基于Qwen2.5-14B-Instruct打造WeClone专属的数字分身
WeClone是一款聚焦 “个人数字分身创建” 的工具型项目,核心能力是基于个人导出的聊天记录,打造具有用户专属语言风格与习惯的聊天机器人数字分身。
依托LlamaFactory Online大模型训练微调平台,该平台支持按需自定义创建GPU/CPU实例,可一键启动匹配需求的计算资源。其高性能GPU能满足模型高精度训练需求,同时提供 “JupyterLab”和“VS Code” 等开发环境,方便用户在CPU实例上完成聊天记录的预处理与模型调试。基于此平台,WeClone可调用Qwen2.5-14B-Instruct模型,通过LoRA微调技术,让模型高效学习并复刻用户的语言习惯,使其经微调后的模型可直接接入聊天机器人,实现 “用户专属数字分身” 的实时交互功能。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Qwen2.5-14B-Instruct | 是 | 经过指令微调,参数量约140亿 (14B),支持长上下文对话与高效LoRA微调,适配单/多卡部署,可用于个人数字分身、轻量对话机器人等场景,能精准理解意图并复刻用户表达习惯。 |
| 数据集 | weclone_air_dialogue | 否(提供下载链接) | 航空公司票务客服对话。 |
| GPU | H800*1(推荐) | - | - |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
操作步骤
步骤一:WeClone环境配置
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,例如下图所示。
-
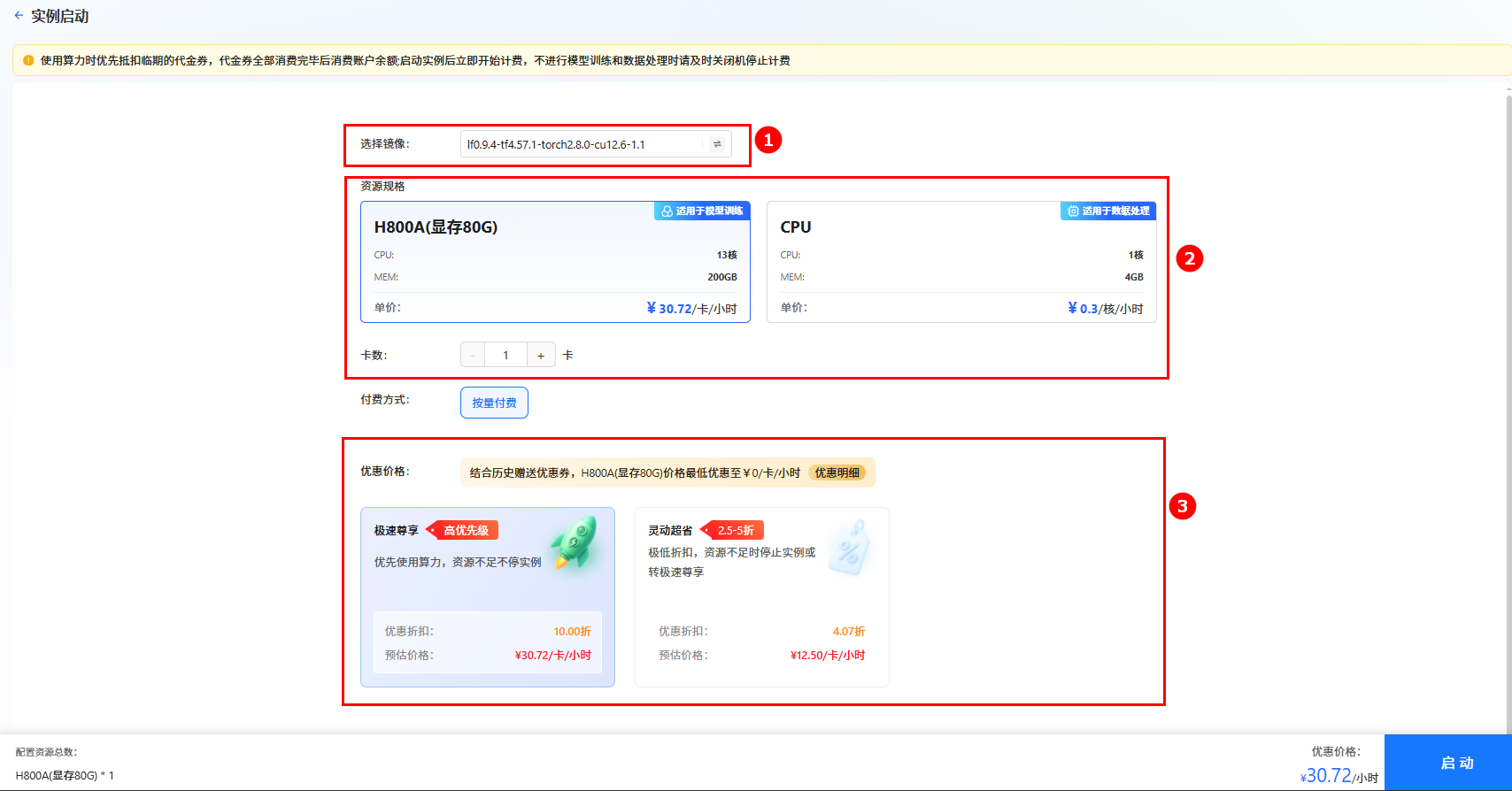
单击上图“开始微调”按钮,进入[实例启动]页面,配置以下参数,然后单击“启动”按钮,启动实例。
- 选择镜像:系统默认镜像
lf0.9.4-tf4.57.1-torch2.8.0-cu12.6-1.1(如图①)。 - 资源配置:选择GPU,推荐卡数为1卡(如图②)。
- 选择价格模式:本实践选择“极速尊享”(如图③),不同模式的计费说明参考计费说明。
 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
- 选择镜像:系统默认镜像
-
实例启动后,单击[VSCode处理专属数据]页签,进入VSCode编辑页面。
-
下载WeClone。
a. 在VSCode页面,单击页面上方菜单栏的“Terminal > New Terminal”,新建一个终端。
b. 然后进入/workspace目录执行以下命令,下载WeClone(如图①),下载完成后默认生成一个WeClone目录(如图②)。
git clone https://github.com/xming521/WeClone.git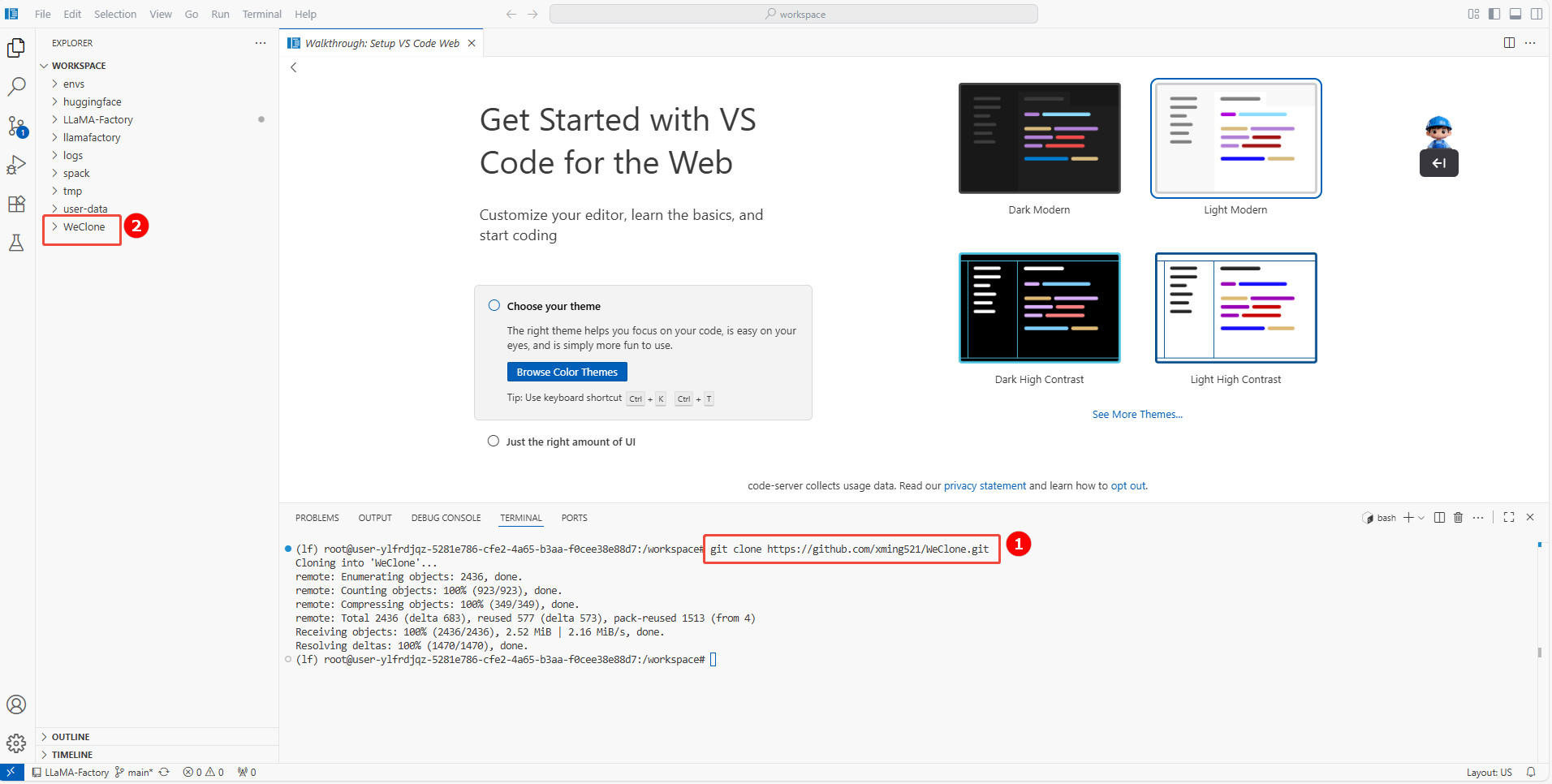
-
配置环境并安装WeClone依赖项。
a. 执行如下命令,为WeClone单独创建一个虚拟环境。
conda create -n weclone python=3.10b. 执行如下命令,激活自定义的环境。
conda activate weclonec. 执行如下命令,进入WeClone目录,在新创建的虚拟环境中安装依赖包。
cd WeClone
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple/提示整个安装过程大约需要2min。
d. 单击下载zh_core_web_sm-3.8.0.tar.gz和en_core_web_sm-3.8.0.tar.gz模型,存放在/workspace/WeClone目录下(如下图所示),然后执行如下命令,安装Spacy中英文模型。
提示在数据预处理中,会使用到Spacy模型,如遇下载缓慢卡顿,可以考虑预先手动上传中/英文语料处理的Spacy模型,并通过指定路径进行安装。本项目预先准备好了
zh_core_web_sm-3.8.0.tar.gz和en_core_web_sm-3.7.1.tar.gz这两个模型文件,通过以下命令分别安装这两个模型:pip install zh_core_web_sm-3.8.0.tar.gz -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install en_core_web_sm-3.8.0.tar.gz -i https://pypi.tuna.tsinghua.edu.cn/simple/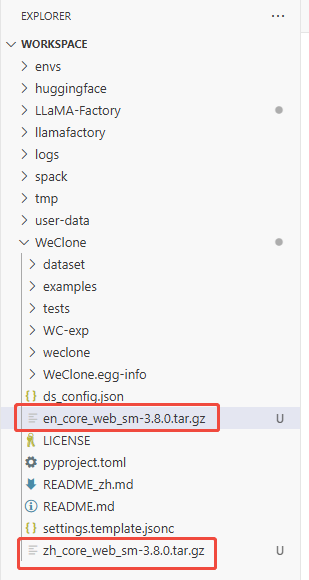
e. 执行如下命令,下载安装llamafactory。
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolationf. 替换llamafactory源码文件,单击下载loader.py文件,并放至
/workspace/envs/weclone/lib/python3.10/site-packages/llamafactory/data目录下进行替换。g. 执行如下命令,安装rich包。
pip install rich -i https://pypi.tuna.tsinghua.edu.cn/simple/h. (可选)执行如下命令,安装DeepSpeed包。
注意仅多卡训练时需要安装该包。
pip install deepspeed -i https://pypi.tuna.tsinghua.edu.cn/simple/i. 执行如下命令,拷贝配置文件,并重命名。
注意初始时Weclone项目内,并不包含配置文件settings.jsonc,需要您将配置模板settings.template.jsonc(如图②)复制一份,并重命名为settings.jsonc(如图③),原settings.template.jsonc可留作参考文件。配置文件默认读取路径:WeClone/settings.jsonc。
cp /workspace/WeClone/settings.template.jsonc /workspace/WeClone/settings.jsonc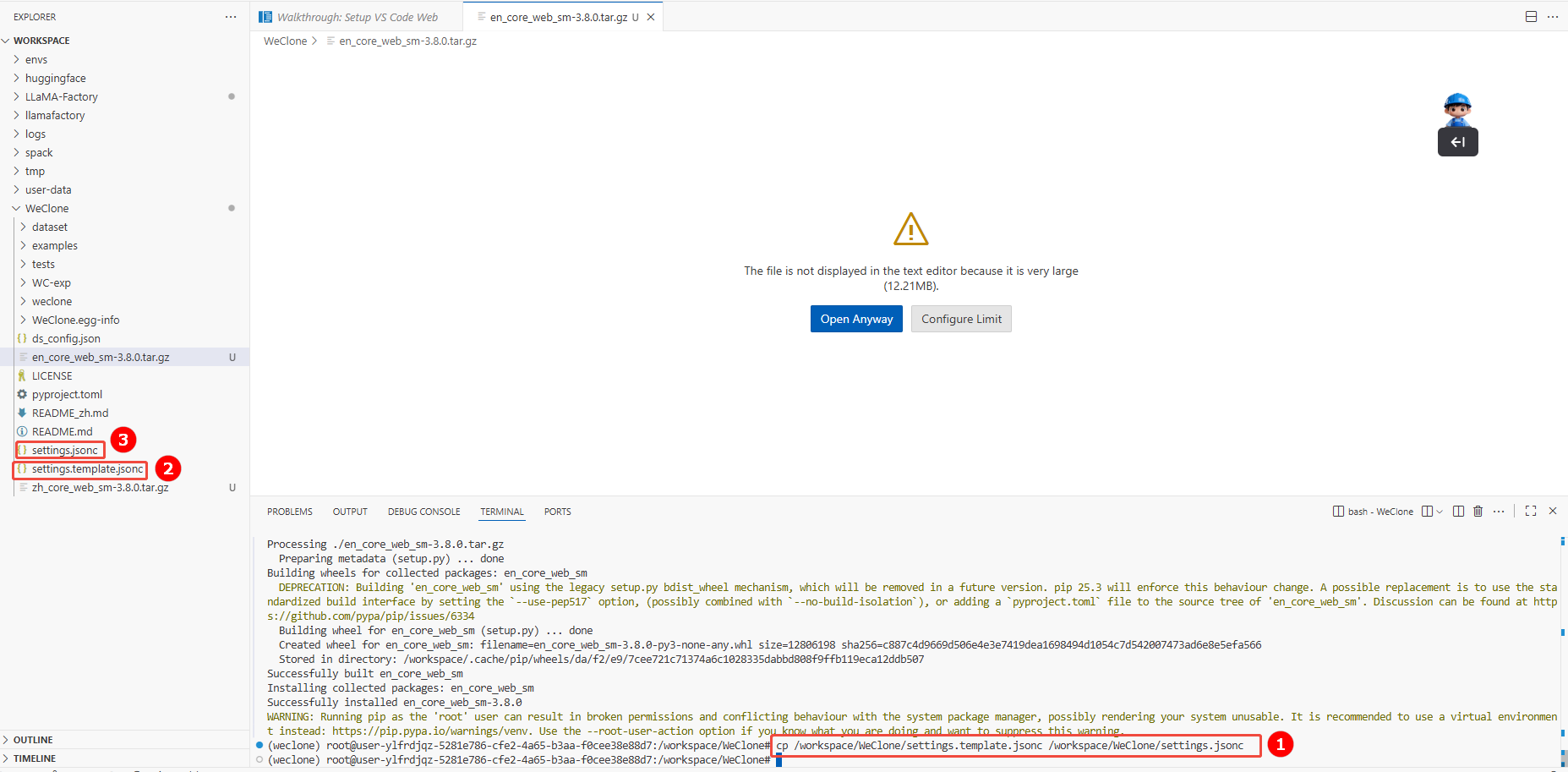
步骤二:数据处理
本实践使用的数据集为用户的个人聊天记录,可以是纯文本对话,也可以是多模态对话(文本+图片)。
为了方便用户快速体验效果,本实践提供了一个简单的英文航空订票客服场景对话数据集,其中assistant角色是航空公司订票客服,会对user的问询提供专业的订票服务。此数据集来自HuggingFace开源数据集:google/air_dialogue,已对其中的信息进行处理,您可以按照如下步骤直接下载数据集并进行微调操作。
-
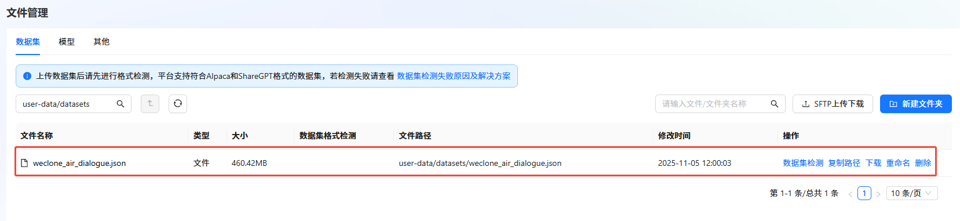
单击下载weclone_air_dialogue数据集,数据集下载完成后,需上传至LlamaFactory Online平台的“文件管理”中。具体操作,可参考SFTP上传下载完成数据集上传。
-
数据集检测。
a. 进入LlamaFactory Online平台,单击“控制台”,单击左侧导航栏的“文件管理”。
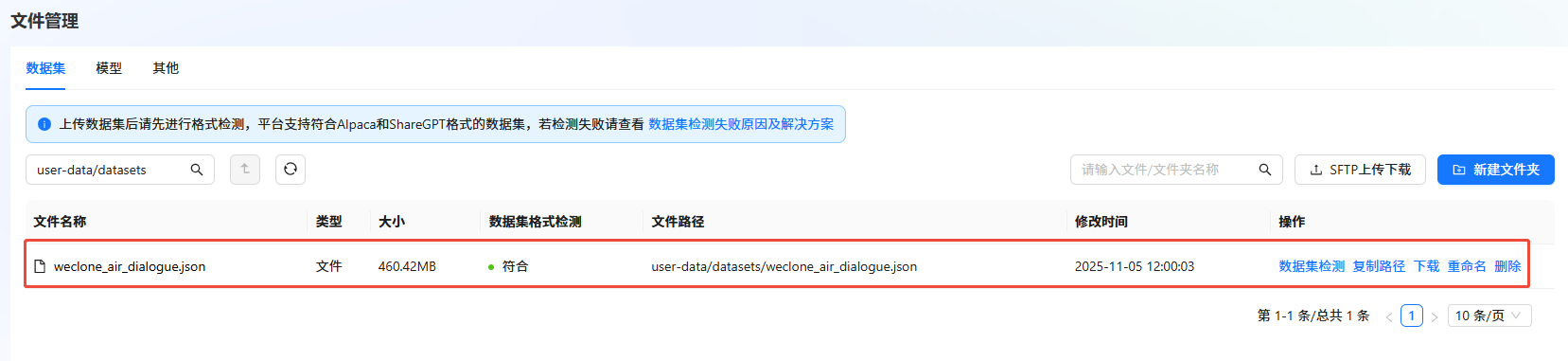
b. 单击目标数据集右侧“操作”列的"数据集检测",检测数据集。如下图所示,若“数据集格式检测”结果显示“符合”,则表示数据集符合格式要求。
-
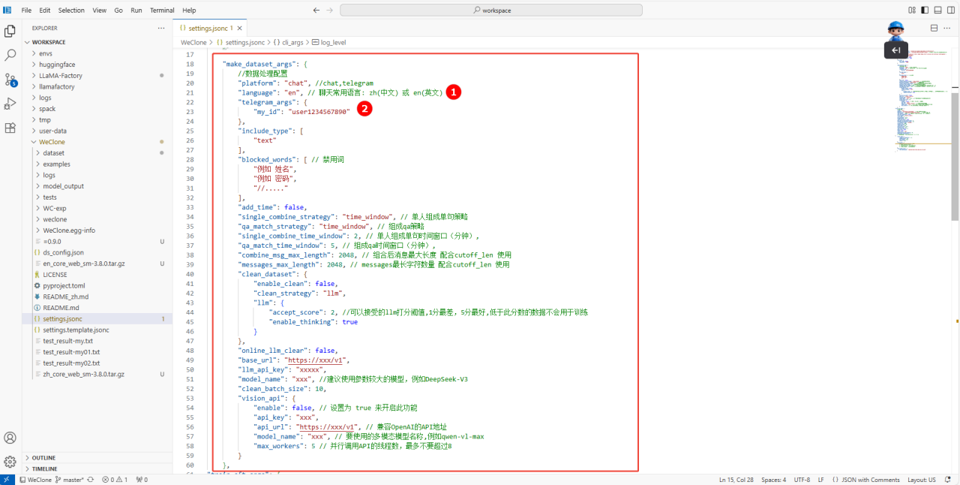
返回终端, 配置make_dataset_args参数。由于当前选取的数据集为英文,因此需要在配置文件settings.jsonc中的make_dataset_args字段内配置language字段为
en,如下图所示。提示如果使用Telegram对话数据,需要将自己的from_id写入配置文件telegram_args字段中的my_id字段(如图②),请根据自己的数据情况和训练需求,编辑配置文件。
make_dataset_args参数详情
"make_dataset_args": {
//数据处理配置
"platform": "telegram", //chat,telegram
"language": "en", // 聊天常用语言: zh(中文) 或 en(英文)
"telegram_args": {
"my_id": "user8149809561"
},
"include_type": [
"text"
],
"blocked_words": [ // 禁用词
"name",
"password",
"//....."
],
"add_time": false,
"single_combine_strategy": "time_window", // 单人组成单句策略
"qa_match_strategy": "time_window", // 组成qa策略
"single_combine_time_window": 2, // 单人组成单句时间窗口(分钟),
"qa_match_time_window": 5, // 组成qa时间窗口(分钟),
"combine_msg_max_length": 2048, // 组合后消息最大长度 配合cutoff_len 使用
"messages_max_length": 2048, // messages最长字符数量 配合cutoff_len 使用
"clean_dataset": {
"enable_clean": false, //是否过滤数据集
"clean_strategy": "llm",
"llm": {
"accept_score": 2, //可以接受的llm打分阈值,1分最差,5分最好,低于此分数的数据不会用于训练
"enable_thinking": true
}
},
"online_llm_clear": false,
"base_url": "https://xxx/v1",
"llm_api_key": "xxxxx",
"model_name": "xxx", //建议使用参数较大的模型,例如DeepSeek-V3
"clean_batch_size": 10,
"vision_api": {
"enable": false, // 设置为 true 来开启此功能
"api_key": "xxx",
"api_url": "https://xxx/v1", // 兼容OpenAI的API地址
"model_name": "xxx", // 要使用的多模态模型名称,例如qwen-vl-max
"max_workers": 5 // 并行调用API的线程数,最多不要超过8
}
}
步骤三:模型训练
-
模型训练参数配置,在终端打开上文中已复制的配置文件settings.jsonc,配置如下参数:
common_args参数解释和配置如下(如图①):配置参数 配置说明 配置示例 model_name_or_path 训练用的基模型路径。 /shared-only/models/Qwen/Qwen2.5-14B-Instruct adapter_name_or_path adapter路径(也是SFT的输出路径和后续推理时加载的checkpoint路径)。如不想加载lora adapter,可以将此参数注释掉。 /workspace/WeClone/model_output template 基模型的对话模板名称,如Qwen系列模型是qwen或者qwen2_vl(多模态)。 qwen default_system 数据处理时添加的system prompt,可以根据实际情况使用英文/中文。 Please act like a human being, don't say you are artificial intelligence. train_sft_args参数解释和配置如下(如图②):配置参数 配置说明 配置示例 dataset 微调使用的数据集名称。 weclone_air_dialogue dataset_dir 存放有dataset_info.json文件的路径。 /workspace/llamafactory/data save_steps 如按steps保存,此参数设置每多少步保存一次。 100 num_train_epochs 总训练轮数。 2 flash_attn 如需启用,设置为"fa2"。 fa2 deepspeed 多卡训练时,需要指定deepspeed配置文件路径。 - 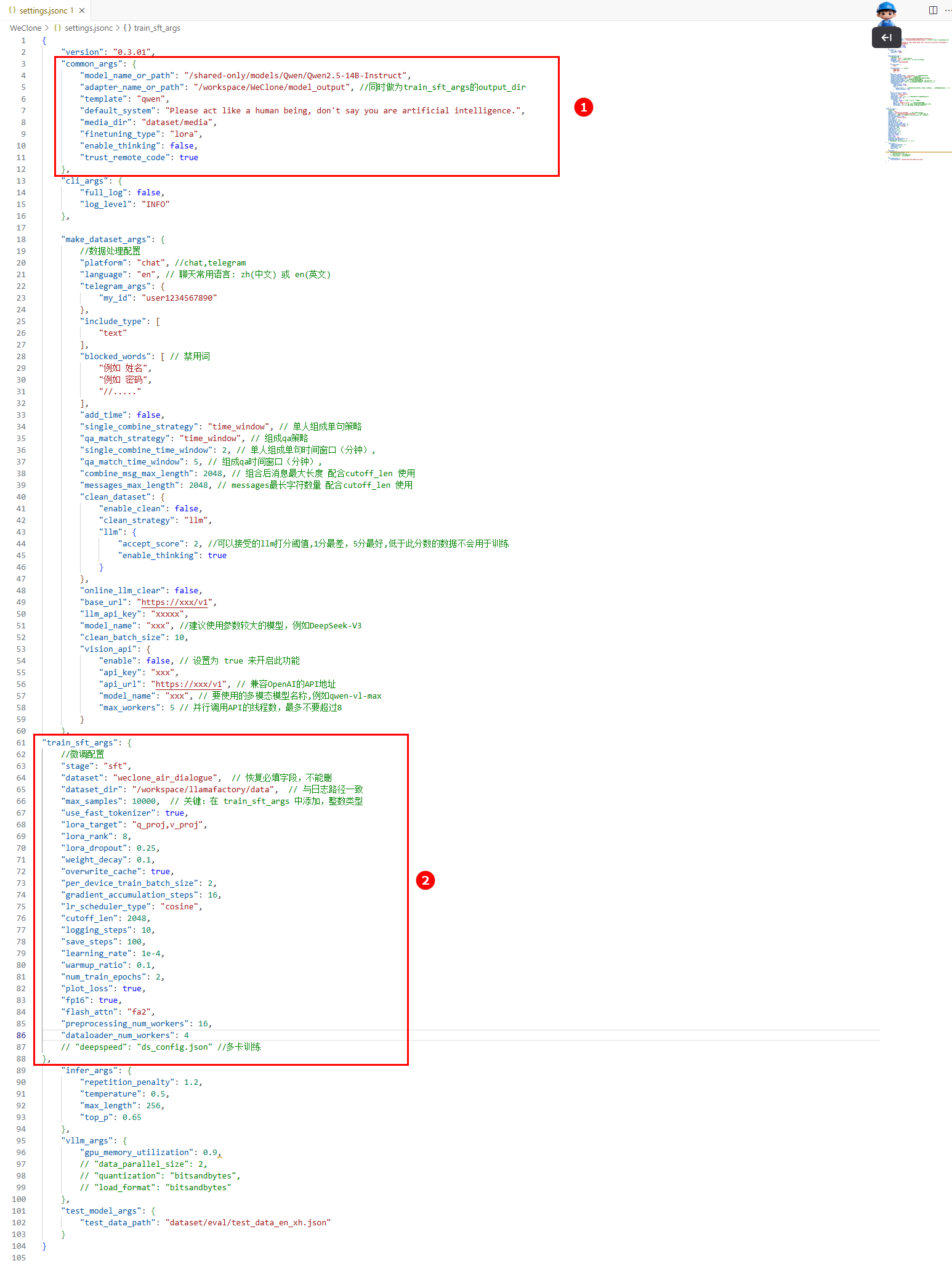
-
参数配置完成后,执行如下命令,进行模型训练,训练结果如下图所示。
conda activate weclone
cd /workspace/WeClone
weclone-cli train-sft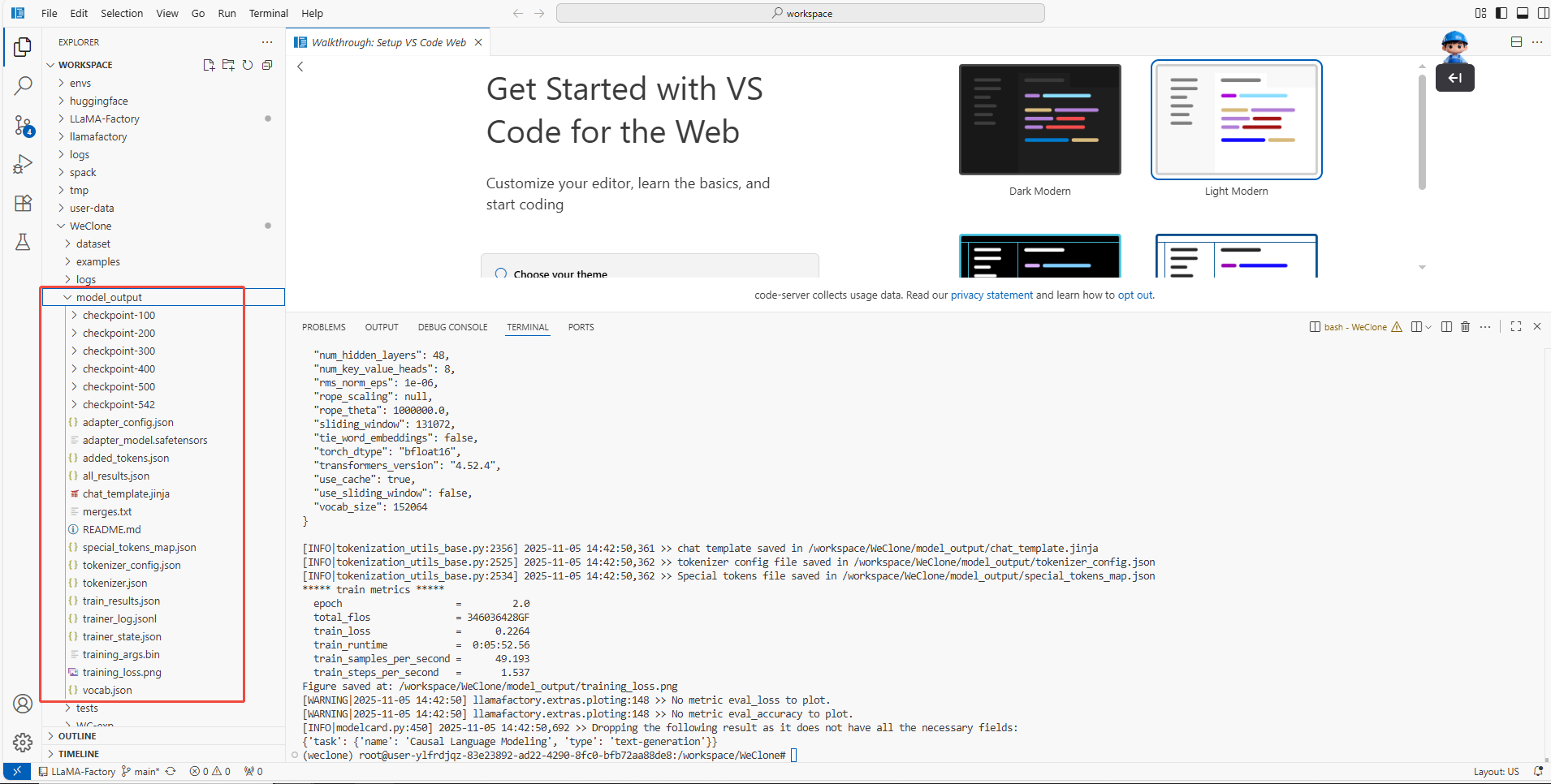
步骤四:模型对话
启动WeClone的API服务
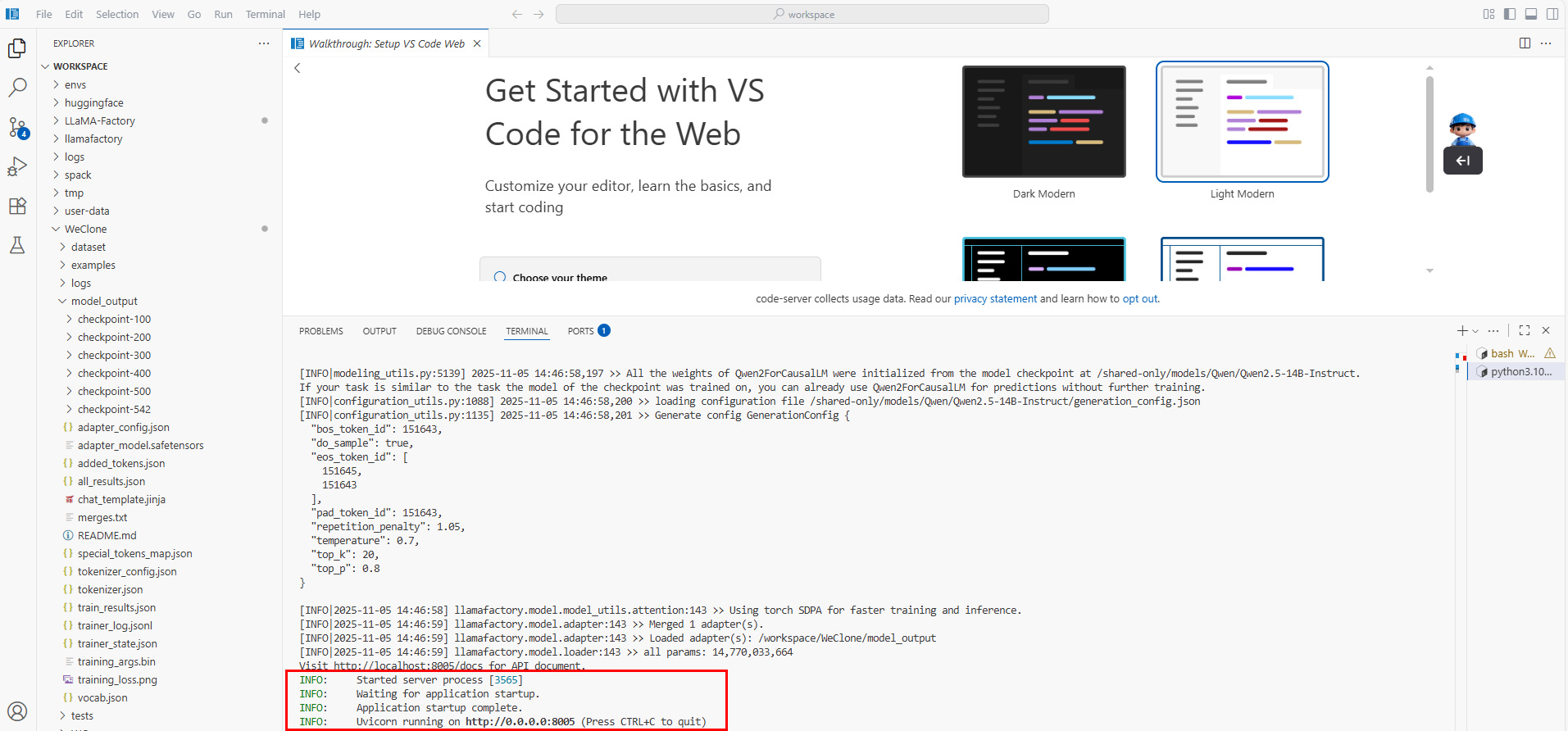
在终端执行如下命令,启动WeClone的推理服务(API服务)。如下图所示,已成功启动API服务。
conda activate weclone
cd /workspace/WeClone
weclone-cli server
模型对话
API服务启动成功后,配置如下问题进行微调前和微调后的模型对话。
-
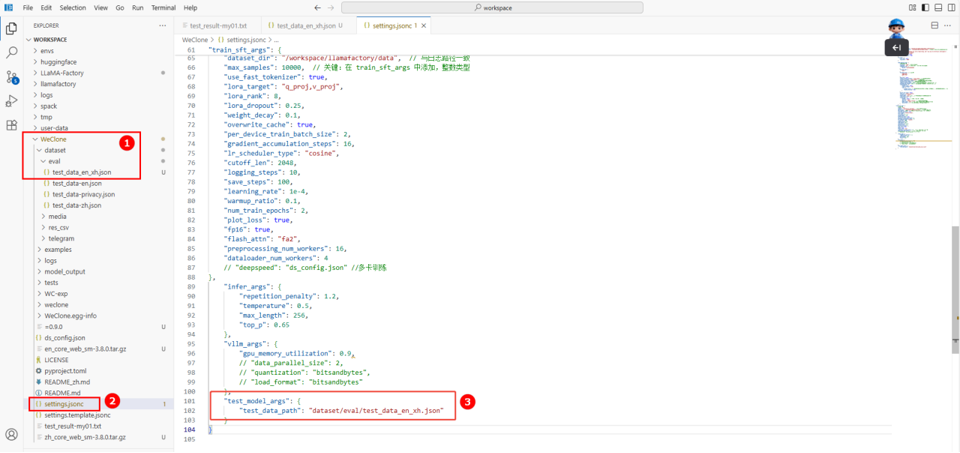
在/workspace/WeClone/dataset/eval目录下新建对话文件(如下图①),对话内容如下所示。
User:"Hello.",
User:"My name is Emily Edwards.",
User:"I need some help in my flight ticket reservation to attend a convocation meeting, can you please help me?",
User:"Thank you and my dates are 06/12 and back on 06/14.",
User:"The airport codes are from DFW to IAD.",
User:"Sure.",
User:"Yes, do proceed with booking.",
User:"Thank you for your assistance in my flight ticket reservation.",
User:"You are welcome." -
在配置文件settings.jsonc中(如图②)的test_model_args字段下修改json路径为上述新建的对话文件路径(如图③)。
 提示
提示生成模型回答时,会读取配置文件中infer_args字段下的生成参数,可以自定义。如使用vllm框架进行加速,其配置信息会从vllm_args下读取。
- 微调后模型对话
- 原生模型对话
-
API服务启动成功后,新建一个终端,执行如下命令,进行微调后的模型对话。
conda activate weclone
cd /workspace/WeClone
weclone-cli test-model -
将输出文件test_result-my.txt重命名为test_result-my02.txt,以防止之前的对话结果被覆盖。
模型的生成结果保存至:/workspace/WeClone/test_result-my02.txt目录下,如下图所示。
注意- 如需进行多次对话测试,请将先前的输出文件test_result-my.txt重命名,防止被覆盖。
- 模型服务从配置文件settings.jsonc的common_args字段内的adapter_name_or_path字段获取加载的模型信息,如需修改加载的模型,请编辑配置文件。微调训练完,直接运行,即会加载训练的最新checkpoint。因此这里无需修改配置文件。
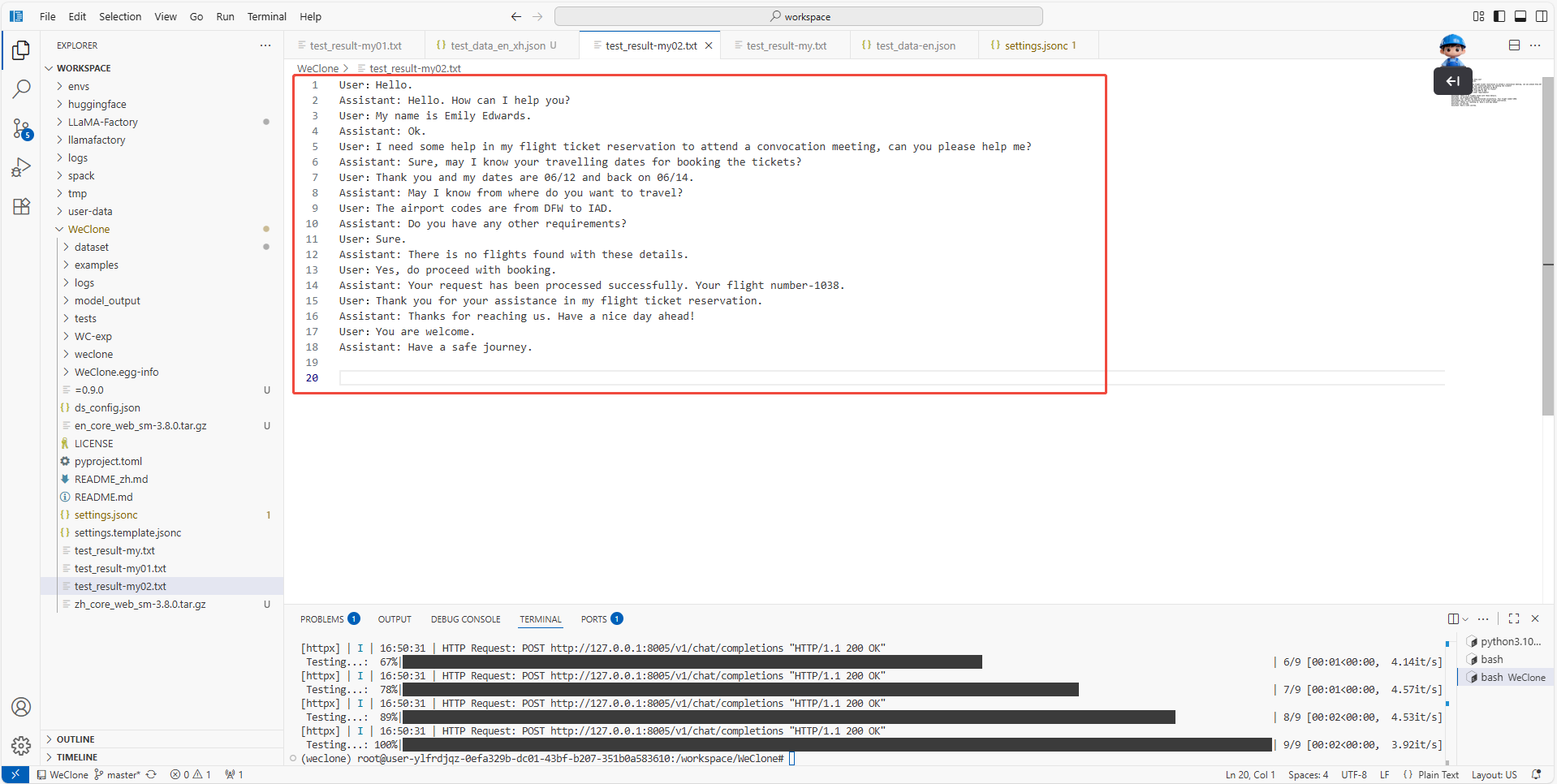
微调后的Assistant回答更加专业,了解user需求后,简短地回问索取用户信息,并回复订票的结果。整个流程更加贴合常见的订票人工客服操作标准,可明显观察到Assistant学习到了订票客服的画风和话术。
-
对基模型进行测试时,需要在配置文件settings.jsonc中用
//注释掉adapter_name_or_path字段,如下图所示。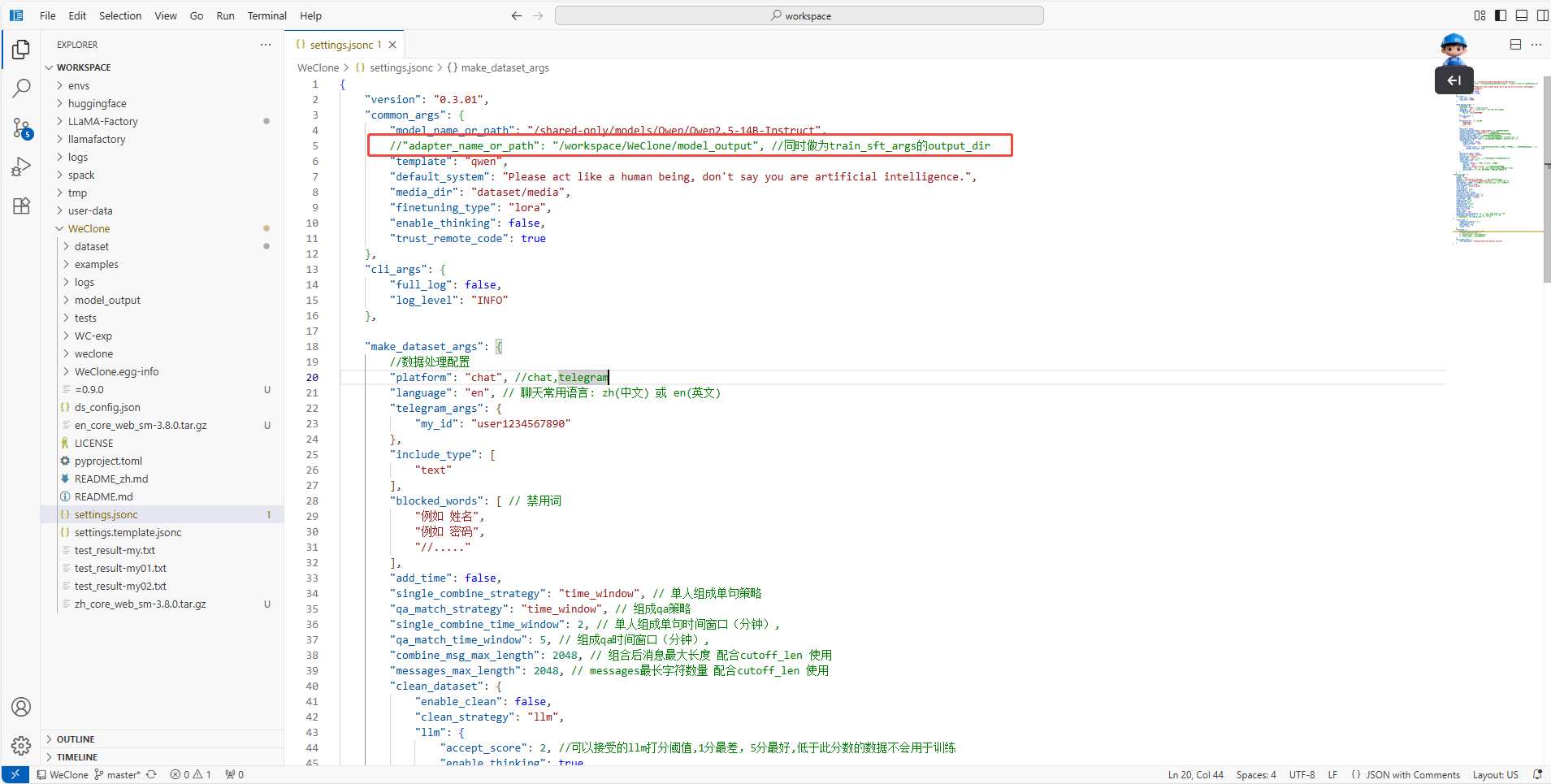
-
执行如下命令,进行原生模型对话。
conda activate weclone
cd /workspace/WeClone
weclone-cli test-model模型的生成结果保存至:/workspace/WeClone/test_result-my.txt目录下,如下图所示。
注意如需进行多次对话测试,请将输出文件test_result-my.txt重命名,防止被覆盖。
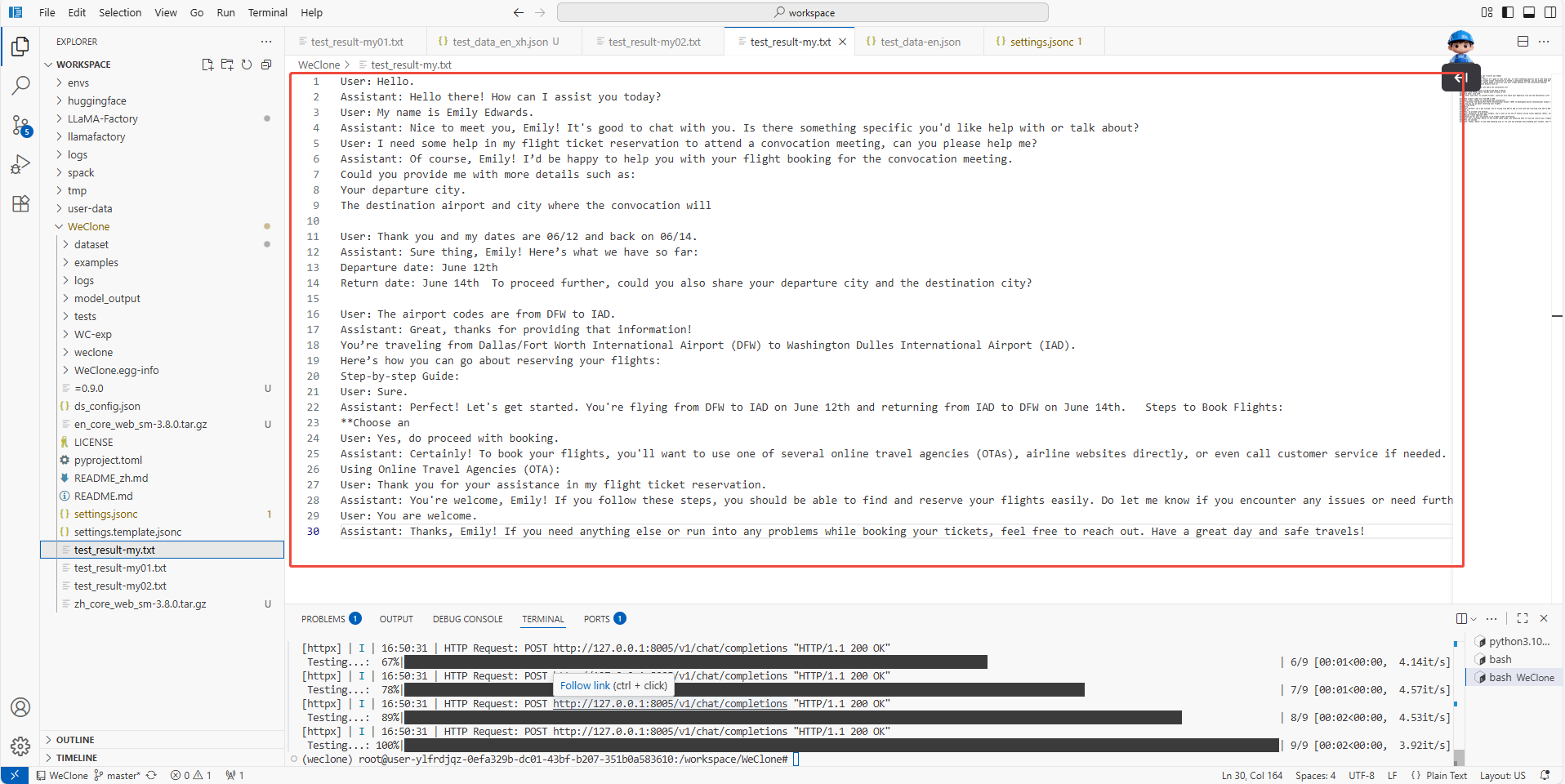
可见Assistant的回答并不专业,仅具备一些通用知识,无法简明扼要地向user索要订票所需的关键信息,并且经常回答过于冗长,而被提前截断,未达到一位专业的航空公司订票客服的业务标准。
观察微调后的模型与原生模型的对话结果,发现:微调前的Assistant订票回复冗长、侧重通用指引且信息索取被动,仅提供操作建议不直接处理订票业务;微调后的Assistant话术简洁、符合人工客服标准,能主动针对性索取关键信息并直接反馈订票结果,业务聚焦度与客服角色贴合度显著提升。
总结
WeClone依托LlamaFactory Online平台,以Qwen2.5-14B-Instruct为基模型,借助LoRA轻量化微调技术,精准复刻了航空公司订票客服的专业语言风格与业务处理逻辑,有效验证了其基于特定场景对话数据、快速构建高贴合度专属数字分身的核心能力,为个性化客服类数字分身的落地提供了高效实践路径。