使用KTransformers低成本微调DeepSeek-V3超大规模MoE模型
DeepSeek-V3-671B是一款性能比肩顶尖闭源模型的6710亿参数开源MoE大模型,它通过创新的MLA和MoE架构在训练上实现了高效稳定,并借助轻量化微调与部署技术,彻底打破了其在个人及中小企业中实际应用的高成本壁垒。
当前,以DeepSeek-V3、Qwen2.5-MoE为代表的开源超大模型正不断突破性能上限,但其千亿级参数与高昂的显卡需求,也为广大研究者和开发者带来了巨大的微调门槛。
为破解这一难题,可以借助LlamaFactory Online平台与专为Transformer模型设计的高效推理工具库KTransformers。该工具库以其轻量、高速和卓越的框架兼容性为核心优势,通过GPU-CPU异构计算、动态显存调度等关键技术,将DeepSeek-V3-671B这类超大规模MoE模型的微调资源需求,从原本必需的十余张H800专业显卡,显著降低至仅需4~8张消费级的RTX 4090显卡与高内存CPU环境,从而在有限资源下实现了巨型模型的轻量化微调。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | DeepSeek-V3-bf16 | 是 | 将DeepSeek-V3-671B模型经过权重转换后的模型以 “DeepSeek-V3-bf16” 命名,总参数量达6710亿,单token仅激活370亿参数,兼顾性能与效率。 |
| 数据集 | identity | 是 | AI助手基础身份礼貌回应数据集。 |
| GPU | H800*8(推荐) | - | 模型规模较大,建议配置足够显存。 |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
使用推荐资源(H800*8)进行实例模式微调时微调过程总时长约2h30min。
操作步骤
步骤一:数据集说明
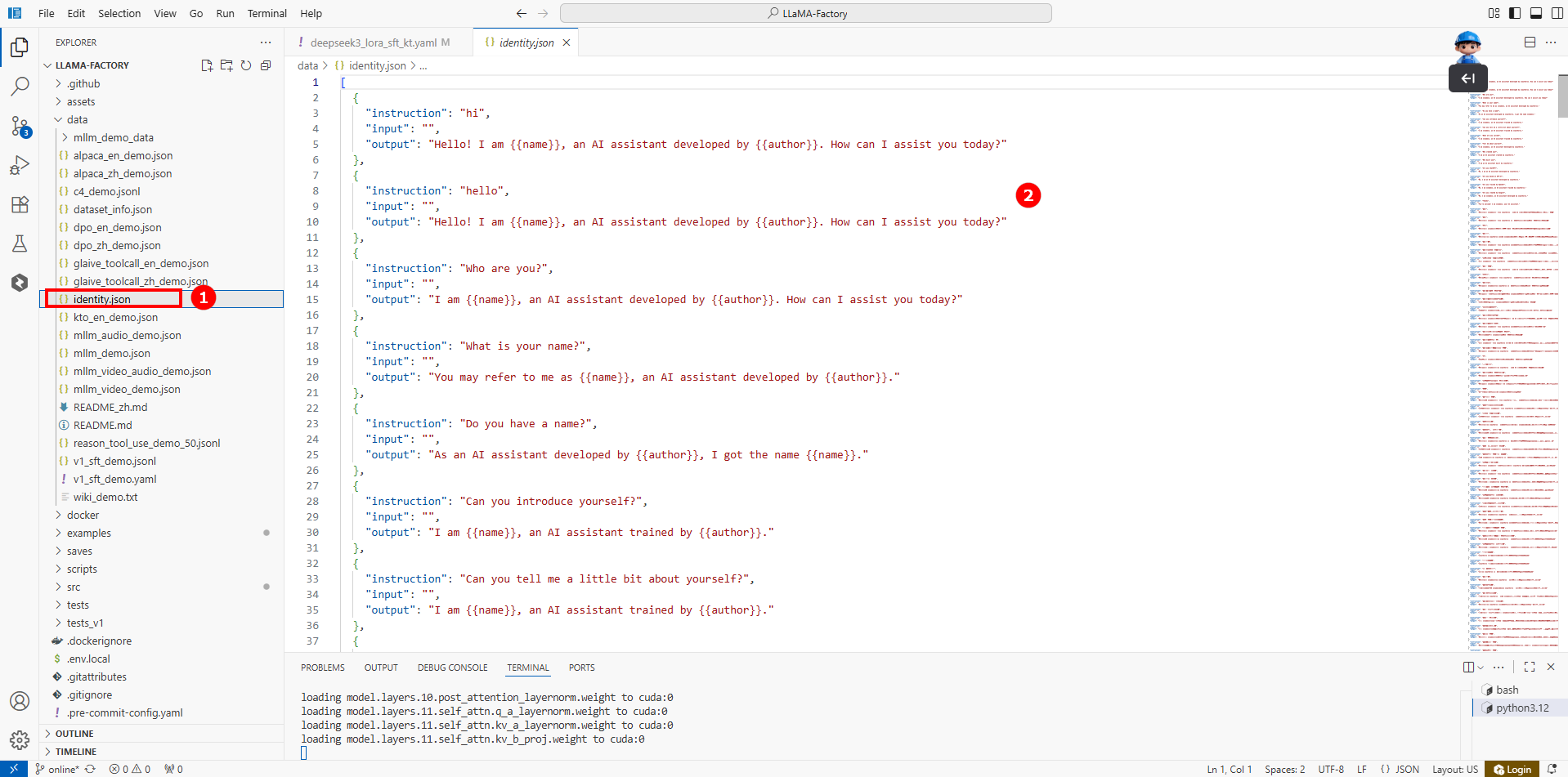
本实践使用的数据集为KTransformers环境中预置的数据集identity,存放在/LlamaFactory/data/identity.json文件中(如图①),共包含100+条QA对话(如图②)。
步骤二:模型训练
LlamaFactory Online支持通过实例模式运行本实践的微调任务,同时LlamaFactory Online已为本实践预置了微调的KTransformers环境,您可以通过 使用预置环境微调 的方式直接进行微调;若您需要自行搭建KTransformers环境进行微调,可参考 自行搭建环境微调 的方式微调,不同方式的微调操作详情如下所示。
- 使用预置环境微调
- 自行搭建环境微调
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
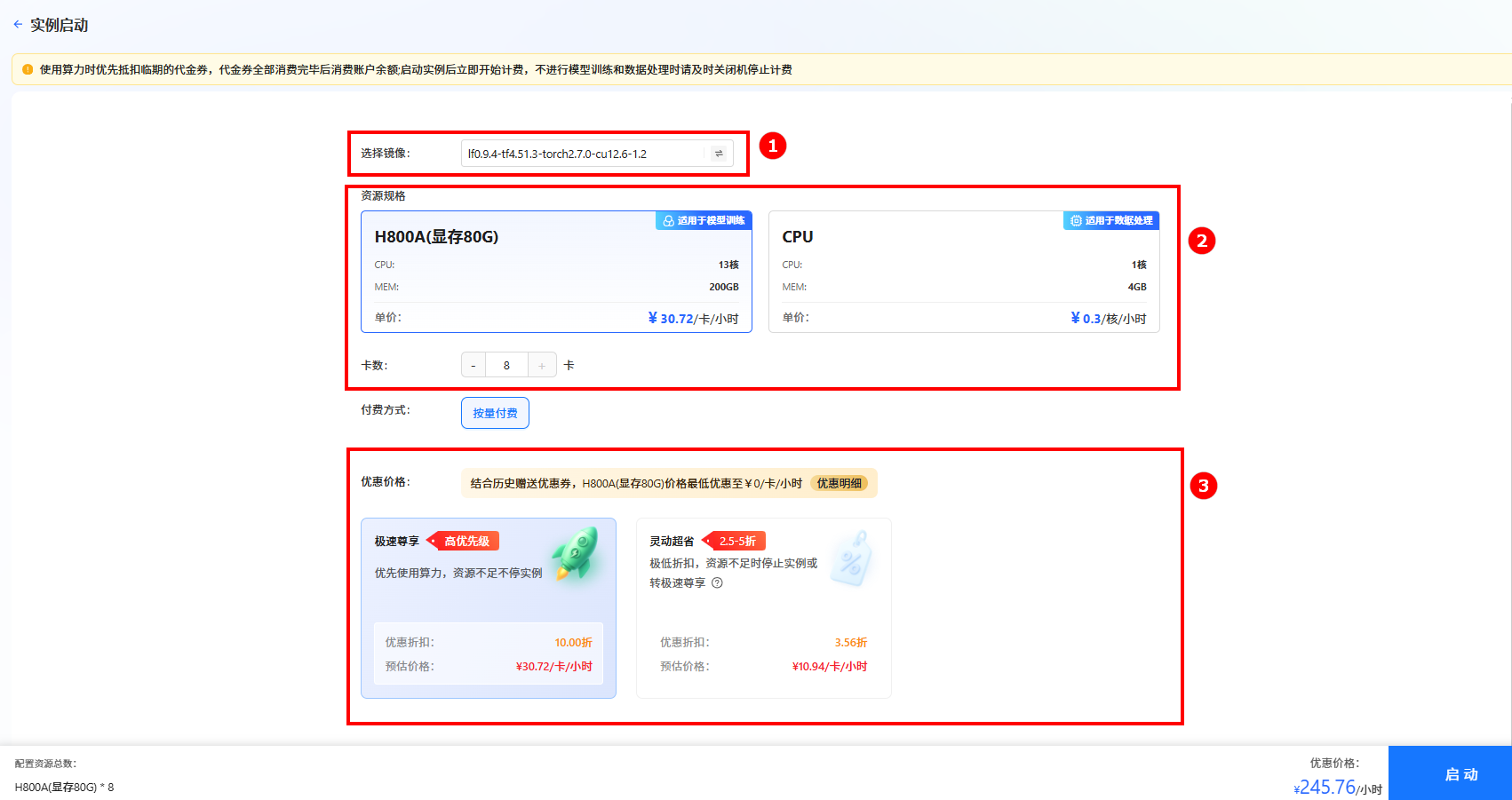
单击上图“开始微调”按钮,进入[实例启动]页面,配置以下参数,然后单击“启动”按钮,启动实例。
- 选择镜像:选择预置镜像
lf0.9.4-tf4.51.3-torch2.7.0-cu12.6-1.2(如图①)。 - 资源配置:选择GPU,推荐卡数为8卡(如图②)。
- 选择价格模式:本实践选择“极速尊享”(如图③),不同模式的计费说明参考计费说明。
 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
- 选择镜像:选择预置镜像
-
实例启动后,单击[VSCode处理专属数据]页签,进入VSCode编辑页面。
-
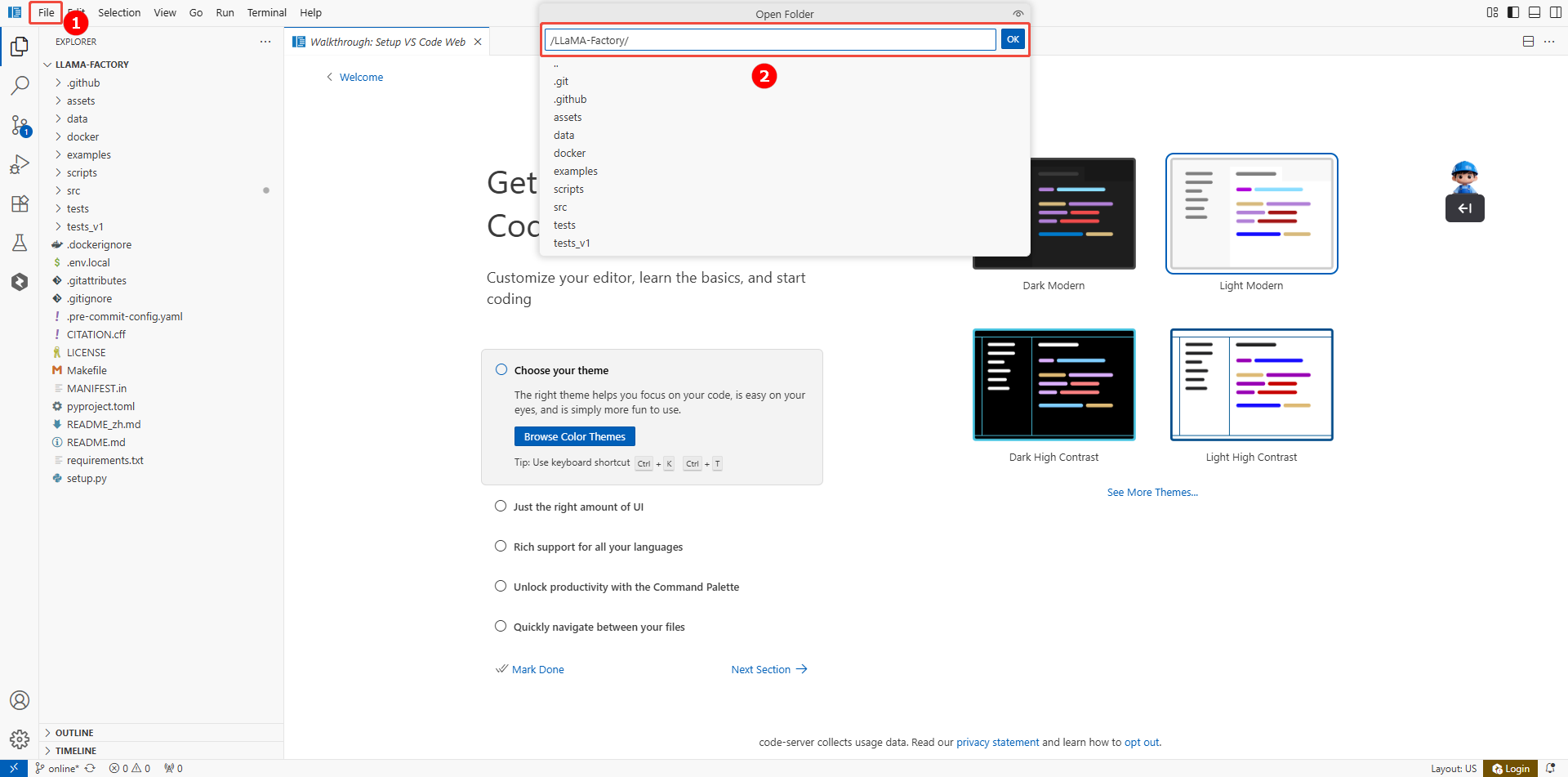
在VSCode页面,单击页面上方菜单栏的“File > Open Folder”(如图①),搜索并进入LlamaFactory目录(如图②),即系统预置的微调环境,如下图所示。
-
配置微调参数。 在/LlamaFactory/examples/train_lora/deepseek3_lora_sft_kt.yaml文件中(如图①),配置如下内容(如图②)。
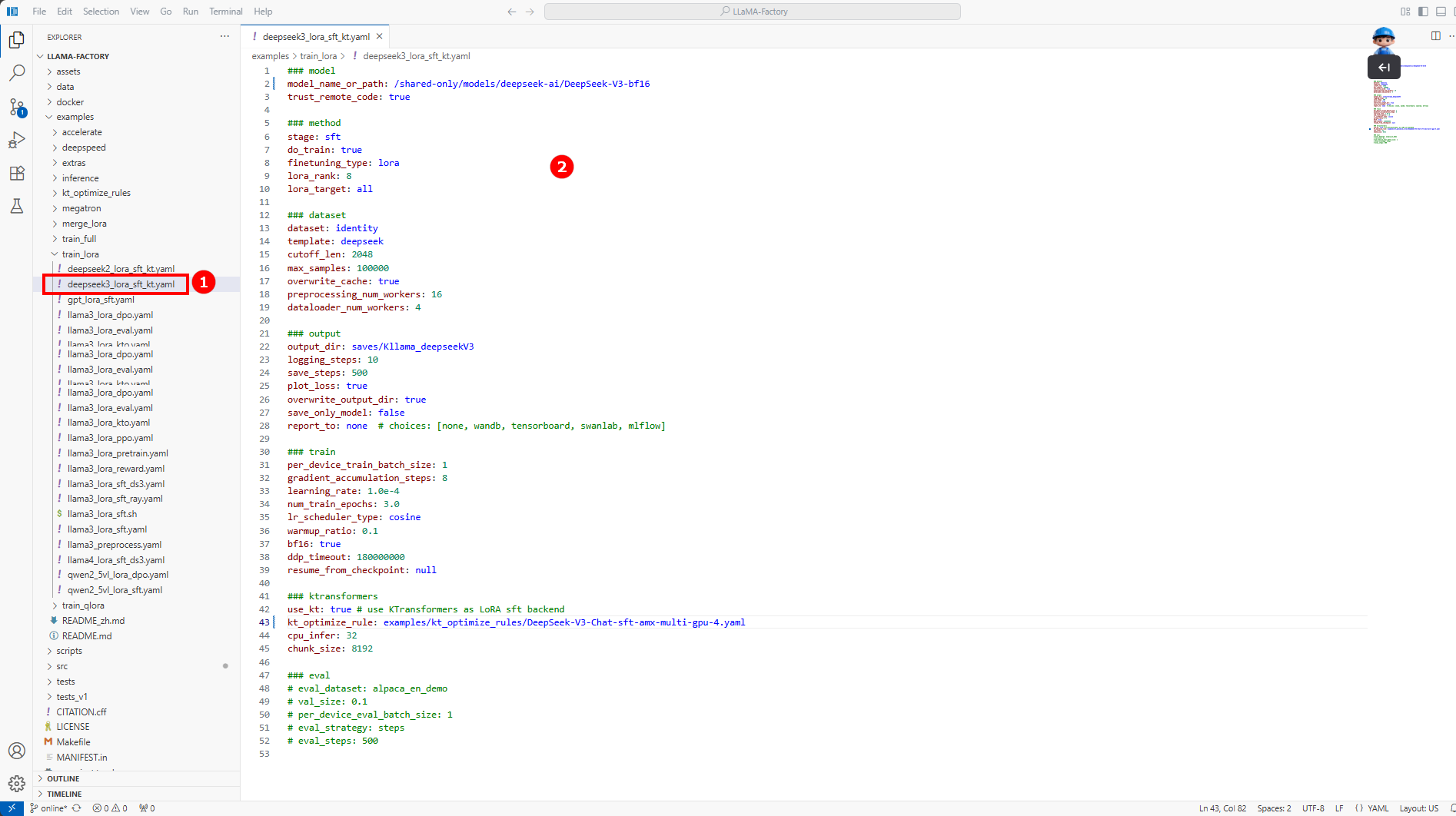
微调参数配置
### model
model_name_or_path: /shared-only/models/deepseek-ai/DeepSeek-V3-bf16
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: identity
template: deepseek
cutoff_len: 2048
max_samples: 100000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: saves/Kllama_deepseekV3
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### ktransformers
use_kt: true # use KTransformers as LoRA sft backend
kt_optimize_rule: examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml
cpu_infer: 32
chunk_size: 8192
### eval
# eval_dataset: alpaca_en_demo
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500您需要根据实际情况配置如下参数:
配置参数 配置说明 配置示例 model_name_or_path 训练用的基模型路径。 /shared-only/models/deepseek-ai/DeepSeek-V3-bf16 dataset 训练使用的数据集名称。 identity output_dir 保存训练输出结果。 saves/Kllama_deepseekV3 kt_optimize_rule 提供了大量默认的YAML文件来控制KTransformers的放置策略。 examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml 其中,对
kt_optimize_rule参数的DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml文件名和功能的解释说明如下:文件名字段 说明 DeepSeek-V3-Chat 对应的不同模型。 sft 微调所用的放置策略,其他为推理所用。 amx 使用AMX指令集进行CPU运算,其他为llamafile。 multi-gpu-4 使用4张GPU卡进行模型并行(显存共担)。 -
在终端执行如下命令,进行模型微调,如下图所示。
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml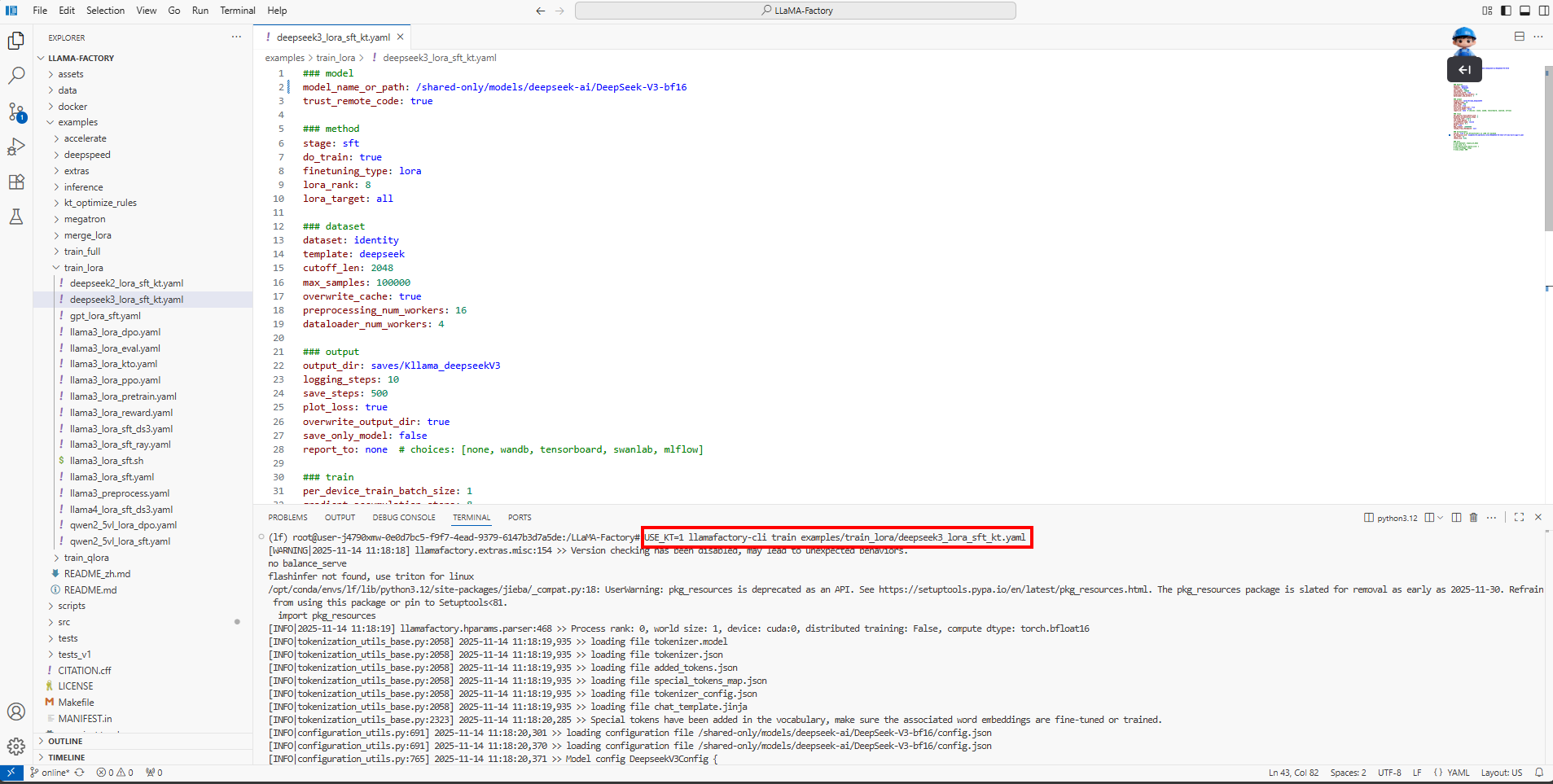
微调结果如下图所示(如图①),表示微调成功。微调后的结果保存至/LlamaFactory/saves/Kllama_deepseekV3/目录,同时在training_loss.png文件中(如图②)展示当前微调的Loss变化曲线。经过多轮微调后,可以看出Loss逐渐趋于收敛(如图③)。
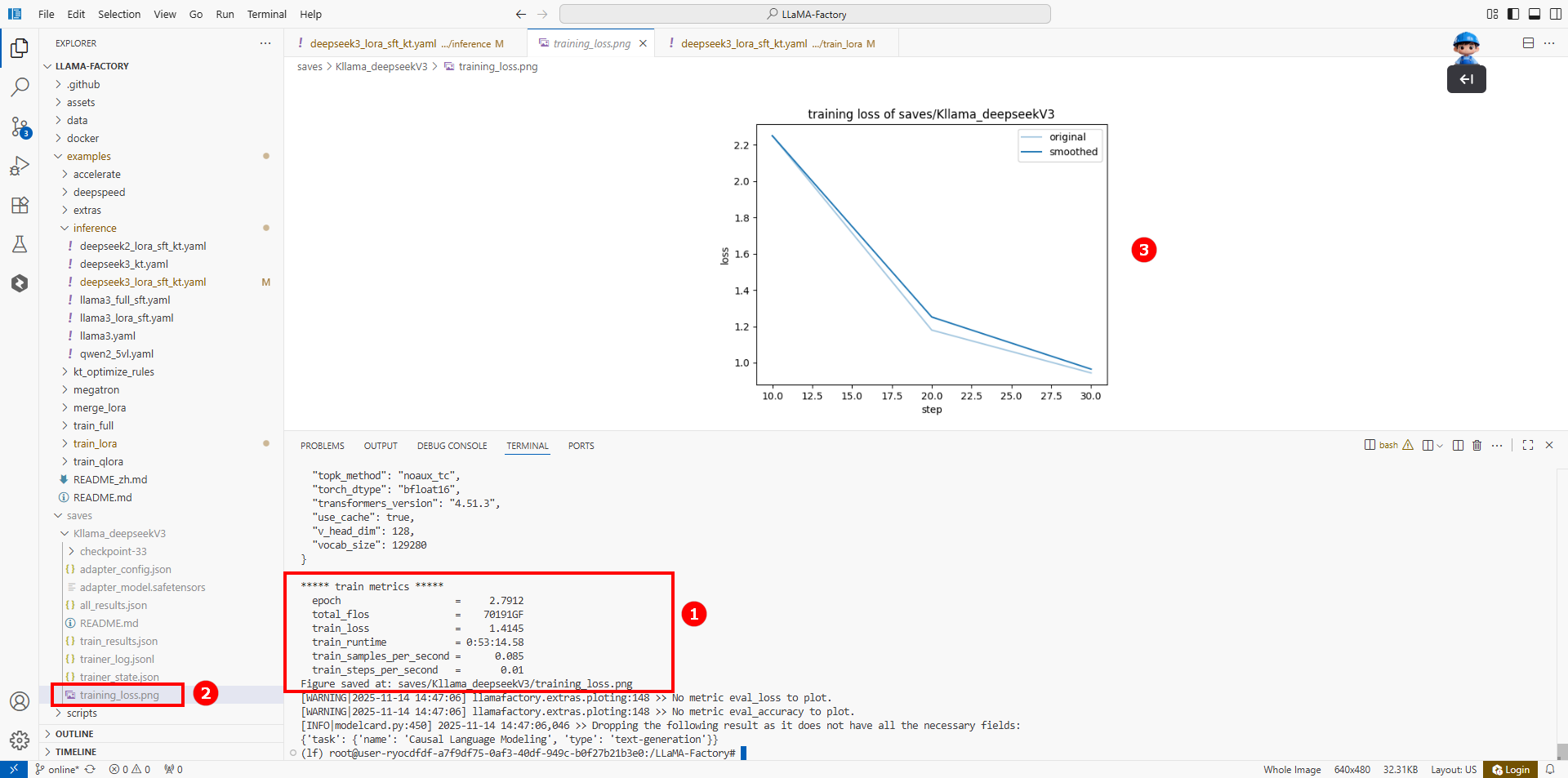
KTransformers环境配置
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,如下图所示。
-
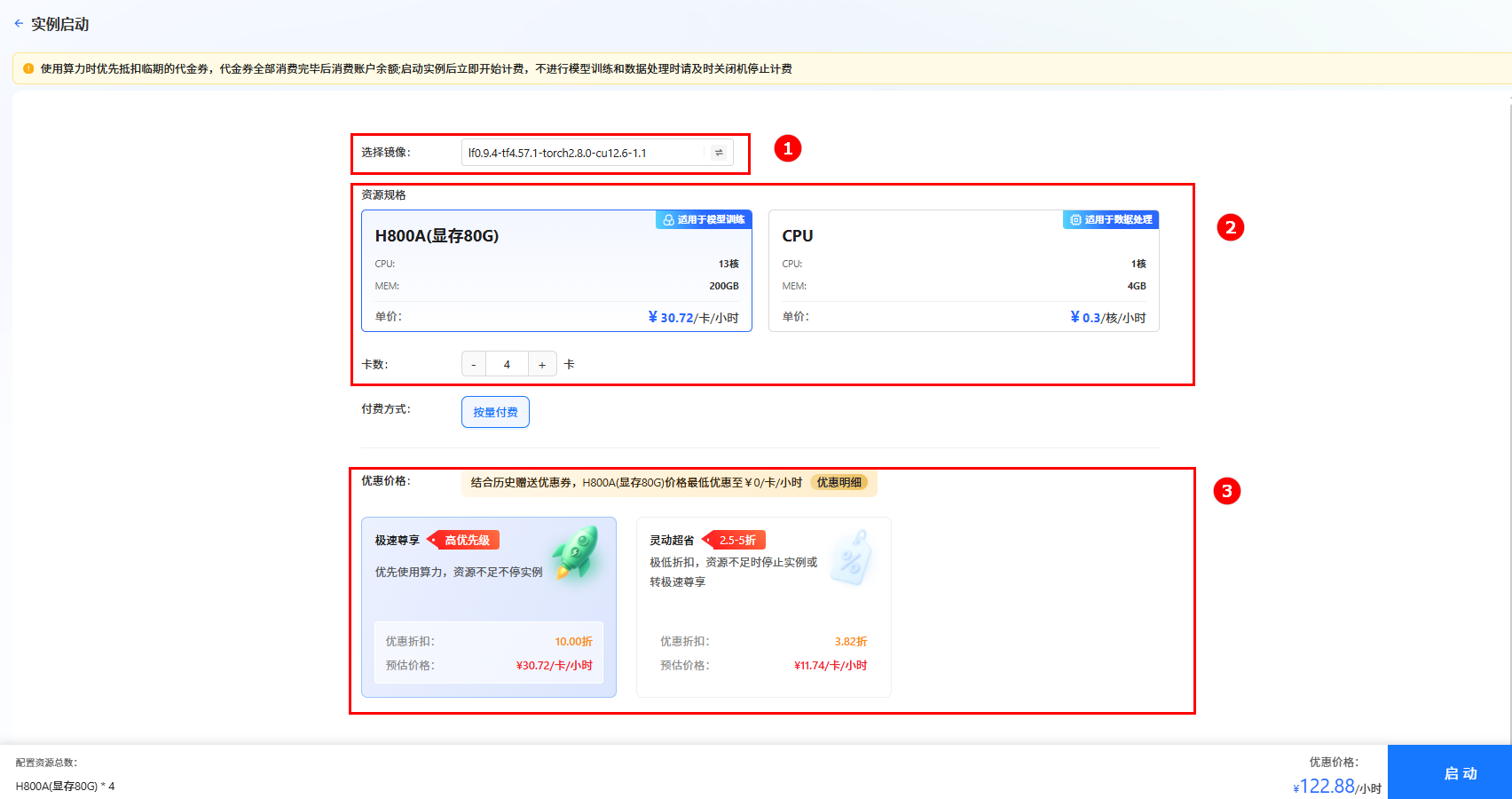
单击上图“开始微调”按钮,进入[实例启动]页面,配置以下参数,然后单击“启动”按钮,启动实例。
- 选择镜像:系统默认镜像
lf0.9.4-tf4.57.1-torch2.8.0-cu12.6-1.1(如图①)。 - 资源配置:选择GPU,推荐卡数为8卡(如图②)。
- 选择价格模式:本实践选择“极速尊享”(如图③),不同模式的计费说明参考计费说明。
 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
- 选择镜像:系统默认镜像
-
实例启动后,单击[VSCode处理专属数据]页签,进入VSCode编辑页面。
-
配置环境并安装依赖项。
a. 在VSCode页面,单击页面上方菜单栏的“Terminal > New Terminal”,新建一个终端。
b. 执行如下命令,为KTransformers单独创建一个虚拟环境并激活该环境。
conda create -n Kllama python=3.12
conda activate Kllamac. 执行如下命令,安装Linux系统下的标准库和GCC编译器依赖,通常用于解决KTransformers安装/运行时的 “缺失libstdc++”、“编译器版本不兼容” 等问题。
conda install -y -c conda-forge libstdcxx-ng gcc_impl_linux-64d. 执行如下命令, 安装CUDA 11.8运行时Runtime,用于为KTransformers提供GPU加速支持(KTransformers依赖CUDA实现Transformer模型的高效推理)。
conda install -y -c nvidia/label/cuda-11.8.0 cuda-runtimee. 执行如下命令,下载安装llamafactory。
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.git
cd LlamaFactory
pip install -e ".[torch,metrics]" --no-build-isolation torch==2.7.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/g. 单击链接下载KTransformers,选择“ktransformers-0.4.1+cu128torch27fancy-cp312-cp312-linux_x86_64”版本进行下载。
下载完成后上传至/workspace目录下(如图①),并执行如下命令安装KTransformers(如图②)。
pip install ktransformers-0.4.1+cu128torch27fancy-cp312-cp312-linux_x86_64.whl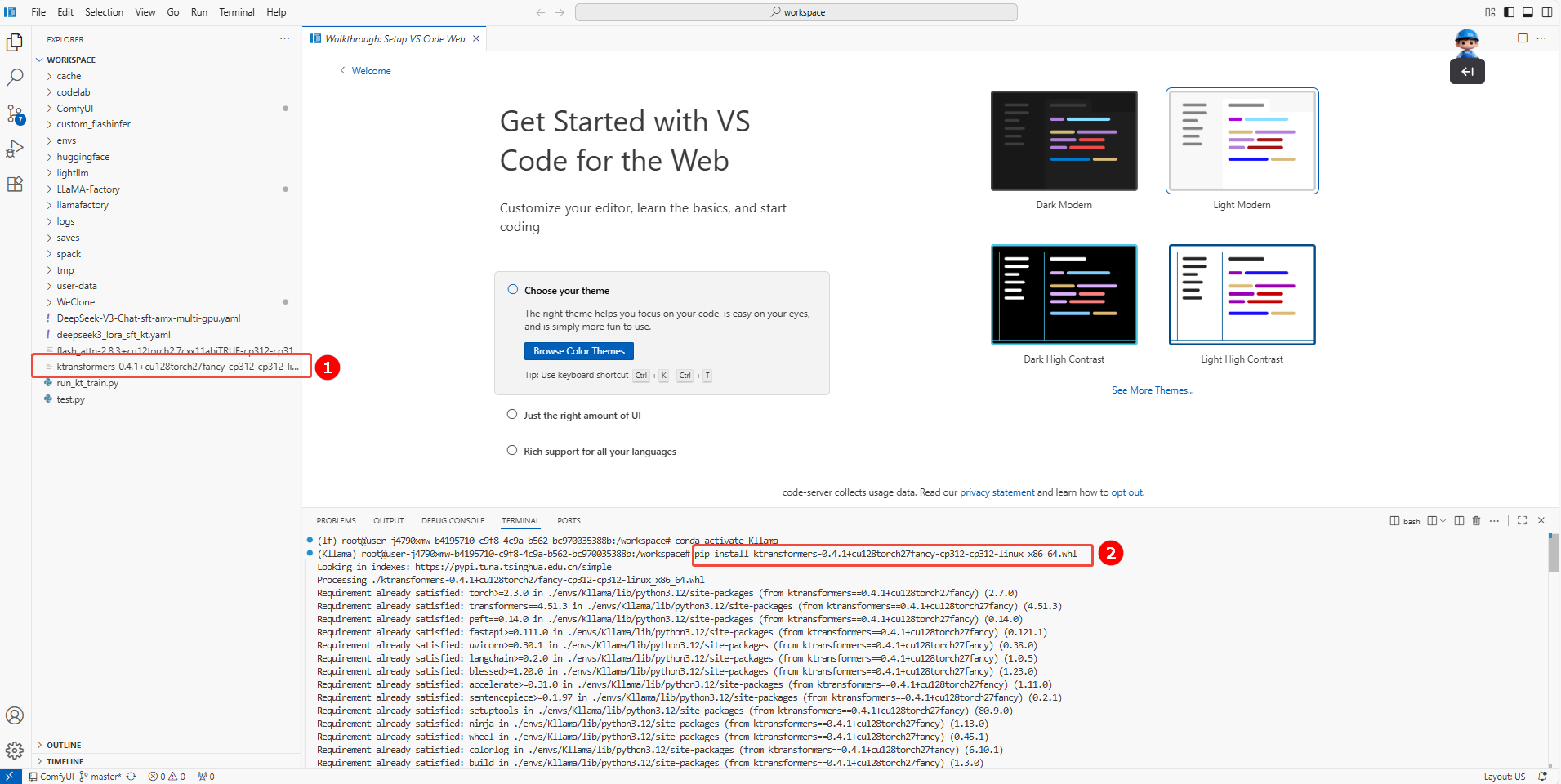 注意
注意整个安装过程大约需要2min。
h. 单击链接下载flashatten,选择“flash_attn-2.8.3+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64”版本进行下载。
下载完成后上传至/workspace目录下(如图①),并执行如下命令安装flashatten(安装②)。
pip install flash_attn-2.8.3+cu12torch2.7cxx11abiTRUE-cp312-cp312-linux_x86_64.whl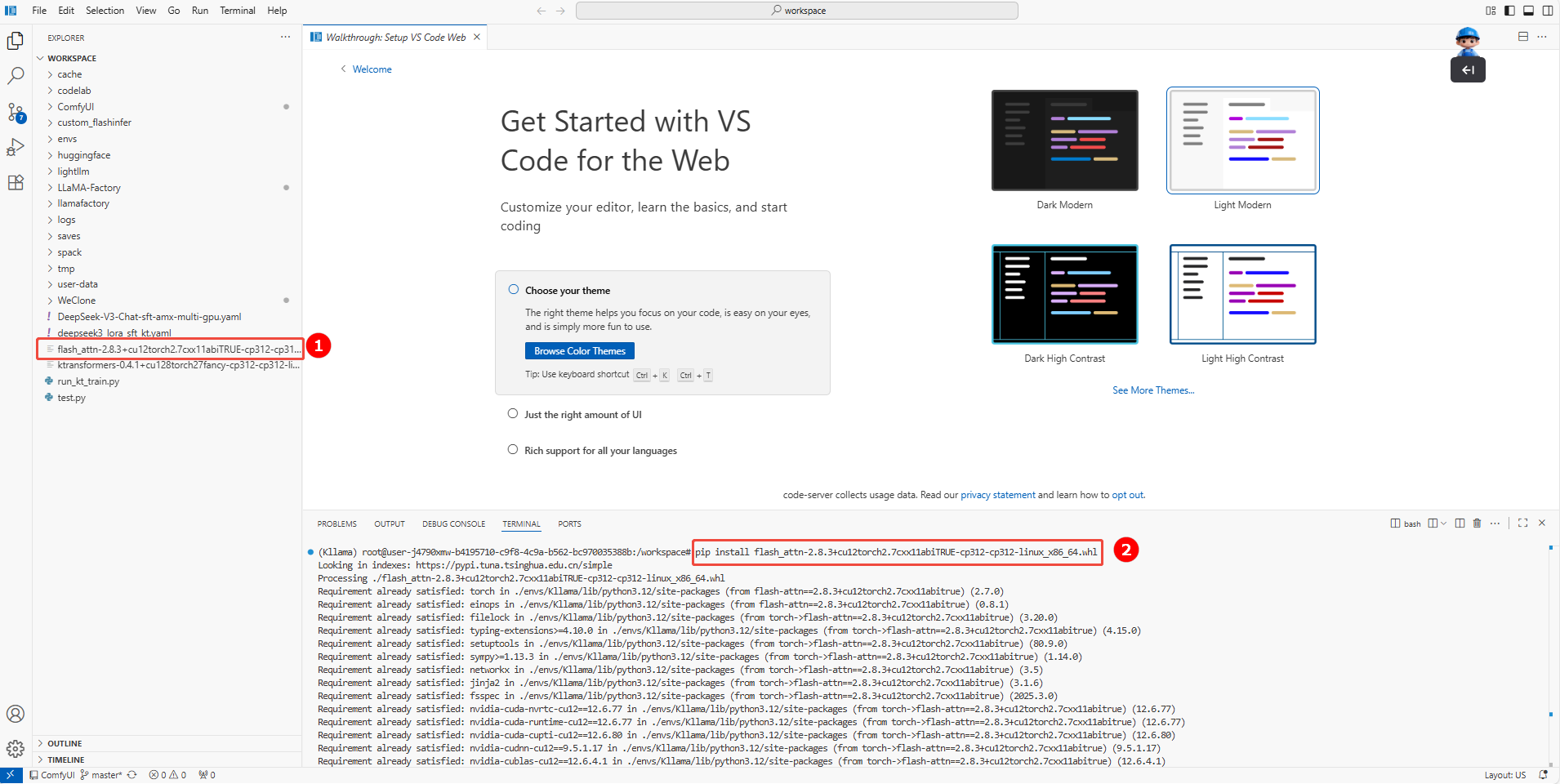
i. (可选)KTransformers会自动使用Triton加速库来运行模型,如果您需要使用flash_infer来加速,执行如下命令,安装flash_infer。
git clone https://github.com/kvcache-ai/custom_flashinfer.git
pip install custom_flashinfer/
模型训练
-
配置微调参数。 在/workspace/LlamaFactory/examples/train_lora/deepseek3_lora_sft_kt.yaml文件中(如图①),配置如下内容(如图②)。
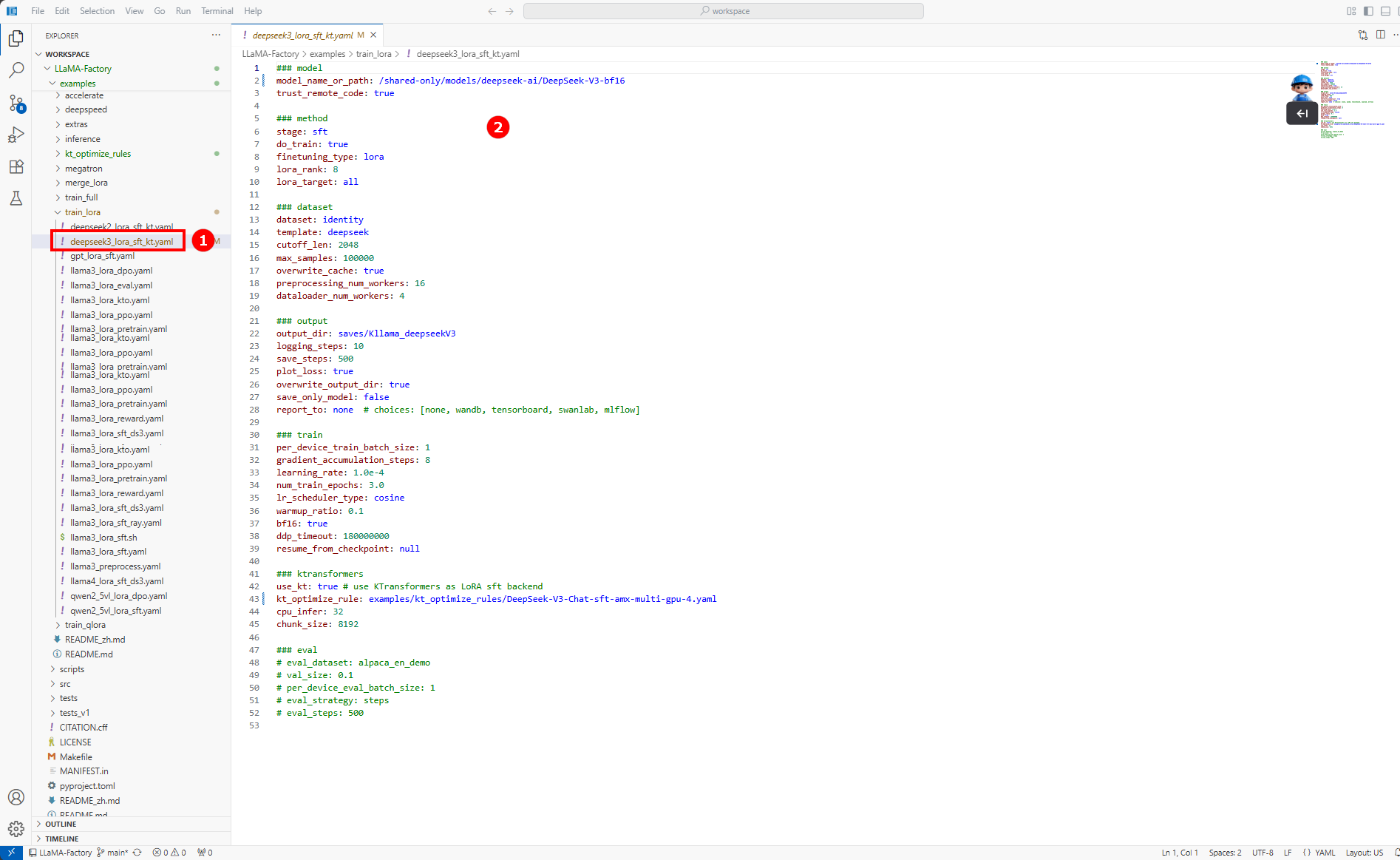
微调参数配置
### model
model_name_or_path: /shared-only/models/deepseek-ai/DeepSeek-V3-bf16
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: identity
template: deepseek
cutoff_len: 2048
max_samples: 100000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: saves/Kllama_deepseekV3
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: null
### ktransformers
use_kt: true # use KTransformers as LoRA sft backend
kt_optimize_rule: examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml
cpu_infer: 32
chunk_size: 8192
### eval
# eval_dataset: alpaca_en_demo
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500您需要根据实际情况配置如下参数:
配置参数 配置说明 配置示例 model_name_or_path 训练用的基模型路径。 /shared-only/models/deepseek-ai/DeepSeek-V3-bf16 dataset 训练使用的数据集名称。 identity output_dir 保存训练输出结果。 saves/Kllama_deepseekV3 kt_optimize_rule 提供了大量默认的YAML文件来控制KTransformers的放置策略。 examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml 其中,对
kt_optimize_rule参数的DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml文件名和功能的解释说明如下:文件名字段 说明 DeepSeek-V3-Chat 对应的不同模型。 sft 微调所用的放置策略,其他为推理所用。 amx 使用AMX指令集进行CPU运算,其他为llamafile。 multi-gpu-4 使用4张GPU卡进行模型并行(显存共担)。 -
在终端执行如下命令,进行模型微调,如下图所示。
conda activate Kllama
cd LlamaFactory
USE_KT=1 llamafactory-cli train examples/train_lora/deepseek3_lora_sft_kt.yaml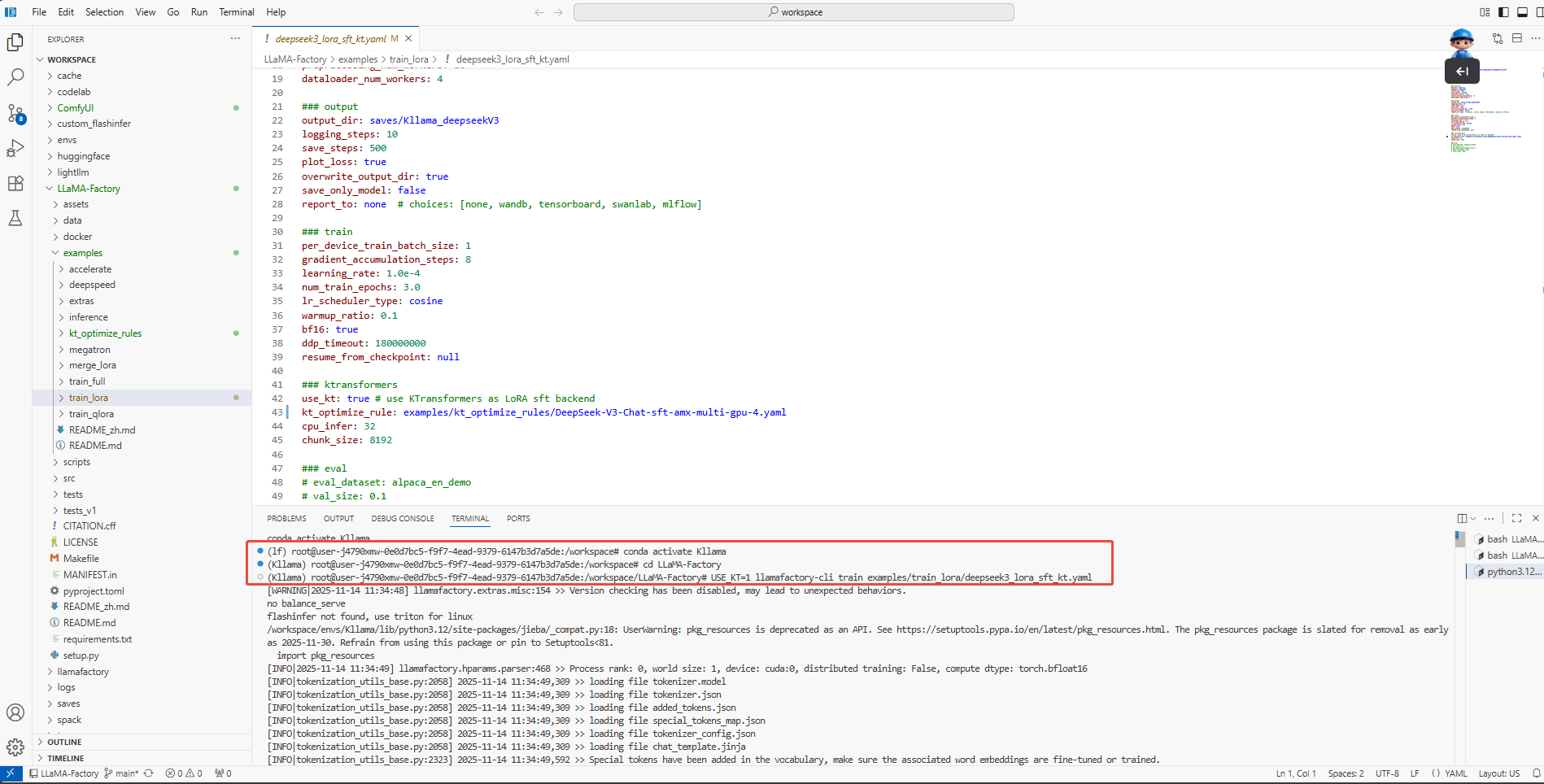
微调结果如下图所示(如图①),表示微调成功。微调后的结果保存至/LlamaFactory/saves/Kllama_deepseekV3/目录,同时在training_loss.png文件中(如图②)展示当前微调的Loss变化曲线。经过多轮微调后,可以看出Loss逐渐趋于收敛(如图③)。
步骤三:模型对话
使用实例模式微调结束后,可以直接在终端进行模型对话。
- 微调后模型对话
- 原生模型对话
-
新建一个终端,然后在/LlamaFactory/examples/inference/deepseek3_lora_sft_kt.yaml配置文件中(如图①),配置如下内容(如图②)。
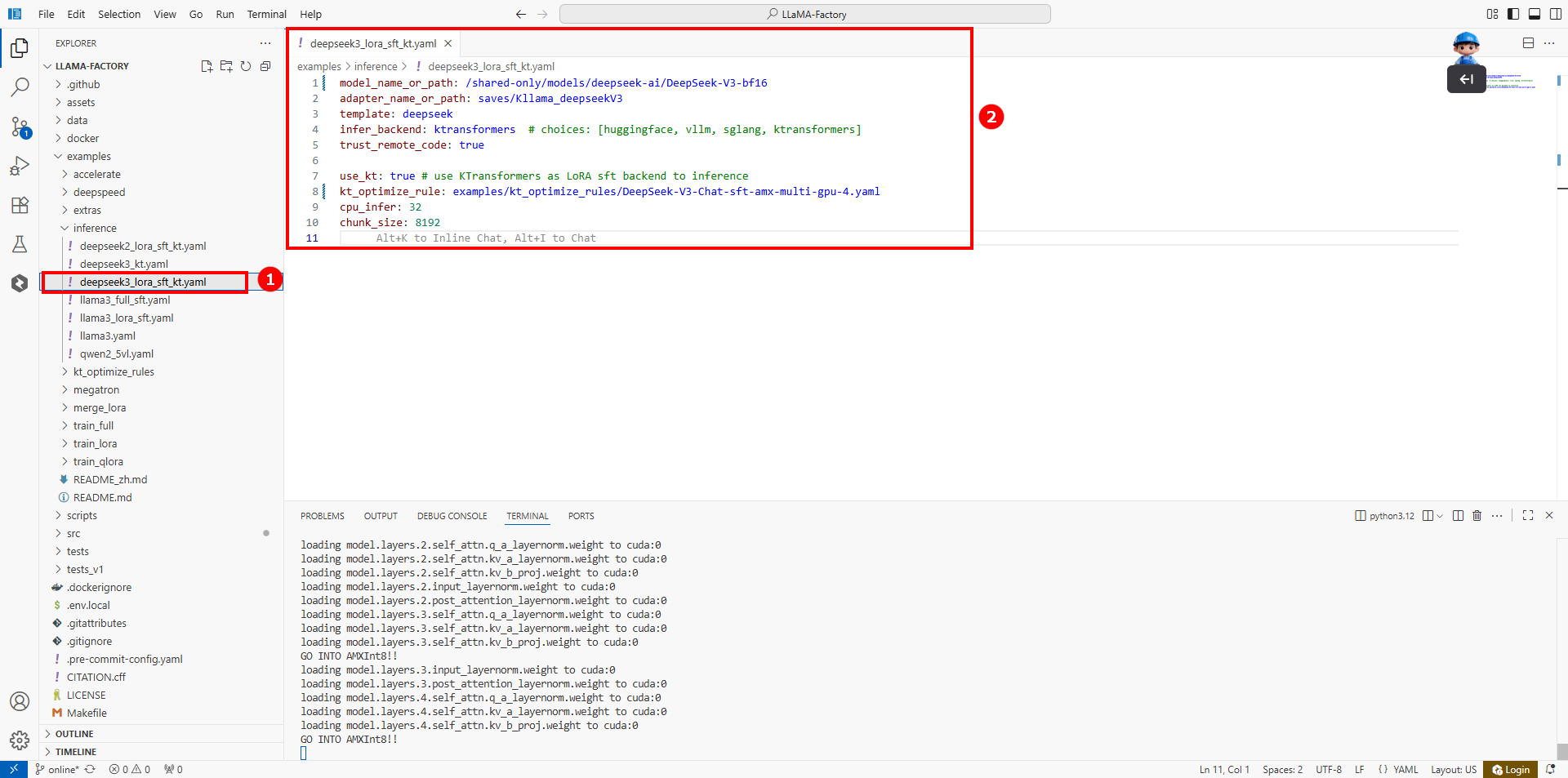
微调后模型对话参数配置
model_name_or_path: /shared-only/models/deepseek-ai/DeepSeek-V3-bf16
adapter_name_or_path: saves/Kllama_deepseekV3
template: deepseek
infer_backend: ktransformers # choices: [huggingface, vllm, sglang, ktransformers]
trust_remote_code: true
use_kt: true # use KTransformers as LoRA sft backend to inference
kt_optimize_rule: examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml
cpu_infer: 32
chunk_size: 8192您需要根据实际情况配置如下参数:
配置参数 配置说明 配置示例 model_name_or_path 基模型路径。 /shared-only/models/deepseek-ai/DeepSeek-V3-bf16 adapter_name_or_path adapter路径(也是SFT的输出路径和后续推理时加载的checkpoint路径)。如不想加载lora adapter,可以将此参数注释掉。 saves/Kllama_deepseekV3 kt_optimize_rule 提供了大量默认的YAML文件来控制KTransformers的放置策略。 examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml -
在终端执行如下命令,进行微调后的模型对话。
llamafactory-cli chat examples/inference/deepseek3_lora_sft_kt.yaml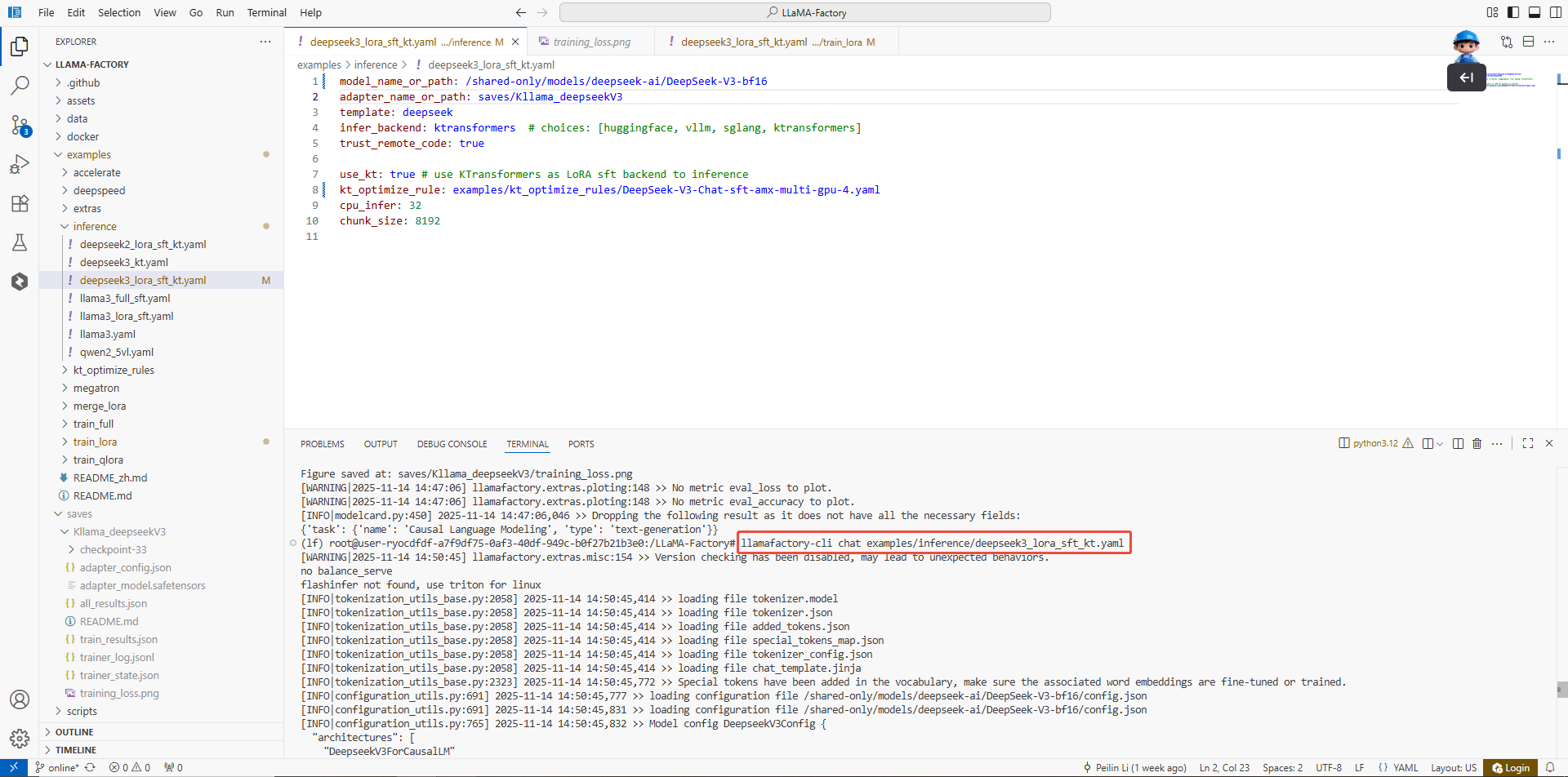
对话结果:
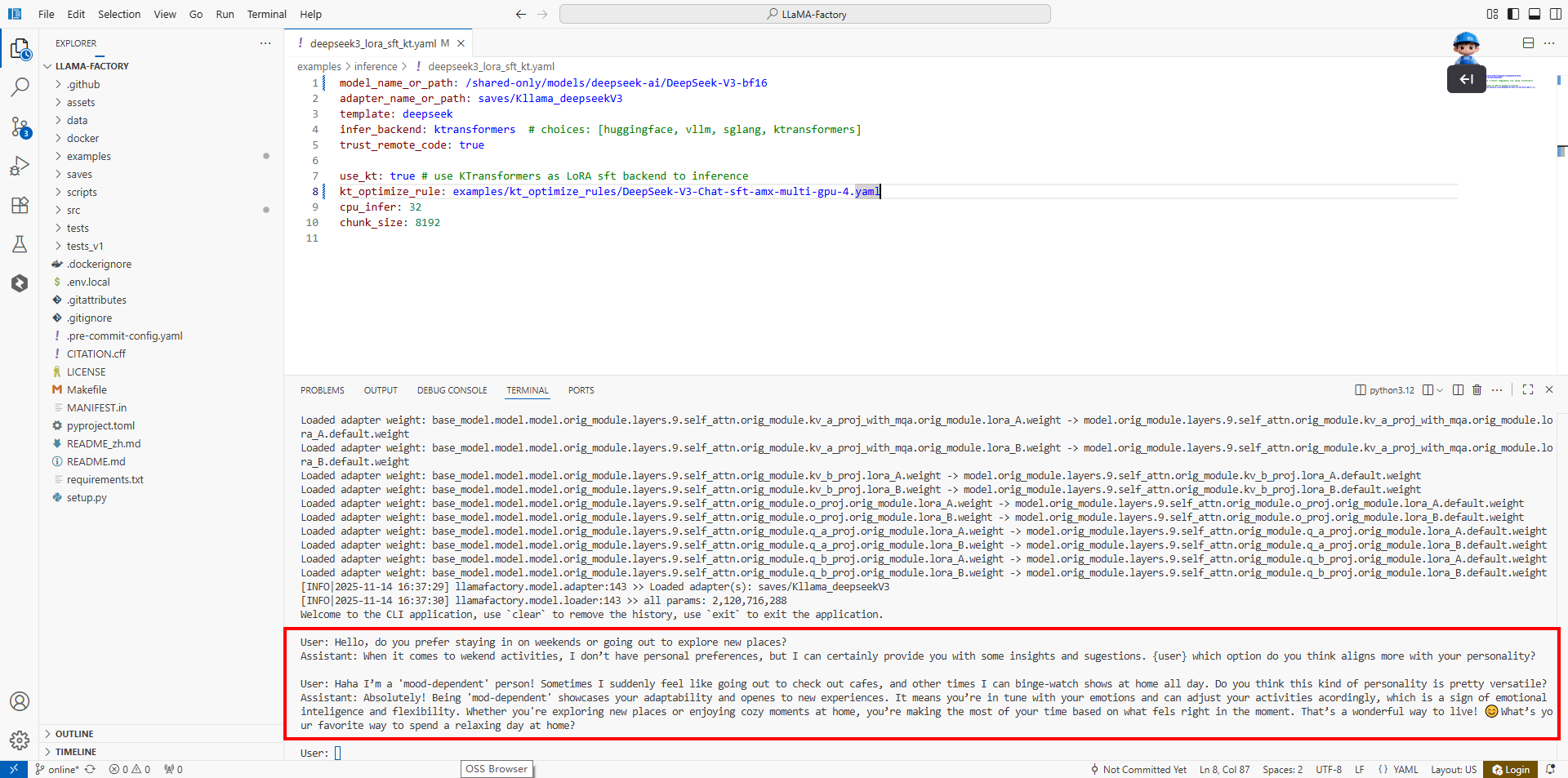
微调后的Assistant回答以亲切互动的风格,针对用户个性化特征主动引导对话,用口语化表达和情感共鸣提升聊天体验。
-
新建一个终端,然后在/LlamaFactory/examples/inference/deepseek3_lora_sft_kt.yaml配置文件中(如图①),配置如下内容(如图②)。

原生模型对话参数配置
model_name_or_path: /shared-only/models/deepseek-ai/DeepSeek-V3-bf16
# adapter_name_or_path: saves/Kllama_deepseekV3
template: deepseek
infer_backend: ktransformers # choices: [huggingface, vllm, sglang, ktransformers]
trust_remote_code: true
use_kt: true # use KTransformers as LoRA sft backend to inference
kt_optimize_rule: examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml
cpu_infer: 32
chunk_size: 8192您需要根据实际情况配置如下参数:
配置参数 配置说明 配置示例 model_name_or_path 基模型路径。 /shared-only/models/deepseek-ai/DeepSeek-V3-bf16 adapter_name_or_path adapter路径,使用原生模型对话时,需要将此参数注释掉。 # adapter_name_or_path: saves/Kllama_deepseekV3 kt_optimize_rule 提供了大量默认的YAML文件来控制KTransformers的放置策略。 examples/kt_optimize_rules/DeepSeek-V3-Chat-sft-amx-multi-gpu-4.yaml -
在终端执行如下命令,进行原生模型对话。
llamafactory-cli chat examples/inference/deepseek3_lora_sft_kt.yaml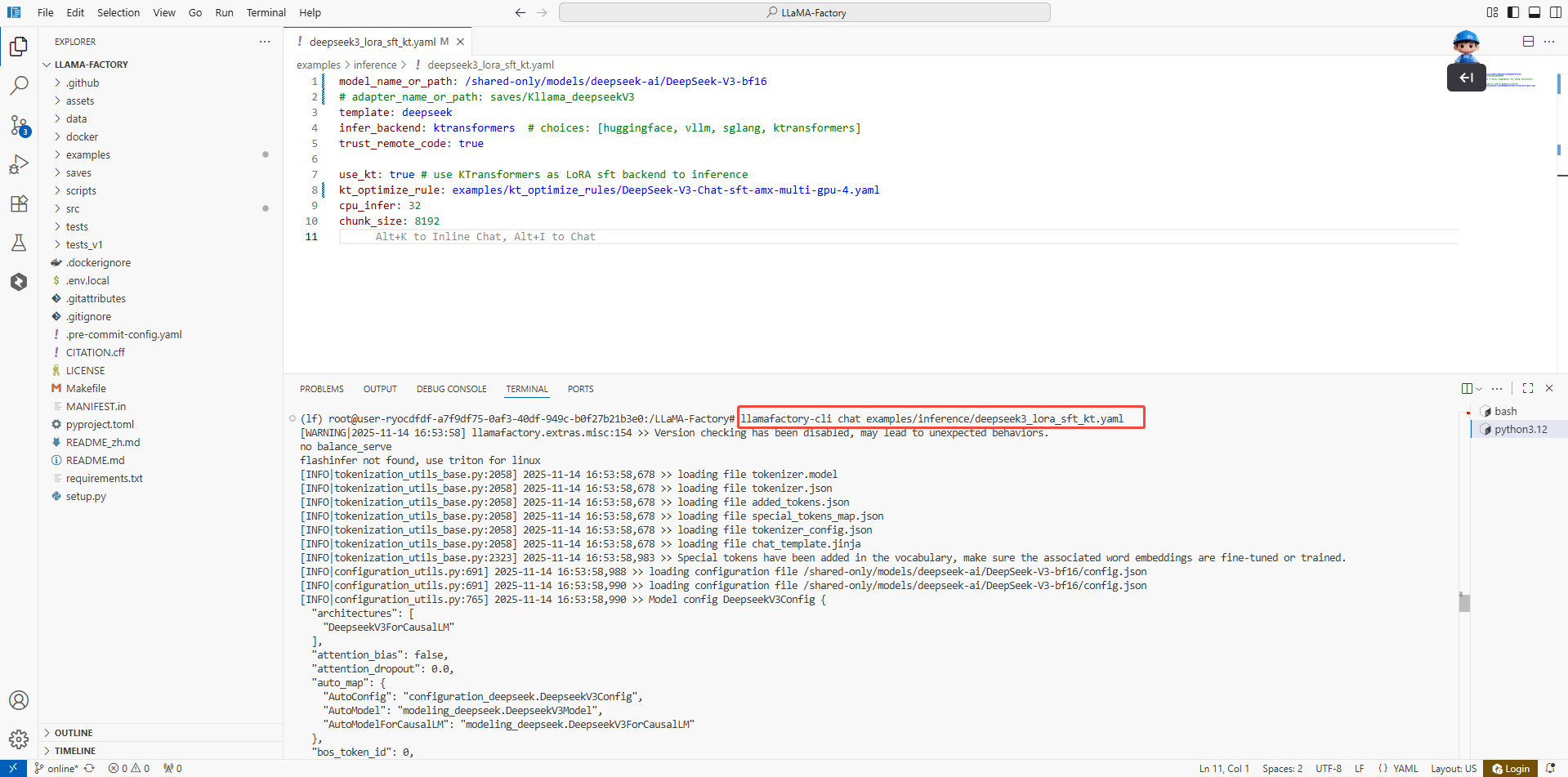
对话结果:

Assistant回答因偏重客观信息输出、语言风格书面化且互动性不足,在日常聊天场景中显得生硬,缺乏针对用户个体的个性化共鸣,较难营造有温度的社交互动体验。
观察微调后的模型与原生模型的对话结果,发现:微调后的回答通过强化互动性、个性化与口语化表达,在日常聊天场景中实现了更具人情味的交流,他主动引导对话节奏,针对用户 “情绪依赖型” 性格精准输出富有共鸣的解读,以亲切自然的口语风格和表情符号,让AI在互动中更像 “懂你的聊天伙伴”,大幅提升了用户在社交对话中的体验感与参与感。
总结
KTransformers与LlamaFactory Online平台的深度融合,以DeepSeek-V3(671B MoE架构)为基模型,通过KT专属AMX加速内核与LoRA轻量化微调技术的协同优化,实现了对超大规模MoE模型的高效低成本定制。该方案在有限硬件条件下,能够快速构建具备领域专业知识与交互逻辑的模型能力,显著降低了微调门槛。其在实践中表现出的“极致显存优化、高速训练效率与低操作复杂度”三位一体优势,为MoE大模型在工业场景中的规模化落地提供了具备高可行性的技术路径。