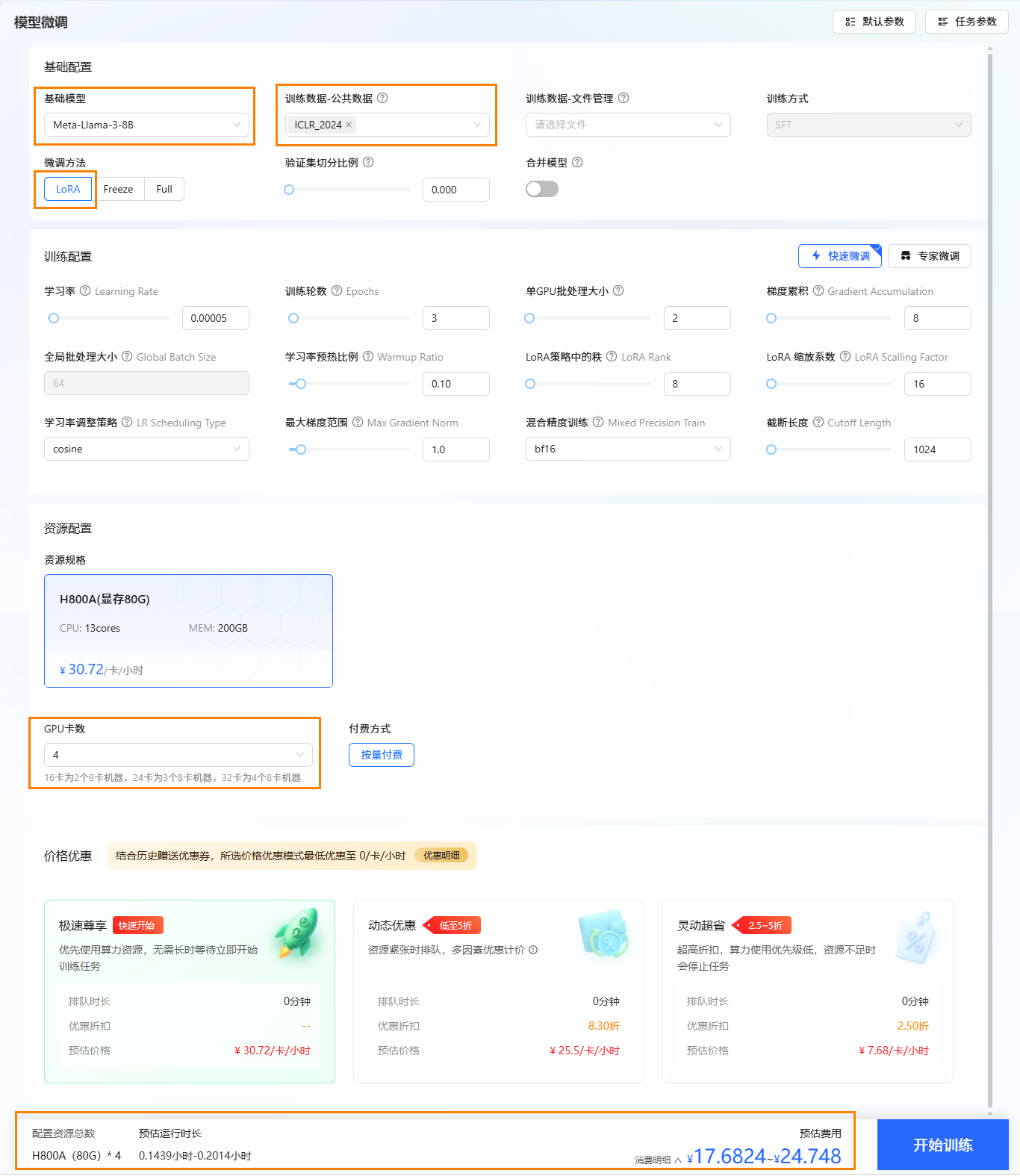
选择基础模型和数据集,进行参数配置。
- 本实践使用平台内置的Llama-3-8B作为基础模型,数据集为平台内置的
ICLR_2024。 - 资源配置。8B模型的微调最低1张H800A显卡即可运行,本实践卡数选择4卡。
- 选择价格模式。本实践选择“极速尊享”,不同模式的计费说明参考计费说明。
- 开始训练。点击“开始训练”按钮,开始模型训练。
 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
- 本实践使用平台内置的Llama-3-8B作为基础模型,数据集为平台内置的
-
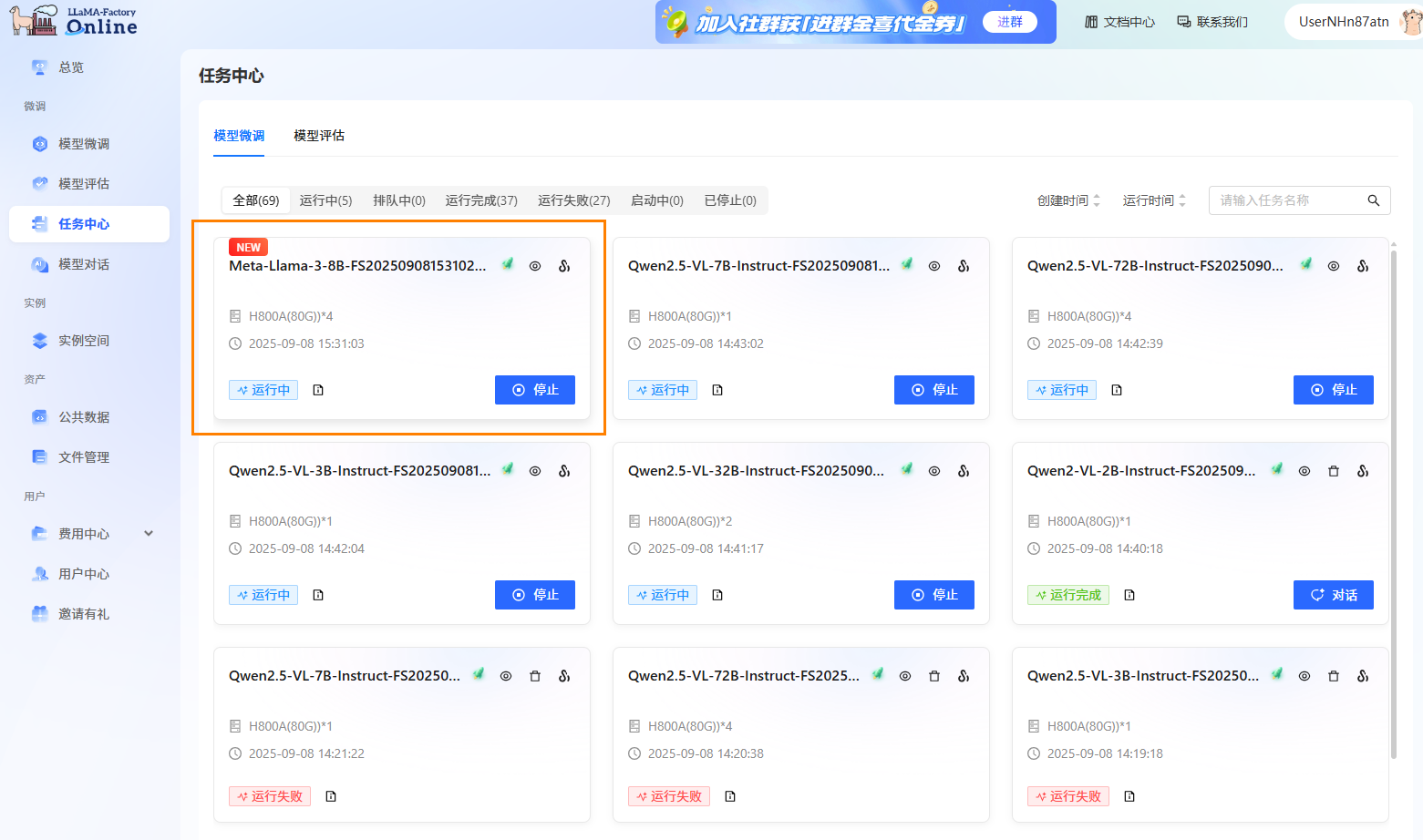
通过任务中心查看任务状态。 在左侧边栏选择”任务中心“,即可看到刚刚提交的任务。可以通过单击任务框,可查看任务的详细信息、超参数、训练追踪和日志。
-
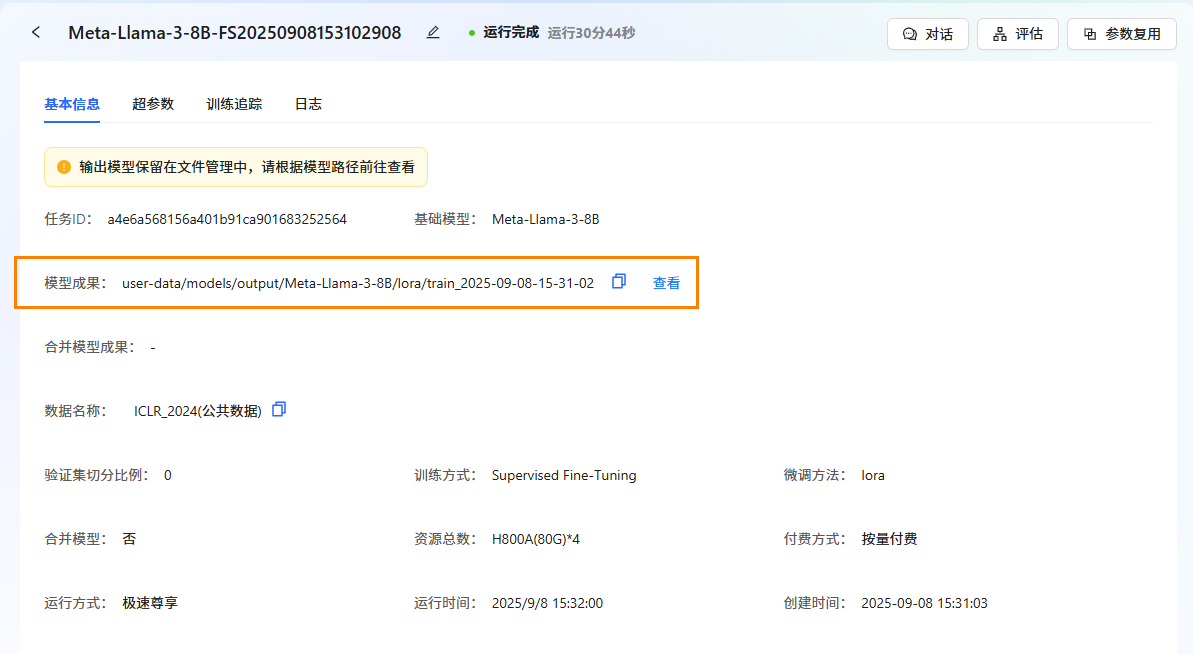
任务完成后,模型自动保存在"文件管理->模型->output"文件夹中。可在"任务中心->基本信息->模型成果"处查看保存路径。
-
进行模型评估。 点击页面左侧导航栏“模型评估”,进行评估训练配置。 微调模型选择上一步骤微调后的模型,评估数据集平台内置的测试集:
iclr_test_data。其他参数设置为默认。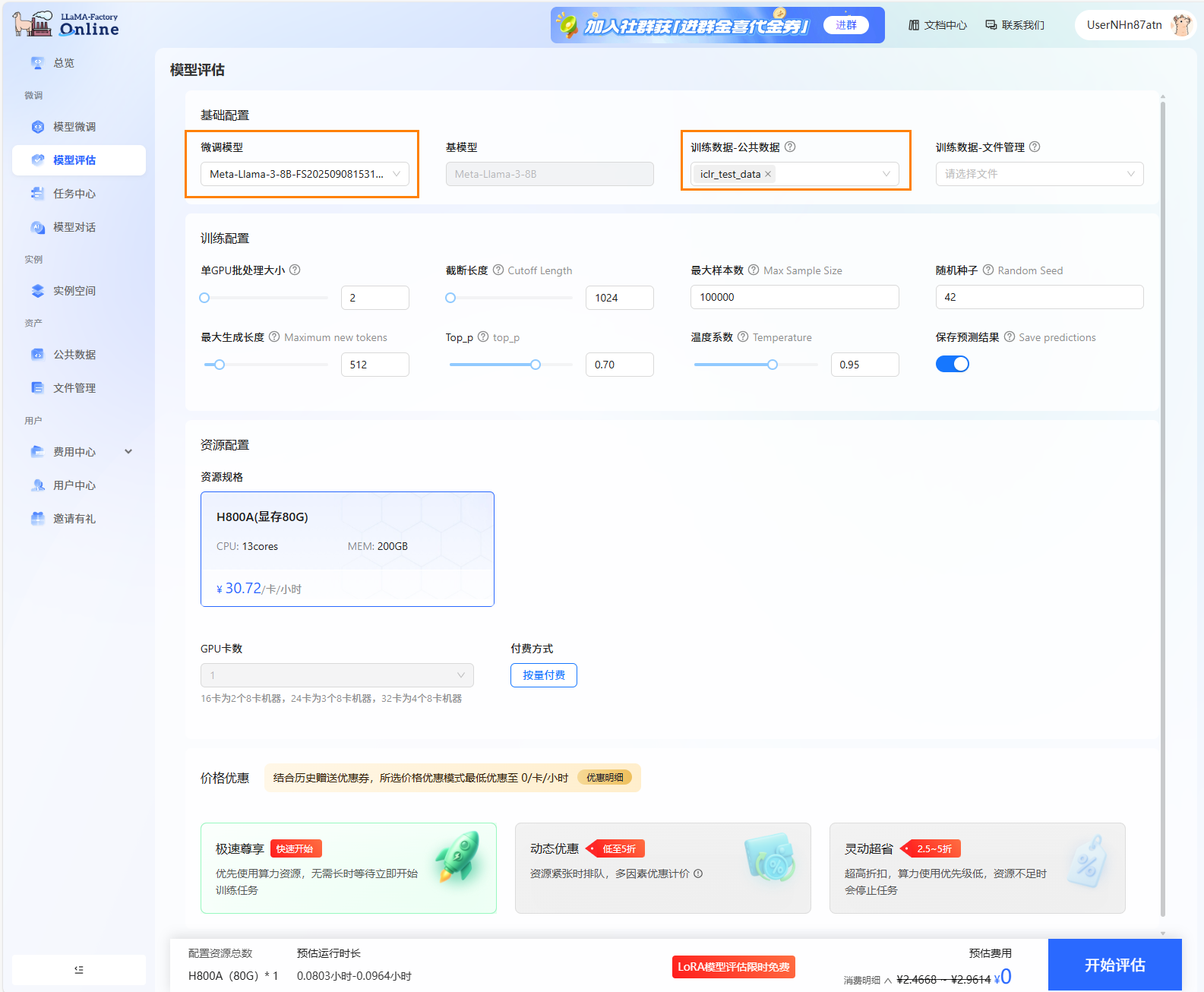
-
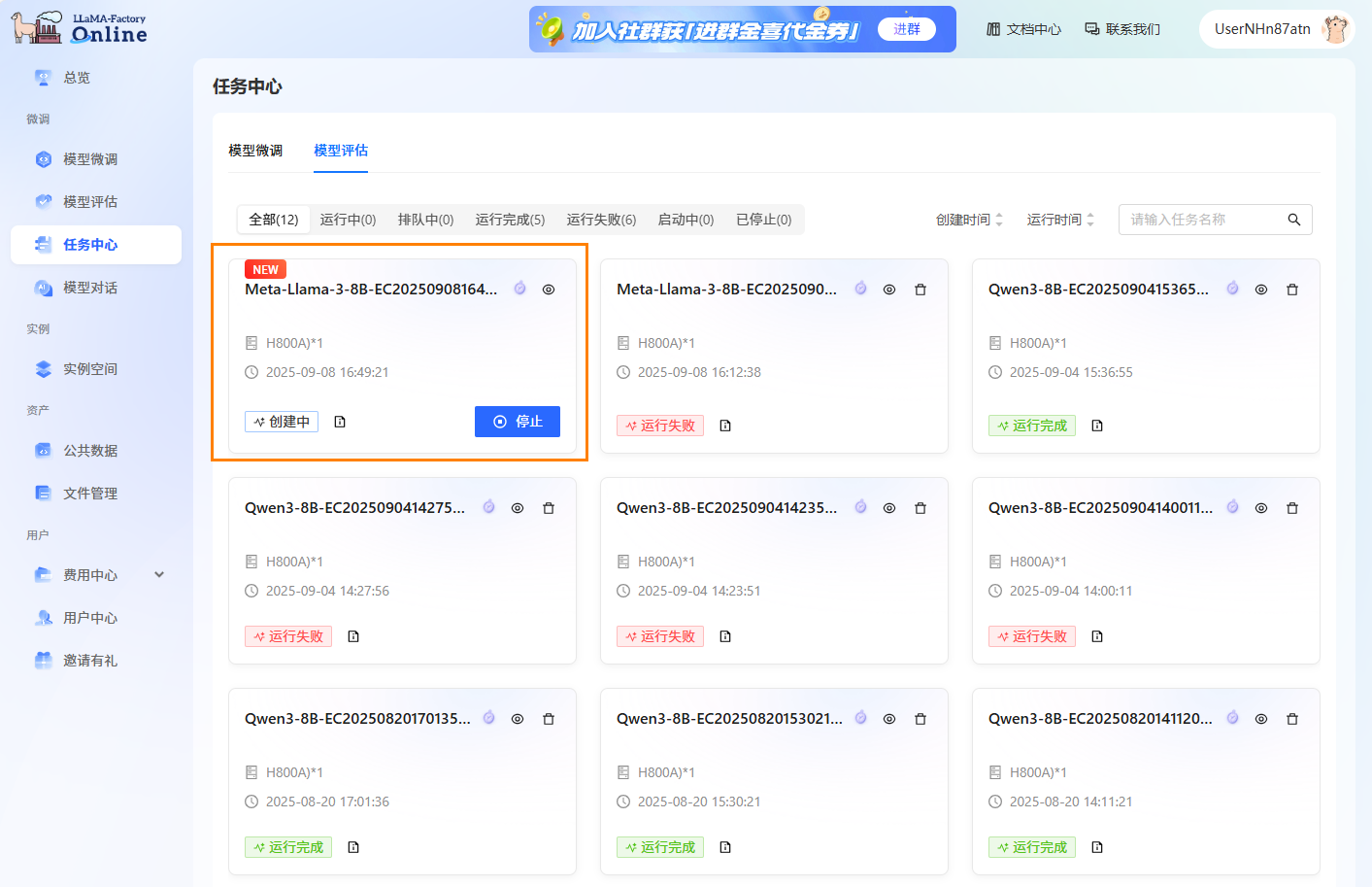
可以在“任务中心->模型评估”下看到评估任务的运行状态。
 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
-
点击
 图标,进入任务基本信息查看页面。用户可查看评估任务的基本信息、日志以及评估结果。
图标,进入任务基本信息查看页面。用户可查看评估任务的基本信息、日志以及评估结果。 -
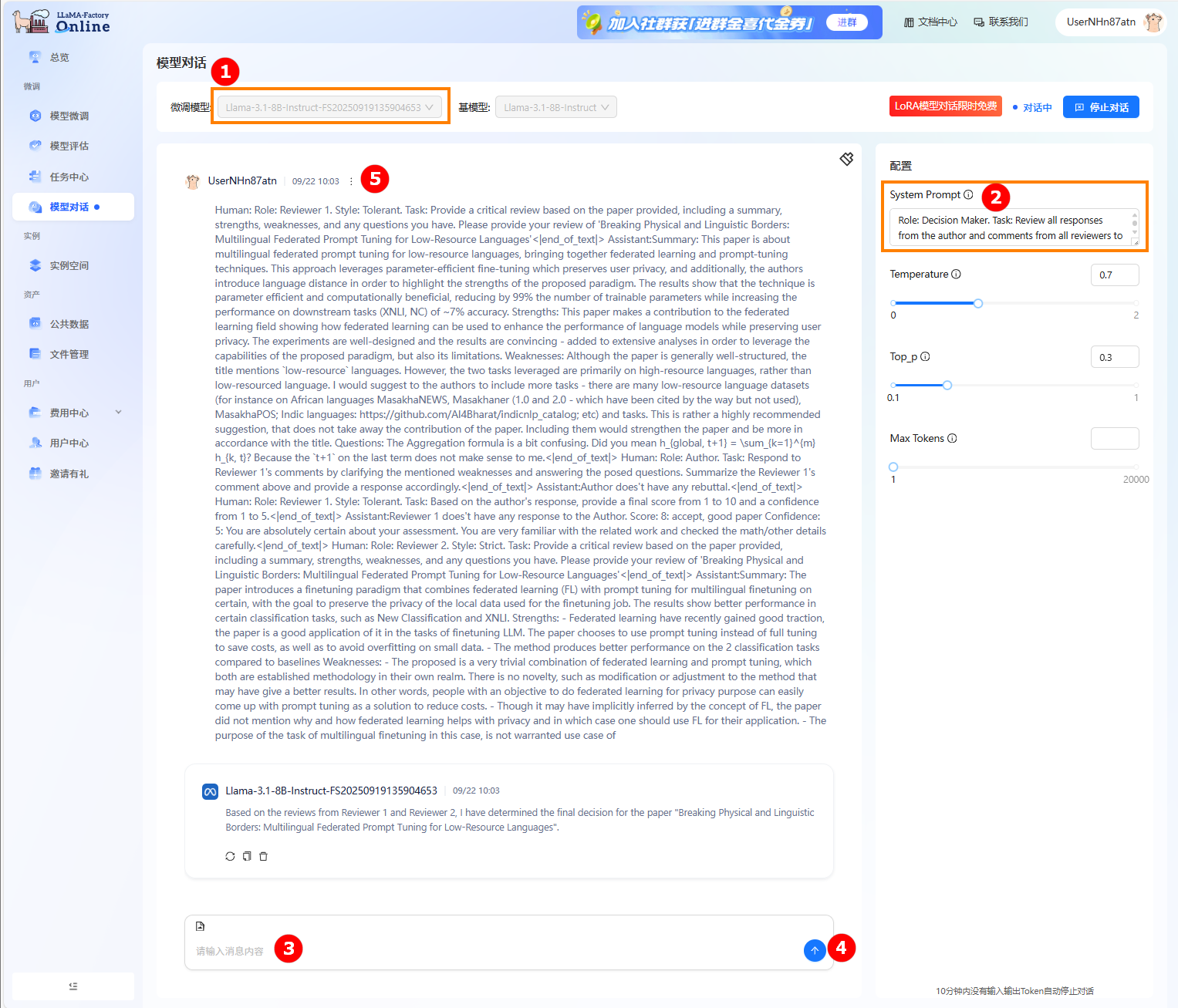
模型对话。
- 点击左侧导航栏“模型对话”按钮进入模型对话页面。
- 在微调模型处选择步骤3中显示的模型名称,如下图高亮①所示。点击开始右上角“开始对话”,跳出弹窗“LORA模型对话限时免费”,点击“开始对话”。
- 在右侧配置栏的“System Prompt”处输入提示词,如下图高亮②所示。在输入框中输入问题(高亮③),点击发送(高亮④);在对话框中查看对话详情,如下图高亮⑤所示。
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
单击上图“开始微调”按钮,进入[配置资源]页面,选择GPU资源,卡数填写
4,点击“启动”,如下图所示。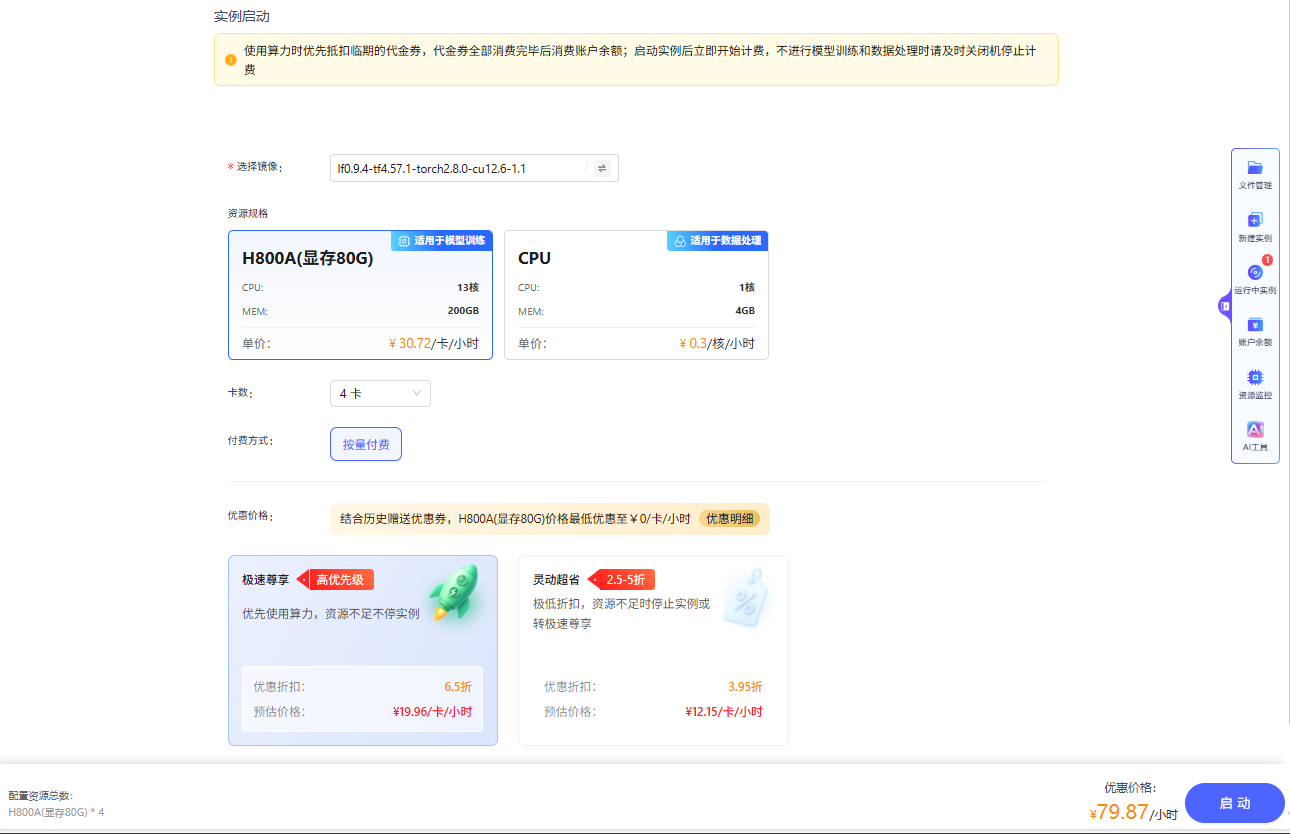
-
待实例启动后,点击[LlamaFactory快速微调模型]页签,进入LlamaFactory Online在线WebUI微调配置页面,语言选择
zh,如下图高亮①所示;模型名称选择Llama-3-8B,如下图高亮②所示;系统默认填充模型路径/shared-only/models/meta-llama/Meta-Llama-3-8B。 -
微调方法选择
lora,如下图高亮④所示;选择“train”功能项,训练方式保持Supervised Fine-Tuning,如下图高亮⑤所示;数据路径保持/workspace/llamafactory/data,如下图高亮⑥所示;数据集选择平台已预置的ICLR_2024,如下图高亮⑦所示。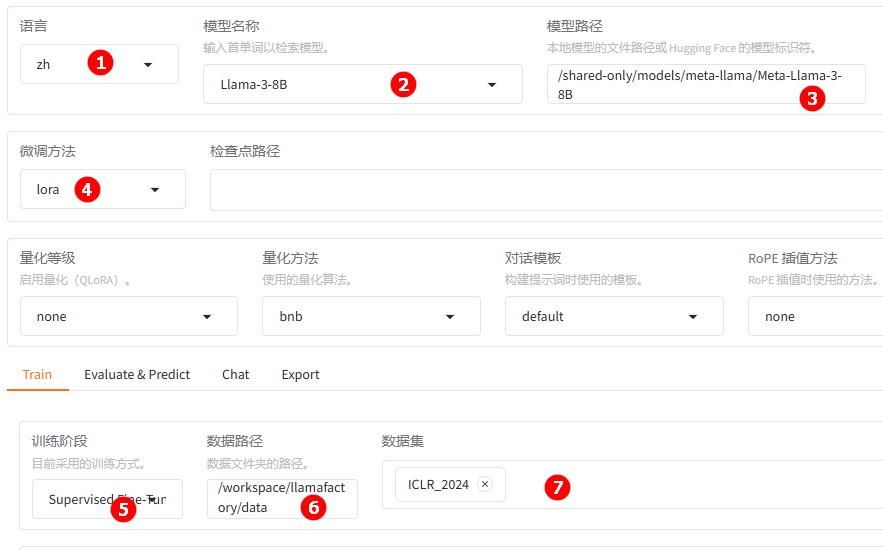
-
(可选)其余参数可根据实际需求调整,具体说明可参考参数说明,本实践中的其他参数均保持默认值。
-
参数配置完成后,点击“开始”按钮启动微调任务。页面底部将实时显示微调过程中的日志信息,例如下图高亮①所示;同时展示当前微调进度及Loss变化曲线。经过多轮微调后,例如下图高亮②所示,从图中可以看出Loss逐渐趋于收敛。微调完成后,系统提示“训练完毕”,例如下图高亮③所示。
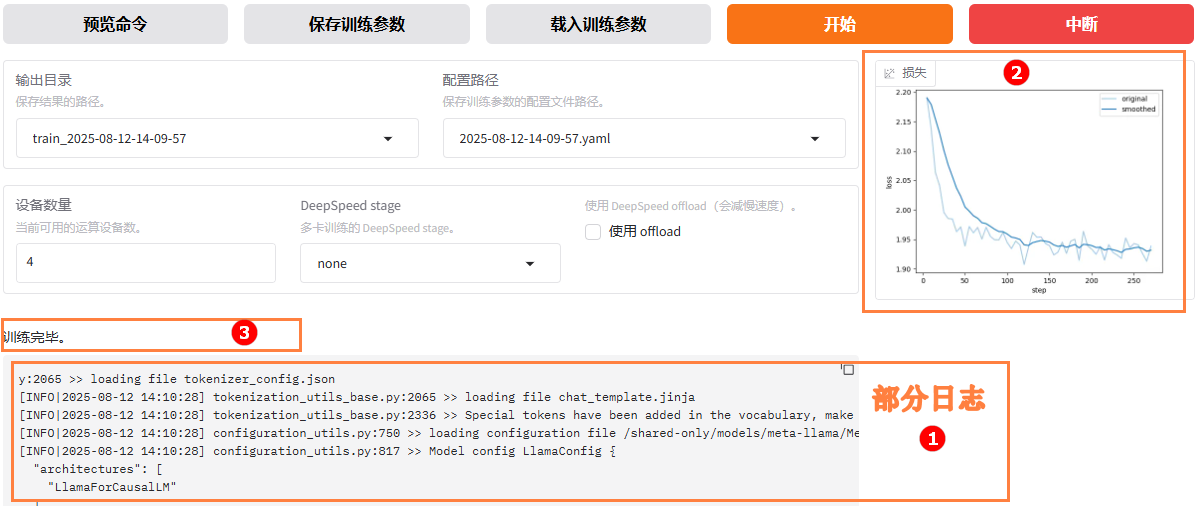
- 微调后模型对话
- 原生模型对话
-
选择上一步骤已经训练完成的检查点路径,如下图高亮①所示;切换至“chat”界面,如下图高亮②所示;单击“加载模型”按钮,如下图高亮③所示;微调的模型加载后,在系统提示词处填入提示词,如下图高亮④所示;在高亮⑤处输入评审意见及作者回复,观察模型回答。
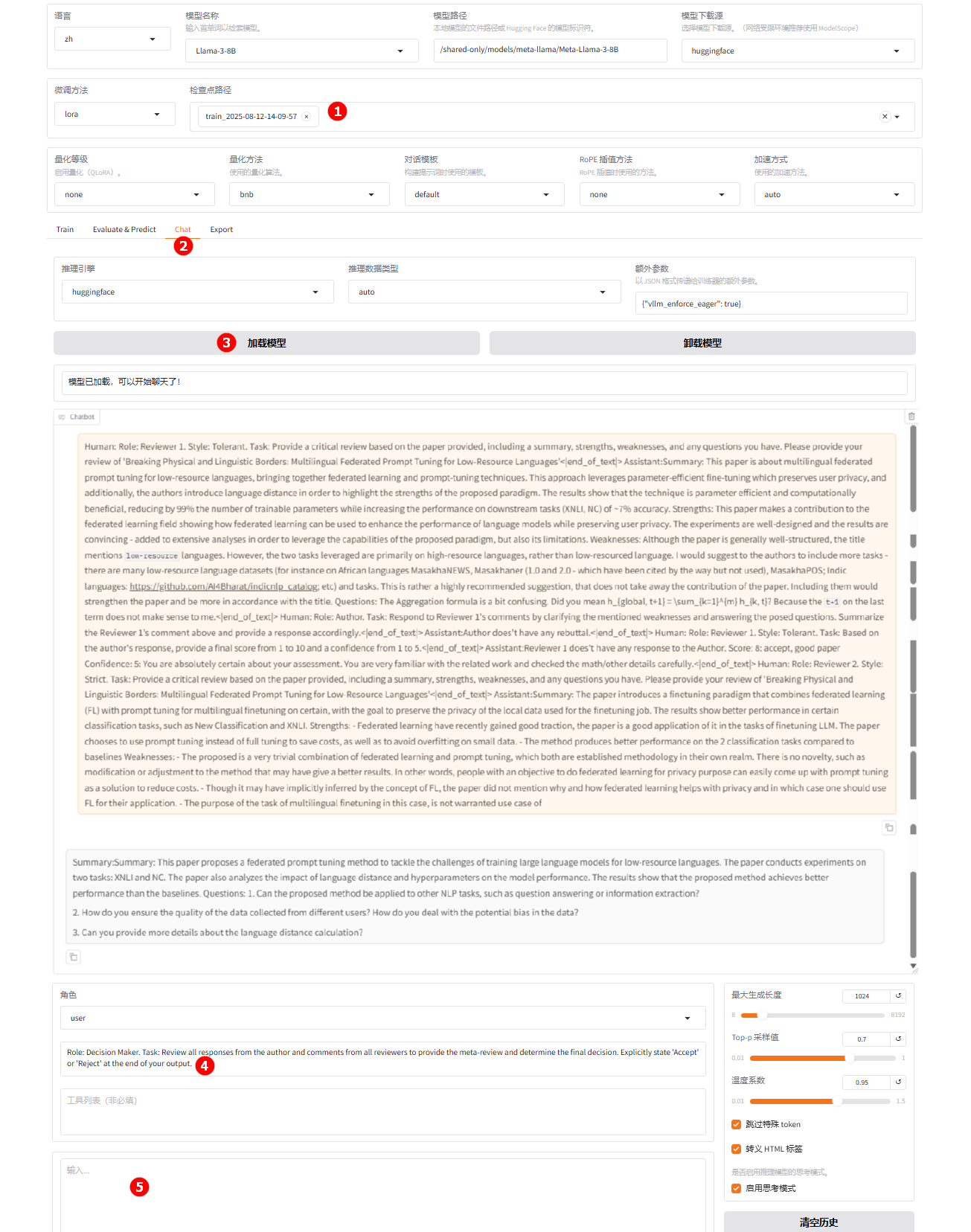
-
清空“检查点路径”中的LoRA配置,如下图高亮①所示;单击下图高亮②所示的“卸载模型”按钮,卸载微调后的模型,模型卸载完成后,单击“加载模型”按钮(高亮③),加载原生的
Llama-3-8B模型进行对话,其余配置保持不变。用户在高亮④处输入评审意见及作者回复,观察模型回答。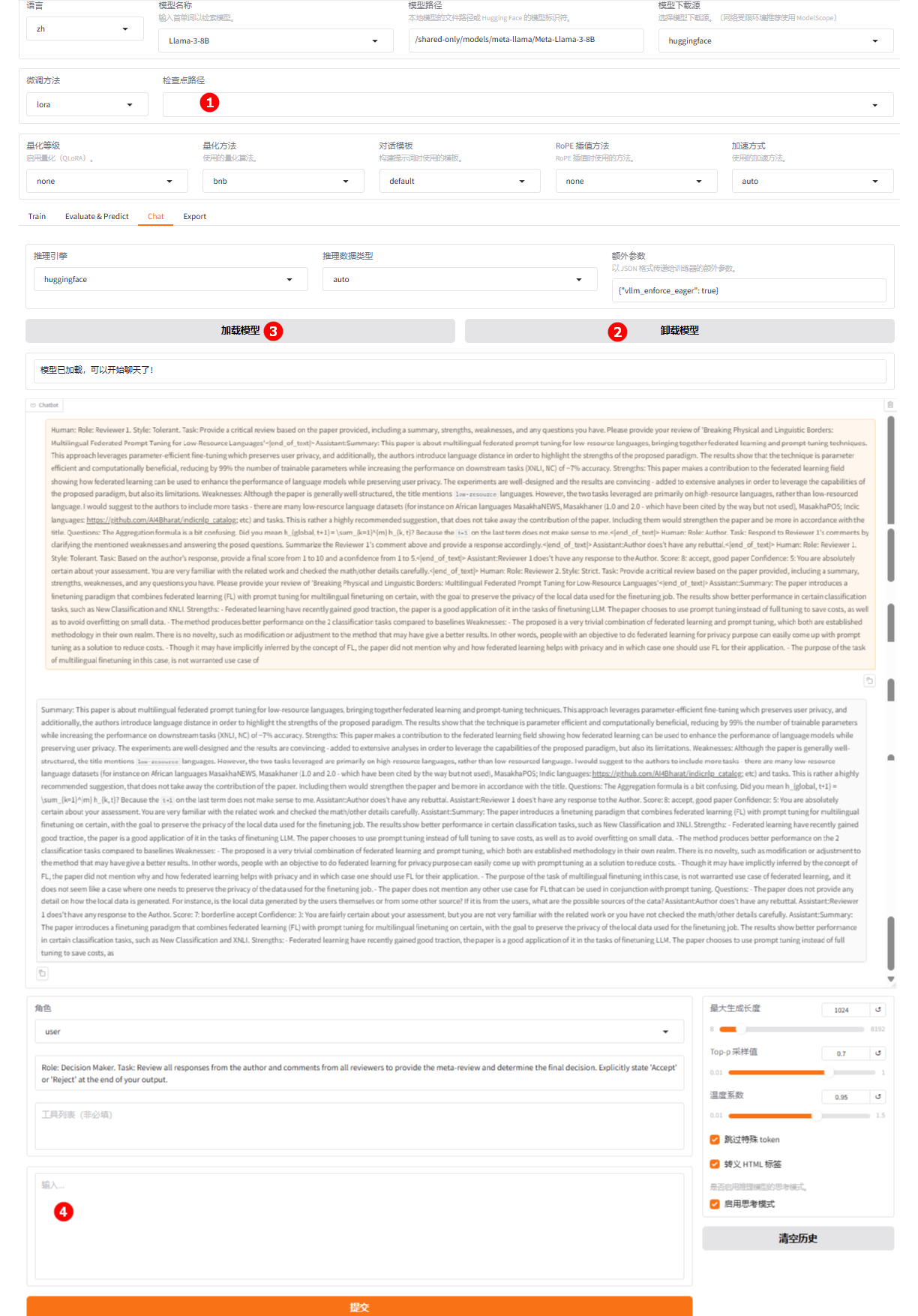
微调后版本展示出更强的学术批判性:提供了对方法、实验、分析的完整总结。针对性的提问引导作者进一步补充可扩展性、数据质量控制、技术细节等关键信息,使读者直接从评论中理解论文核心贡献及潜在改进方向。
- 微调后模型评估
- 原生模型评估
-
切换至“Evaluate & Predict”页面(高亮①),选择微调后模型的检查点路径,例如下图高亮②所示;然后选择平台预置的
iclr_test_data数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。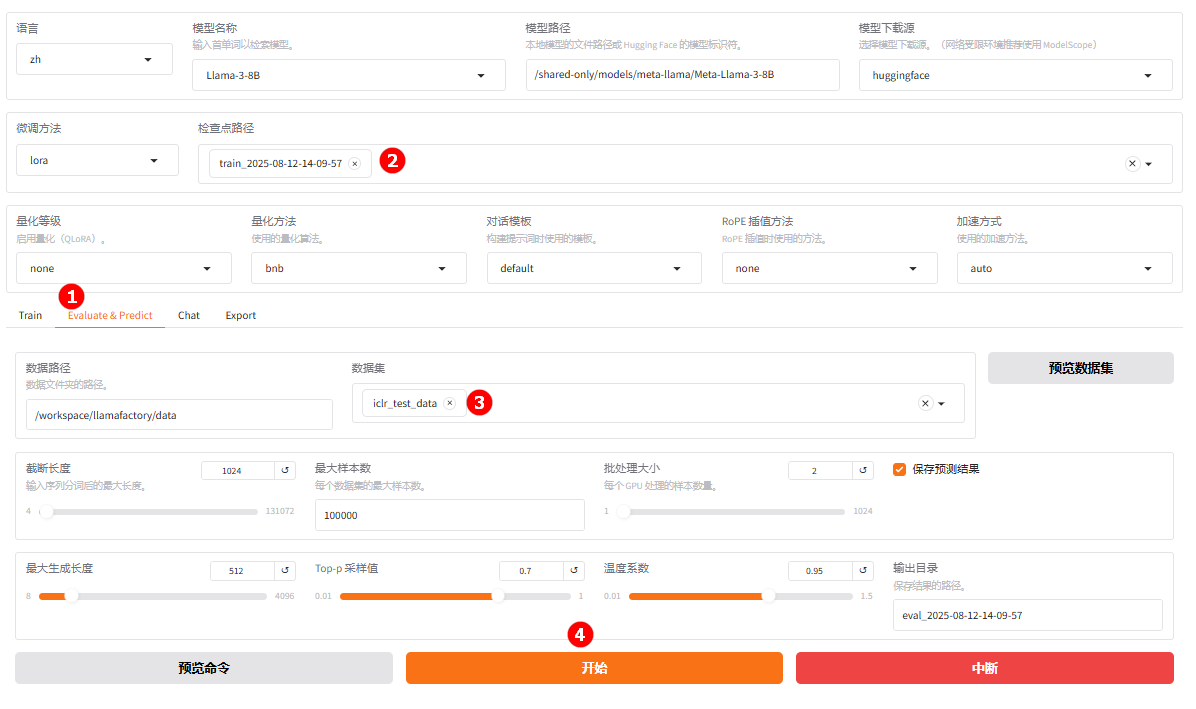
-
参数配置完成后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 20.564883653846152,
"predict_model_preparation_time": 0.0031,
"predict_rouge-1": 21.495878846153843,
"predict_rouge-2": 3.996630769230769,
"predict_rouge-l": 12.27511826923077,
"predict_runtime": 141.4924,
"predict_samples_per_second": 0.707,
"predict_steps_per_second": 0.092
}结果解读:该模型在整体结构上更接近参考文本,相较于原生模型,长句构造和推理效率均有上升。
-
切换至“Evaluate & Predict”页面,清空检查点路径配置,数据集依旧选择平台预置的
iclr_test_data数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。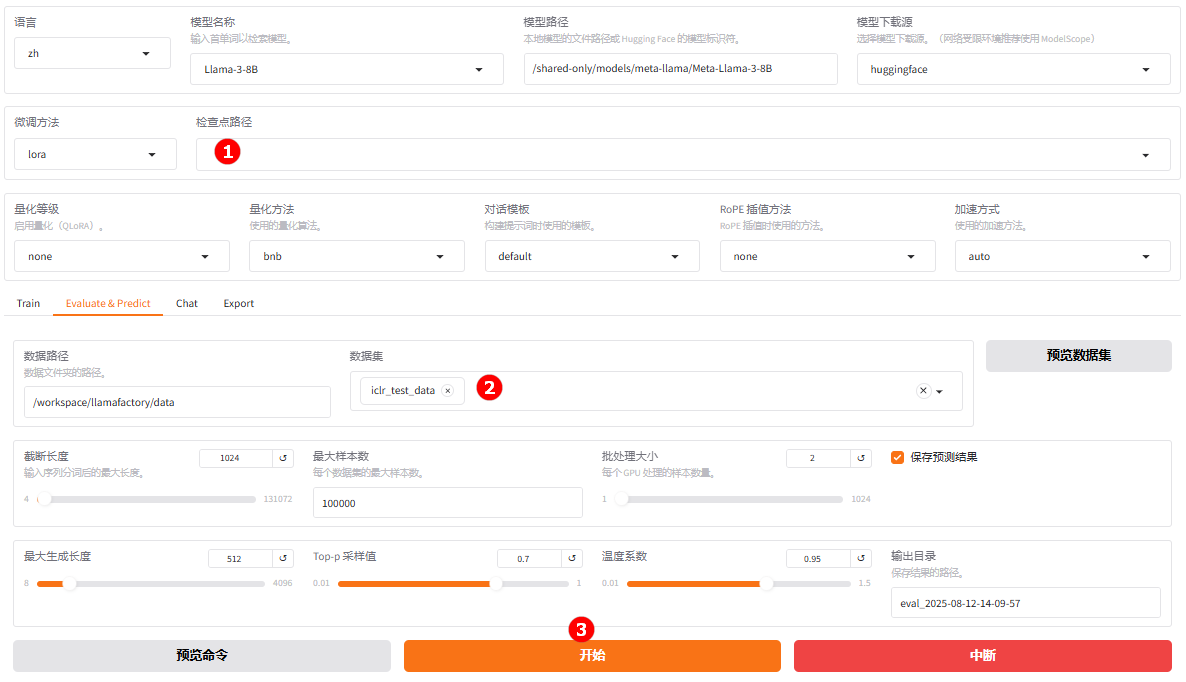
-
完成配置后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 20.09744423076923,
"predict_model_preparation_time": 0.003,
"predict_rouge-1": 22.20353173076923,
"predict_rouge-2": 4.350402884615385,
"predict_rouge-l": 10.506478846153847,
"predict_runtime": 153.3539,
"predict_samples_per_second": 0.652,
"predict_steps_per_second": 0.085
}结果解读:整体结构(ROUGE-L)和用词匹配(BLEU-4)处于较低水平,表明模型生成内容与参考答案在词汇、短语和句子结构层面匹配度较差。当前模型的评估得分整体偏低,尤其在语言流畅性与结构准确性方面表现较弱,生成质量有进一步提升。
对比微调后模型评估与原生模型评估结果可以看出,微调后 BLEU-4 和 ROUGE-L 提升,句子整体结构和部分词汇匹配度更好。ROUGE-1 和 ROUGE-2 略降,让模型更自由表达。性能(速度)提升显著,推理效率更高。 适合需要更流畅句子结构且推理速度要求高的场景,但如果任务要求逐词匹配度高(比如摘要评分看重 ROUGE-2),可能还要针对这方面再优化。
总结
用户可通过LlamaFactory Online平台预置的模型及数据集完成快速微调与效果验证。从上述实践案例可以看出,基于Llama3-8B模型,采用LoRA方法在ICLR_2024论文评审意见数据集上进行指令微调后,
模型展示出更强的学术批判性:提问更具针对性,内容更丰富,学术价值更高。
本实践为构建捕捉真实评审的动态迭代和多角色交互特性的评审大模型提供了可复用的技术路径,适用于学术论文评审、回复审稿意见或编辑根据审稿意见给出结论,使论文评审更加公平。 未来可在结构化评审建议、跨学科评审专家、个性化匹配等方面进一步提升。