基于CareGPT医疗目标的Qwen3-8B模型微调之旅
在人工智能技术深度渗透各行业的当下,医疗健康领域对智能化解决方案的需求日益迫切。医疗大语言模型(Medical LLM)作为连接人工智能与医疗服务的关键载体,能够通过自然语言交互为用户提供疾病咨询、导诊建议、医学知识解答等服务,在缓解医疗资源紧张、提升医疗服务可及性方面具有重要价值。
CareGPT是一款针对医疗健康领域优化的开源大语言模型项目,核心通过领域适应训练提升模型在医疗场景的专业性与可靠性,助力医疗人工智能技术普及应用;而LLaMA Factory作为成熟的大语言模型微调框架,凭借便捷的WebUI操作界面简化模型训练、推理与部署流程,为CareGPT的微调提供了理想工具支持。
本文档指导您如何在LlamaFactory Online平台实现基于CareGPT医疗目标的Qwen3-8B模型微调实践。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Qwen3-8B | 是 | Qwen3-8B是一款轻量化的开源大语言模型,具备较强的通用语言理解与生成能力,支持多场景适配,且在医疗等垂直领域可通过领域适应训练进一步优化专业性,适配中小规模算力需求,兼顾性能与部署灵活性。 |
| 数据集 | ChatMed_Consult_Dataset和HuatuoGPT2-SFT-GPT4-140K | 否(提供下载链接) | ChatMed_Consult_Datase由Wei Zhu主导构建,是中文医疗问诊数据集,补全中文医疗LLM训练数据,供模型微调;HuatuoGPT2-SFT-GPT4-140K由FreedomIntelligence团队打造,是大规模中文医疗指令微调数据集,借GPT-4生成优质响应,提升医疗LLM指令能力,支撑监督微调。 |
| GPU | H800*4(推荐) | - | 模型规模较大,建议配置足够显存。 |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
使用推荐资源(H800*4)进行微调时微调过程总时长约2h16min。
操作步骤
步骤一:数据准备
- 下载数据集。数据集下载完成后,需上传至文件管理。具体操作,可参考SFTP上传下载完成数据集上传。
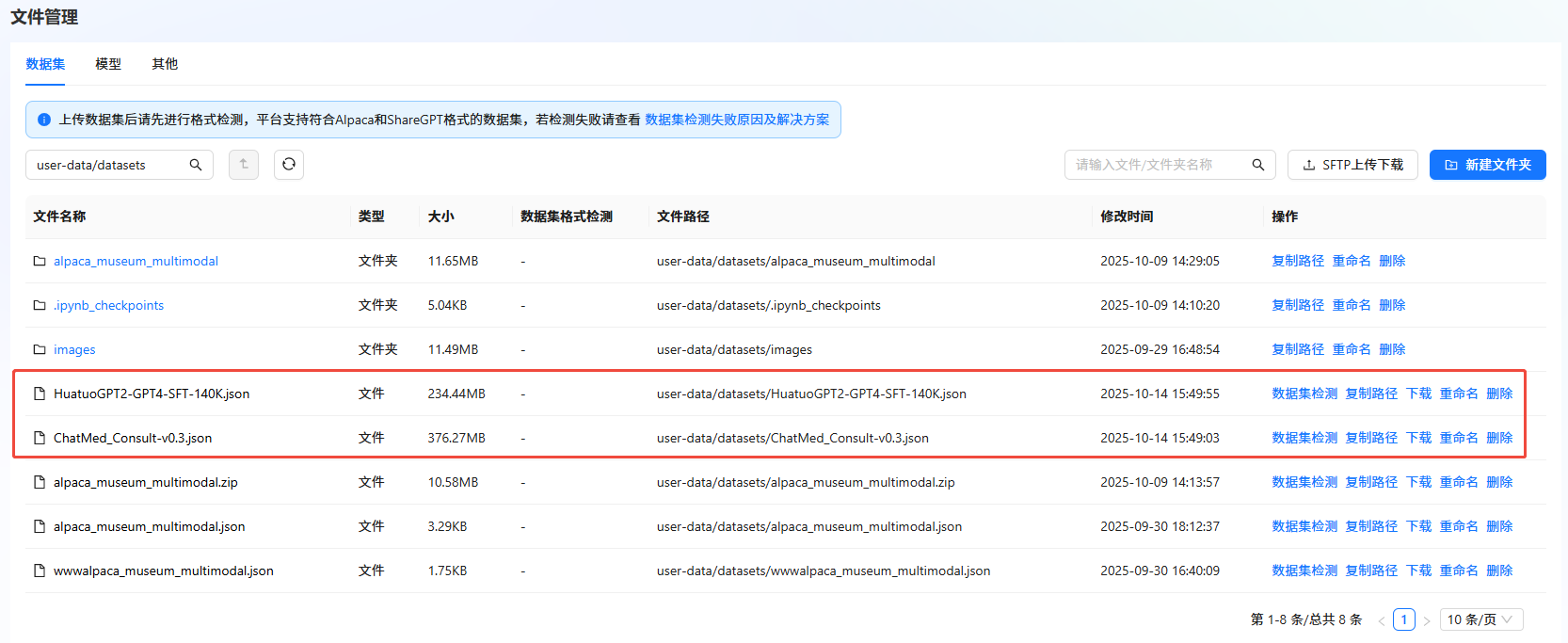
-
数据格式转换。
LlamaFactory作为主流的大语言模型微调框架,对医疗问诊类数据有明确的格式要求(需包含instruction、input、output核心字段,支持多轮对话的history字段可选)。针对ChatMed_Consult_Dataset数据集原有的 “query-response” 二元结构,需通过字段映射与格式重构,将其转换为LLaMA Factory兼容的数据格式。数据格式转换的具体步骤如下:
a. 进入LlamaFactory Online平台,单击“控制台”,进入控制台后单击左侧导航栏的“实例空间”,然后在页面单击“开始微调”。
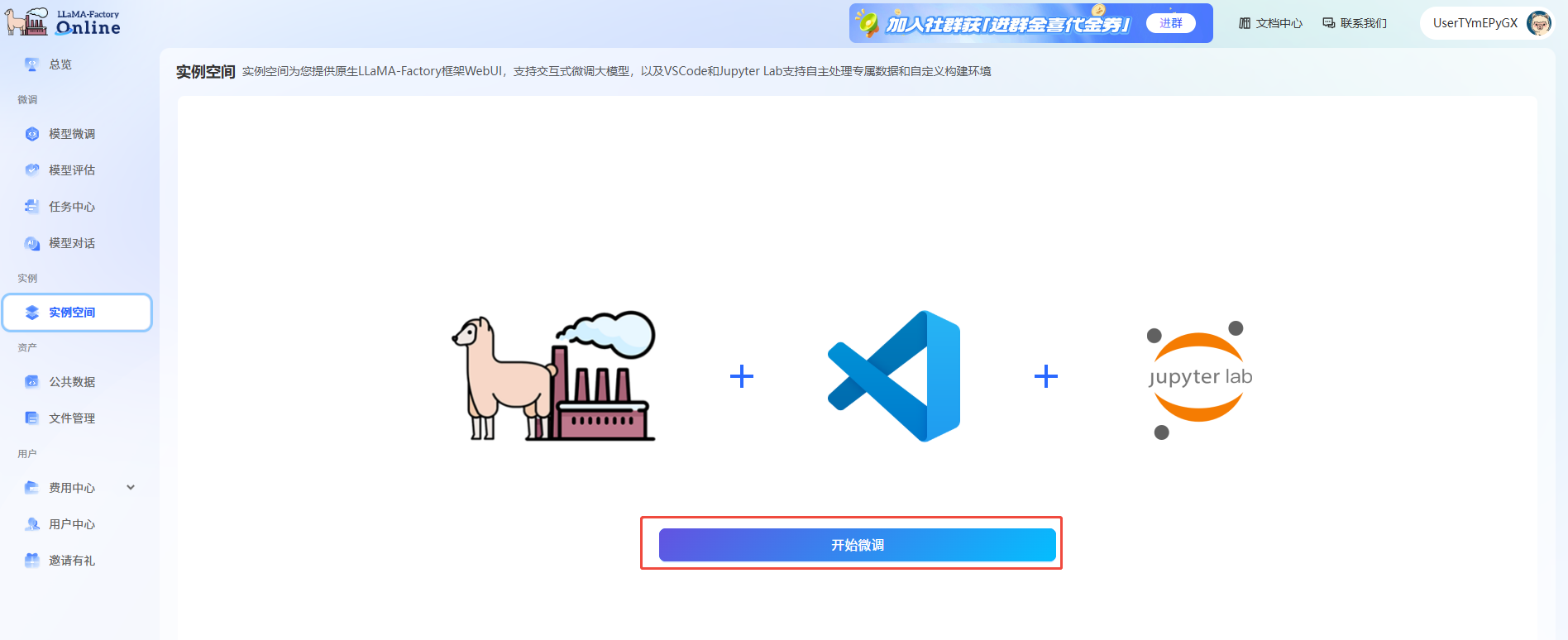
b. 在弹出的页面选择镜像(如图①),选择“CPU”,核数选择“2核”(如图②),然后单击“启动”。
 提示
提示系统会根据所需资源及其相关参数,动态预估数据处理费用,您可在页面底部查看预估结果。
c. 实例启动后,单击[VSCode处理专属数据]页签,进入VSCode编辑页面。您也可以根据需要打开JupyterLab处理数据,本示例指导您通过VSCode处理数据。
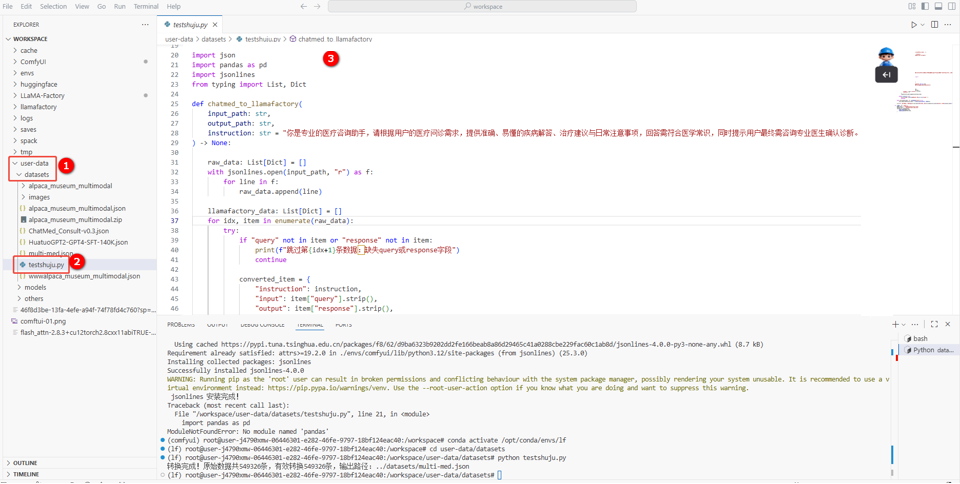
d. 在VSCode页面左侧user-data/datasets目录下(如图①)新建一个.py后缀的文件(如图②),然后复制以下命令至文件中(如图③)。
代码详情
import json
import pandas as pd
import jsonlines
from typing import List, Dict
def chatmed_to_llamafactory(
input_path: str,
output_path: str,
instruction: str = "你是专业的医疗咨询助手,请根据用户的医疗问诊需求,提供准确、易懂的疾病解答、治疗建议与日常注意事项,回答需符合医学常识,同时提示用户最终需咨询专业医生确认诊断。"
) -> None:
raw_data: List[Dict] = []
with jsonlines.open(input_path, "r") as f:
for line in f:
raw_data.append(line)
llamafactory_data: List[Dict] = []
for idx, item in enumerate(raw_data):
try:
if "query" not in item or "response" not in item:
print(f"跳过第{idx+1}条数据:缺失query或response字段")
continue
converted_item = {
"instruction": instruction,
"input": item["query"].strip(),
"output": item["response"].strip(),
"history": []
}
llamafactory_data.append(converted_item)
except Exception as e:
print(f"处理第{idx+1}条数据时出错:{str(e)},已跳过")
continue
with open(output_path, "w", encoding="utf-8") as f:
json.dump(llamafactory_data, f, ensure_ascii=False, indent=2)
print(f"转换完成!原始数据共{len(raw_data)}条,有效转换{len(llamafactory_data)}条,输出路径:{output_path}")
if __name__ == "__main__":
INPUT_FILE = "./ChatMed_Consult-v0.3.json"
OUTPUT_FILE = "./datasets/multi-med.json"
chatmed_to_llamafactory(
input_path=INPUT_FILE,
output_path=OUTPUT_FILE,
)
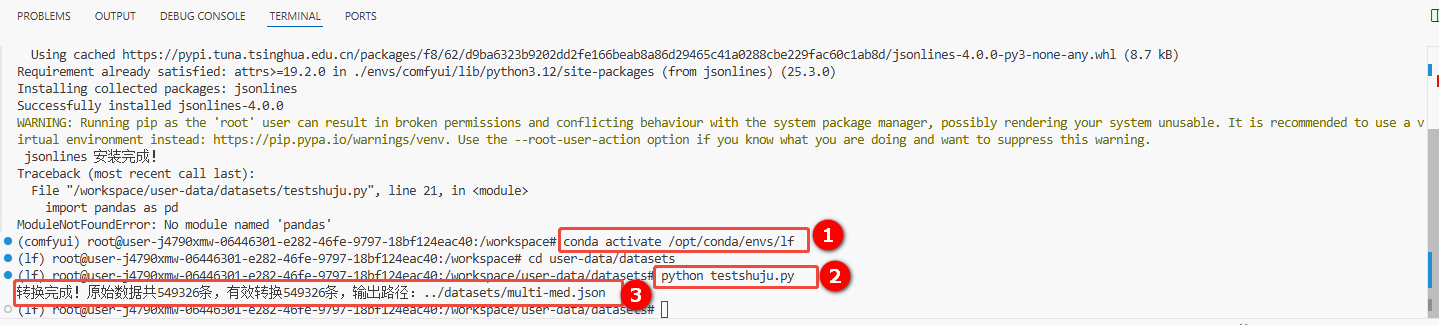
e. 在VSCode页面,新建一个终端,依次执行以下命令,进行数据格式转换(如图①和②)。
conda activate /opt/conda/envs/lf
python testshuju.py提示testshuju.py为本示例新建的文件,请根据您的实际情况进行替换。
回显信息如图③所示,说明数据格式转换成功,且转换后的数据存放在/datasets/multi-med.json中,即原数据集文件ChatMed_Consult_Dataset经格式转换后生成新的数据集文件multi-med。
-
数据集检测。
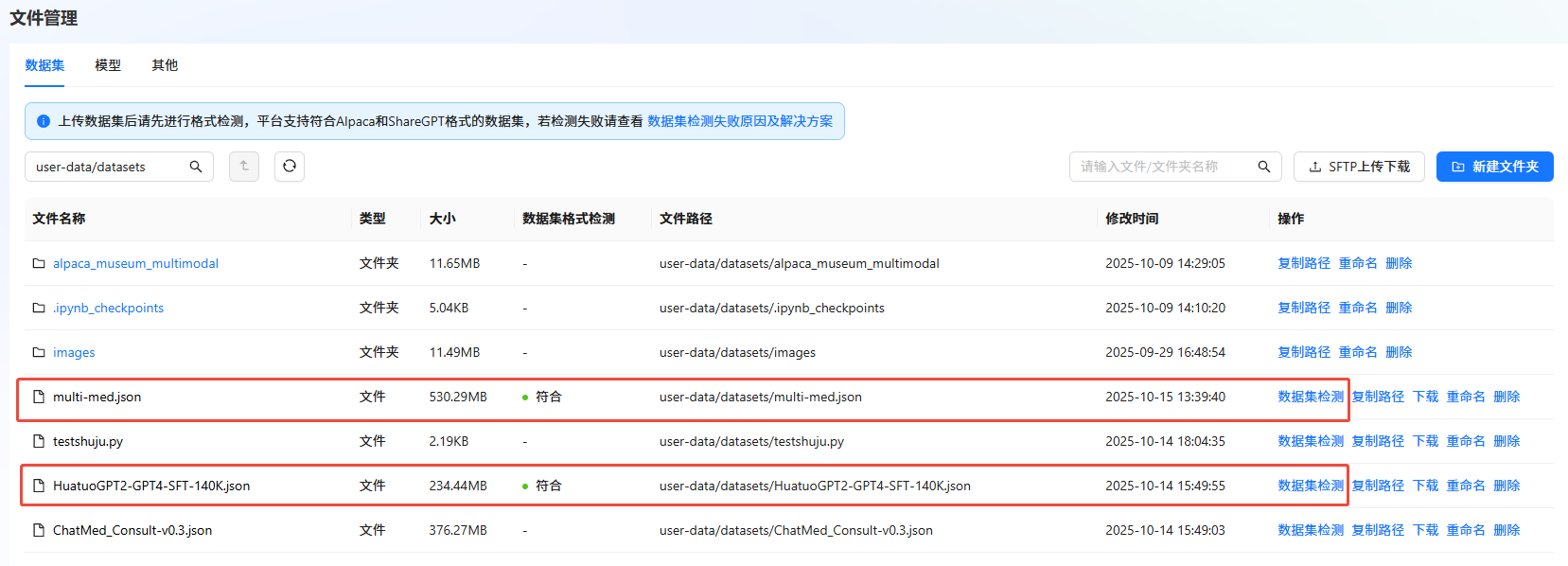
a. 返回LlamaFactory Online控制台,单击左侧导航栏的“文件管理”。
b. 单击目标数据集右侧“操作”列的"数据集检测",检测数据集。如下图所示,若“数据集格式检测”结果显示“符合”,则表示数据集符合格式要求。
步骤二:模型微调
-
进入LlamaFactory Online平台,单击“控制台”,进入控制台后单击左侧导航栏的“模型微调”进入页面。
-
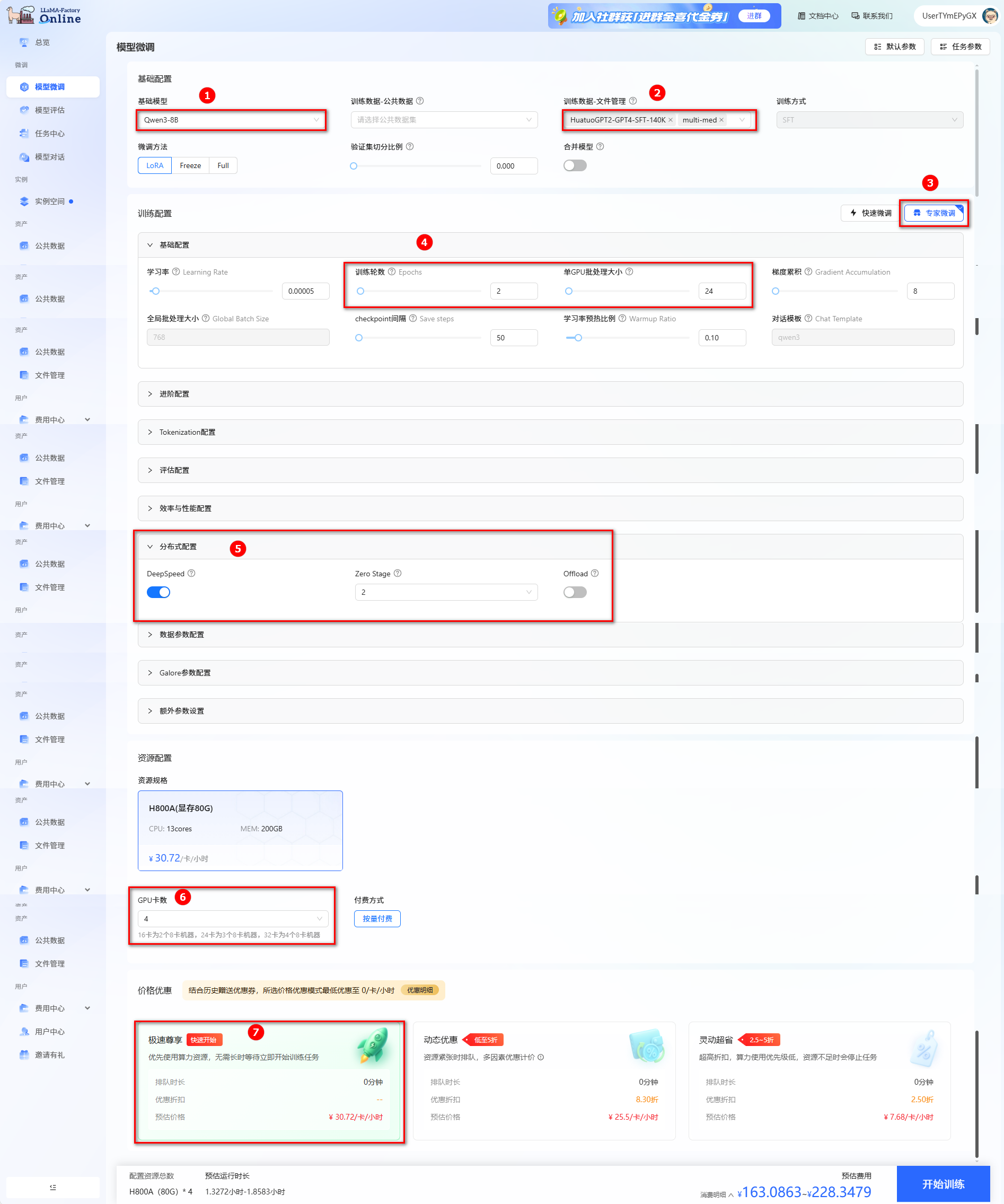
选择模型和数据集,进行参数配置。
- 本实践使用平台内置的Qwen3-8B作为基础模型(如图①),数据集为
ChatMed_Consult_Dataset(multi-med)和HuatuoGPT2-SFT-GPT4-140K(如图②)。 - 训练配置:选择“专家微调”(如图③);“训练轮数”配置为“2”,“单CPU批处理大小”配置为“24”(如图④)。
- 分布式配置:打开“DeepSpeed”开关(如图⑤)。
- 资源配置:推荐卡数为4卡(如图⑥)。
- 选择价格模式:本实践选择“极速尊享”(如图⑦),不同模式的计费说明参考计费说明。
- 开始训练:单击“开始训练”,开始模型训练。
 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
- 本实践使用平台内置的Qwen3-8B作为基础模型(如图①),数据集为
-
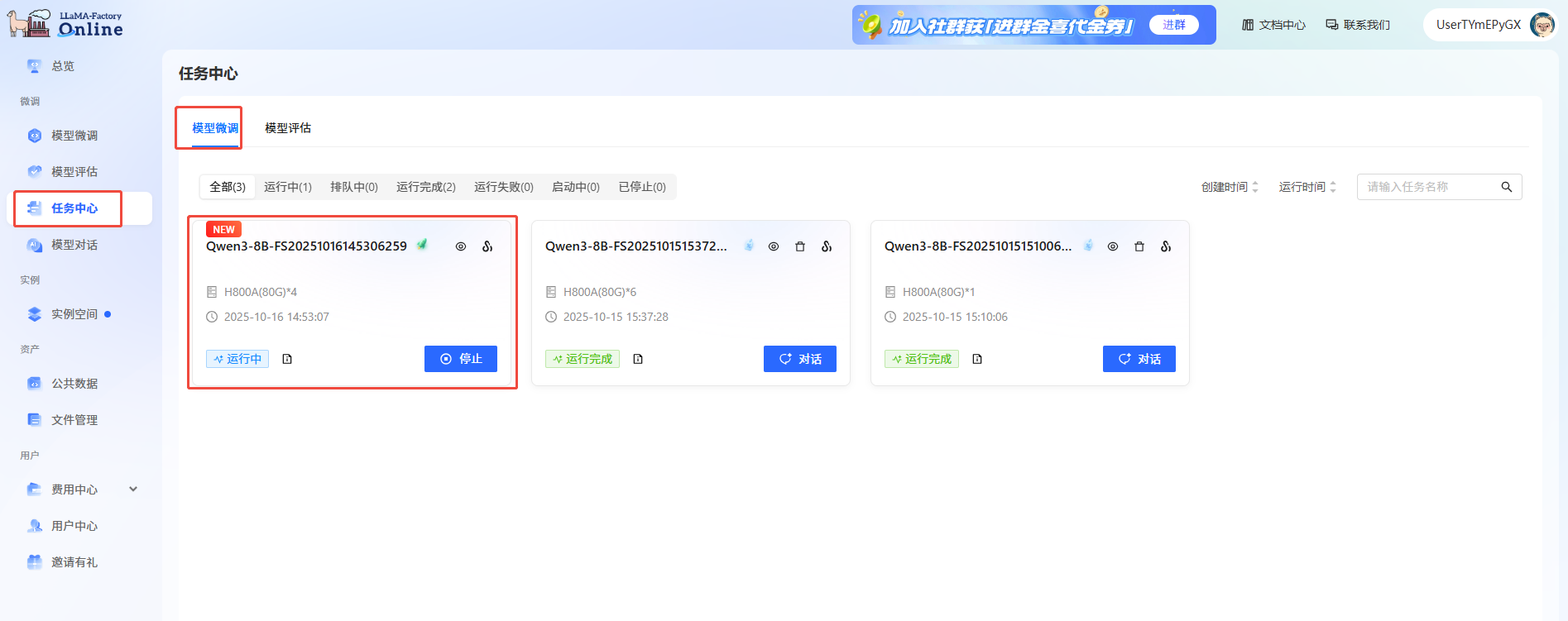
通过任务中心查看任务状态。 在左侧边栏选择“任务中心”,在“模型微调”页面即可看到刚刚提交的任务。
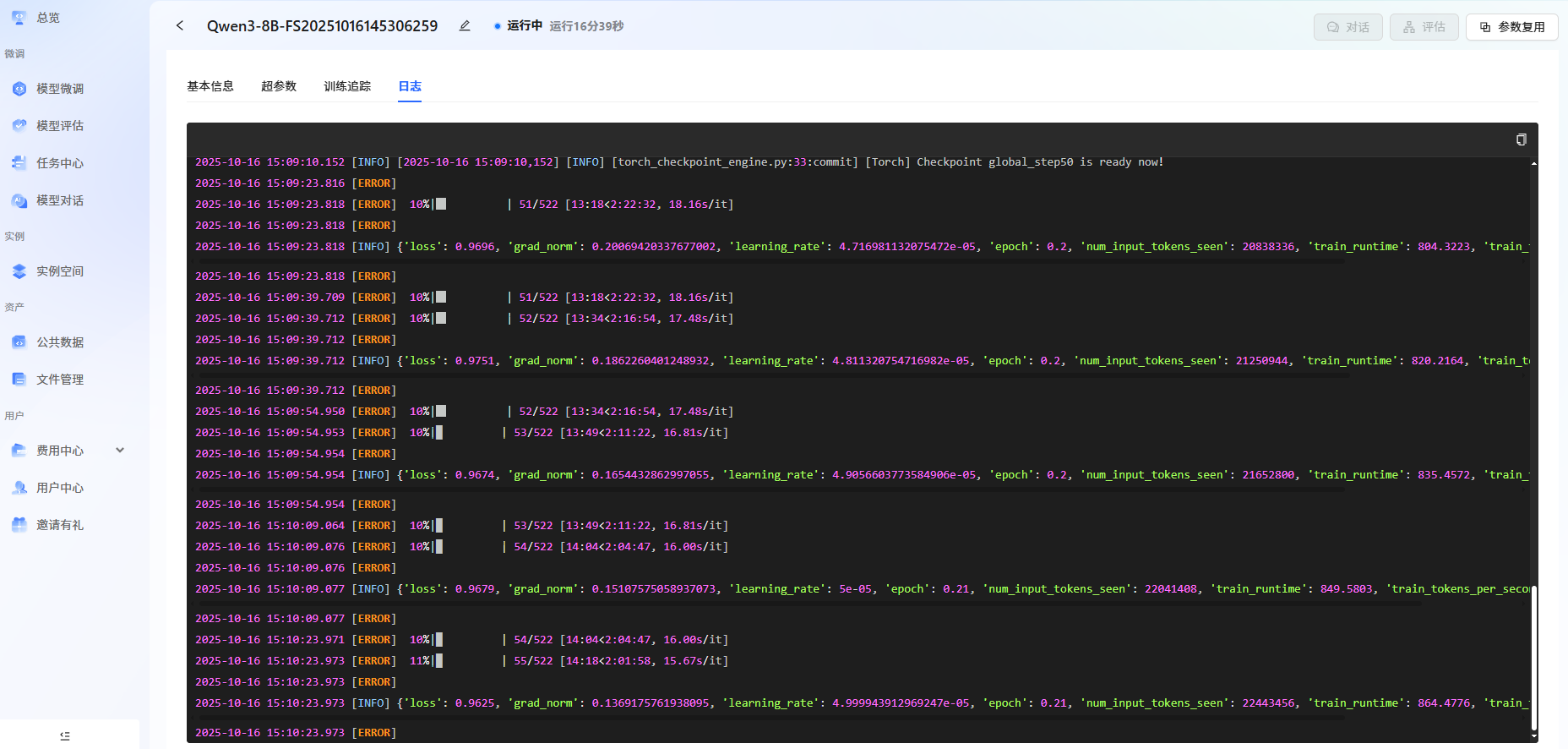
单击任务框,可查看任务的详细信息、超参数、训练追踪和日志。
-
任务完成后,模型自动保存在"文件管理->模型->output"文件夹中。可在"任务中心->基本信息->模型成果"处查看保存路径。
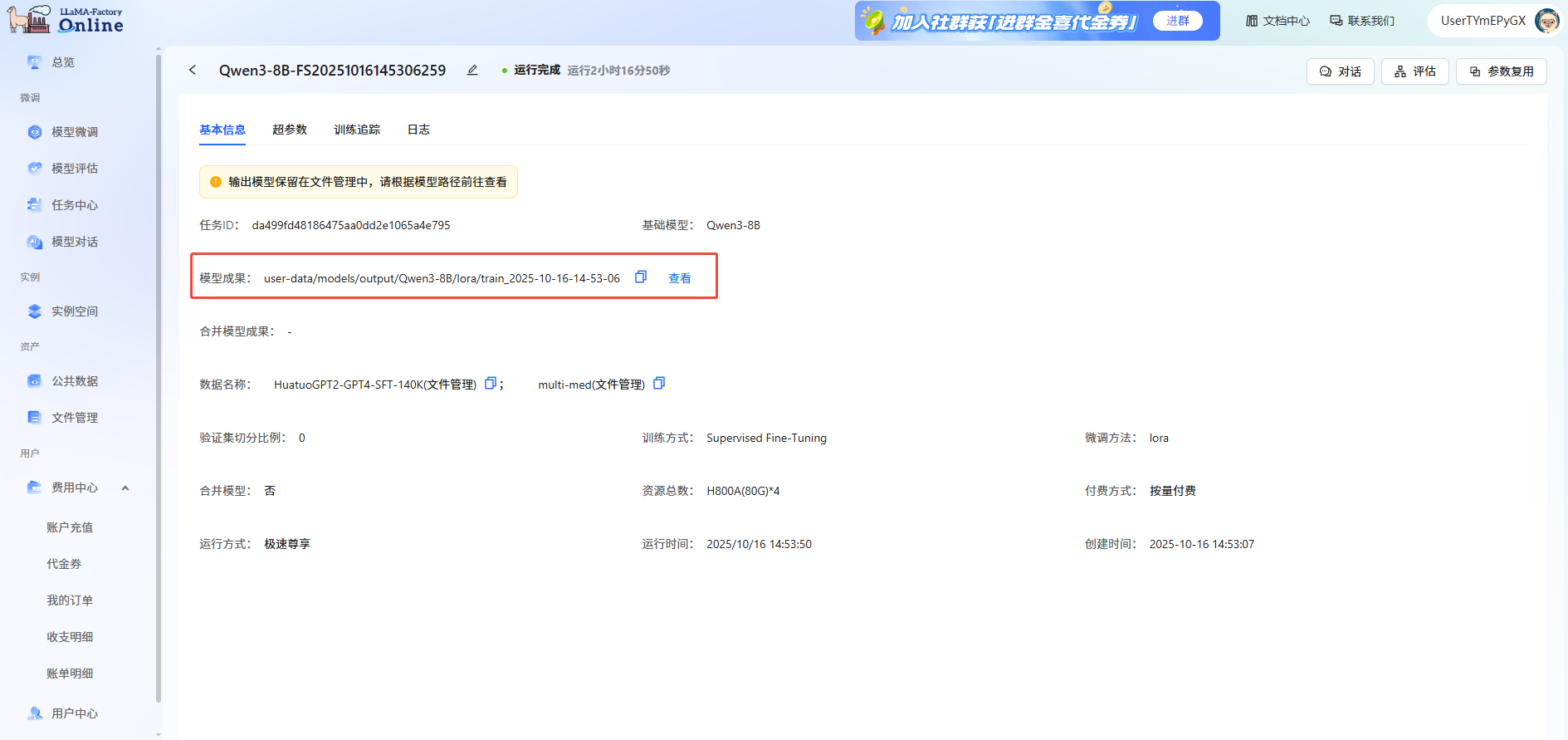
步骤三:模型评估
-
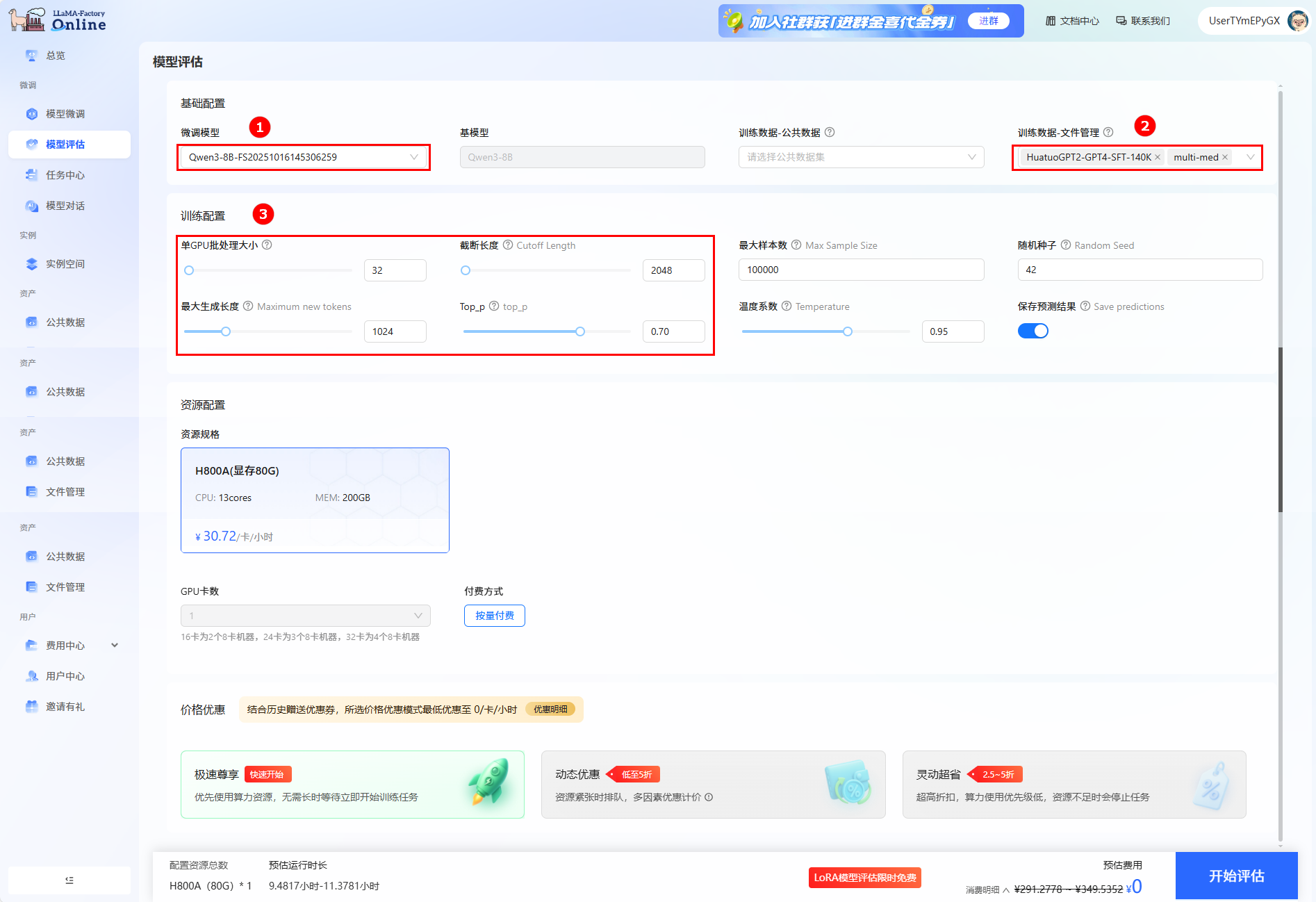
单击页面左侧导航栏的“模型评估”,进行评估训练配置。
-
微调模型选择上一步骤微调后的模型(如图①),评估数据集为
ChatMed_Consult_Dataset(multi-med)和HuatuoGPT2-SFT-GPT4-140K(如图②)。然后配置如下参数(如图③):- 单GPU批处理大小:设置为32。
- 截断长度:设置为2048。
- 最大生成长度:设置为1024。
其他参数设置为默认即可。
 提示
提示配置模型与数据集后,系统将根据所需资源及其相关参数,动态预估任务运行时长及微调费用,您可在页面底部查看预估结果。
-
可以在“任务中心->模型评估”下看到评估任务的运行状态。
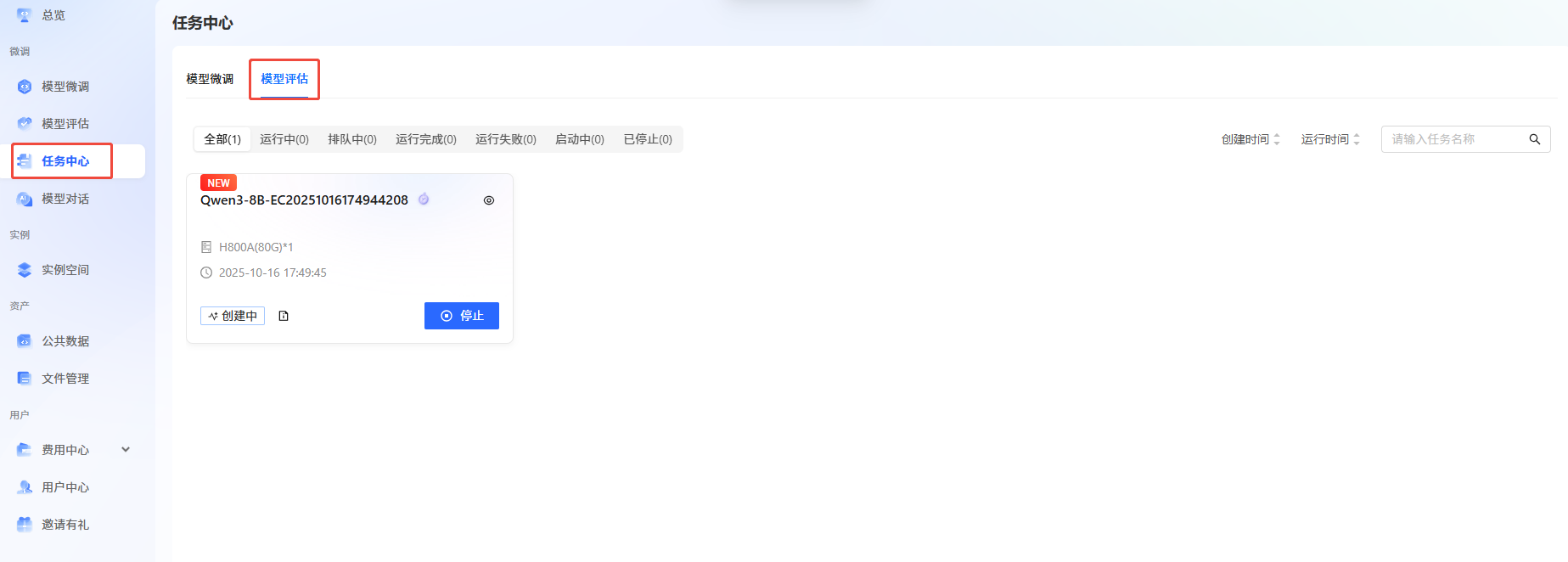
-
单击
 图标,进入任务基本信息查看页面。用户可查看评估任务的基本信息、日志以及评估结果。
图标,进入任务基本信息查看页面。用户可查看评估任务的基本信息、日志以及评估结果。
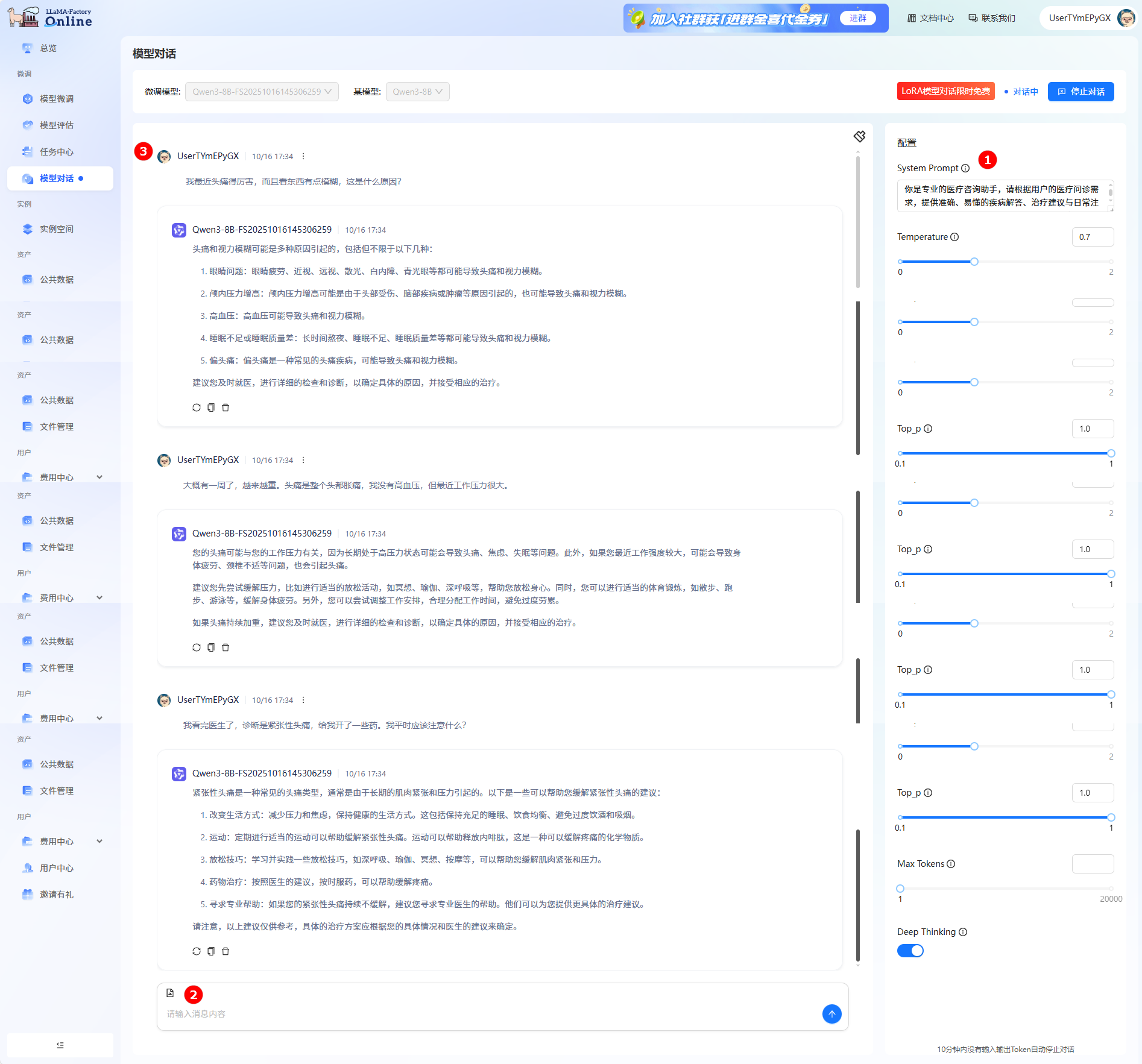
步骤四:模型对话
-
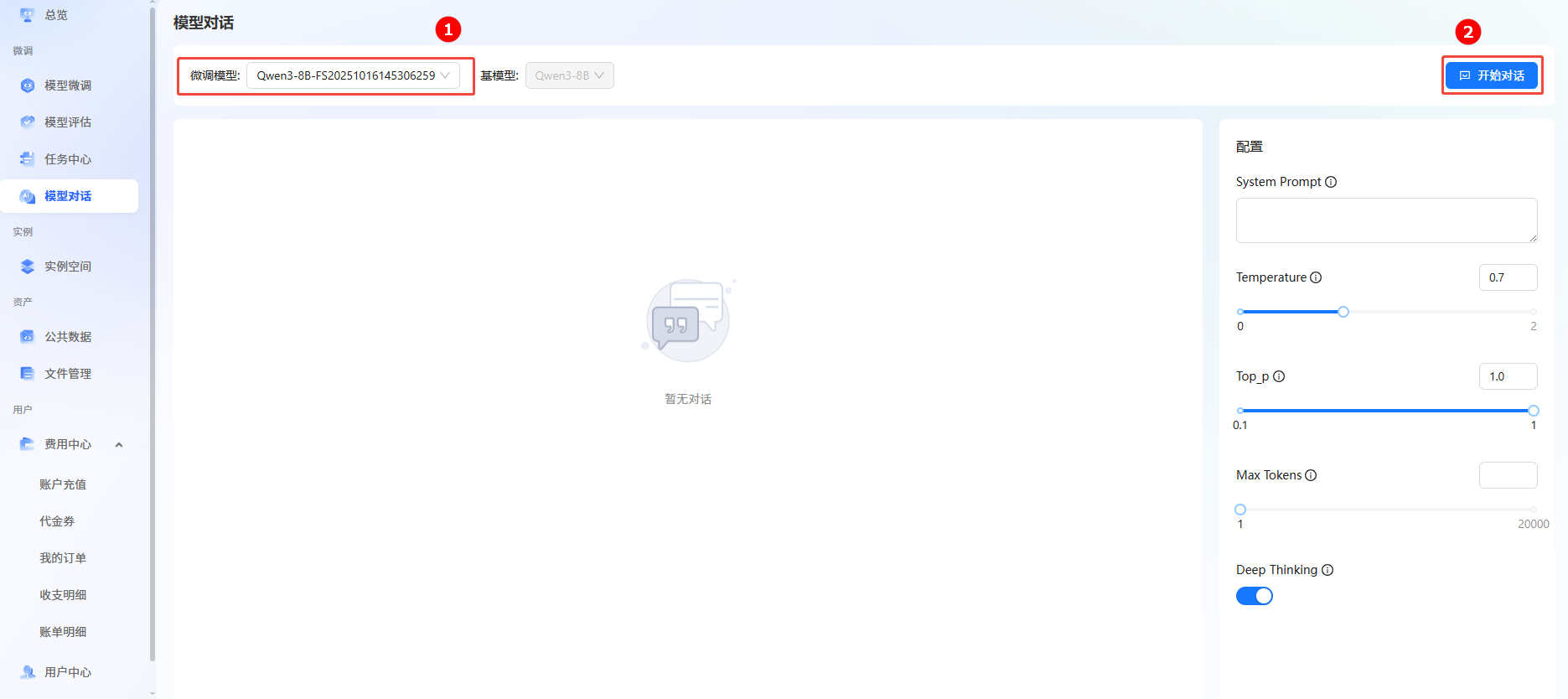
单击页面左侧导航栏“模型对话”,进入模型对话页面。
-
在微调模型处选择目标模型名称(如图①),单击右上角“开始对话”(如图②),在弹出的对话框单击“立即对话”。
-
在右侧配置栏的“System Prompt”处输入提示词(如图①),在输入框中输入问题(如图②),单击发送;在对话框中查看对话详情(如图③)。
总结
用户可通过LlamaFactory Online平台预置的模型结合下载的数据集完成快速微调与效果验证。从上述实践案例可以看出,基于Qwen3-8B模型,采用LoRA方法在ChatMed_Consult_Dataset和HuatuoGPT2-SFT-GPT4-140K数据集上进行指令微调,在医疗咨询、诊断建议等实际应用中展现出巨大的潜力和实用价值。
同时,若将微调后的Qwen3-8B模型与其他医疗技术和系统进行深度融合,也将为医疗行业带来更多的创新应用。例如,与医疗影像分析技术相结合,实现对疾病的更精准诊断;与远程医疗设备相连接,为患者提供更实时、更个性化的医疗服务;与电子病历系统集成,辅助医生更高效地管理患者信息和制定治疗方案等。