构建基于Qwen2-Audio-7B-Instruct的传统音乐语义解析系统
在当代文化内容与声音媒介深度融合的背景下,音频表达已成为构建角色生命力与情感张力的核心载体。用户对虚拟角色的互动期待已从“可见”转向“可感”——不仅要求语言内容符合角色设定,更追求音色、语调、情感韵律等听觉维度的真实还原,形成全感官沉浸的对话体验。
Qwen2-Audio-7B-Instruct语音增强版是面向沉浸式角色扮演场景深度优化的多语言音频对话模型。该模型在原版基础上,通过融合包含中、英等主流语言的高质量角色语音对话数据,结合中国传统五声音阶(宫商角徵羽)标注的声学特征,对语音语义与情感韵律进行联合微调,显著提升了对角色语言风格、情绪起伏及戏曲腔调、民乐伴奏等文化音韵的解析与生成能力。模型支持实时语音输入理解与拟人化语音回应生成,具备环境音感知、情感语调分析与人格一致性保持等特性,能够在对话中精准还原角色的声态个性与文化语境。其轻量化架构(7B参数)兼顾边缘设备部署效率与交互流畅性,为虚拟偶像互动、非遗角色活化、沉浸式叙事娱乐及跨模态艺术体验等场景提供了兼具技术深度与文化温度的解决方案。
前提条件
- 用户已经获取LlamaFactory Online平台账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
操作步骤
配置概览
| 配置参数 | 配置项 | 是否预置 | 说明 |
|---|---|---|---|
| 模型 | Qwen2-Audio-7B-Instruct | 是 | 经过指令微调,参数量约70亿 (7B),专为多语言语音理解与对话交互任务优化。 |
| 数据集 | CNPM_audio_train | 是 | 聚焦传统音乐调式识别任务,尤其适合智能音乐教育、传统乐曲辅助分析等文化科技场景。 |
| GPU | H800*4(推荐) | - | H800*2(最少)。 |
| 微调方法 | lora | - | 显著降低计算与存储成本,兼具高性能与部署灵活性。 |
资源消耗预览
- 模型微调时长
- 微调后模型Evaluate & Predict时长
- 原生模型Evaluate & Predict时长
操作详情
-
使用已注册的LlamaFactory Online账号登录平台,选择[实例空间]菜单项,进入实例空间页面,例如下图所示。
-
单击上图“开始微调”按钮,进入[配置资源]页面,选择GPU资源,卡数填写
4,其他参数保持为默认值,例如下图所示。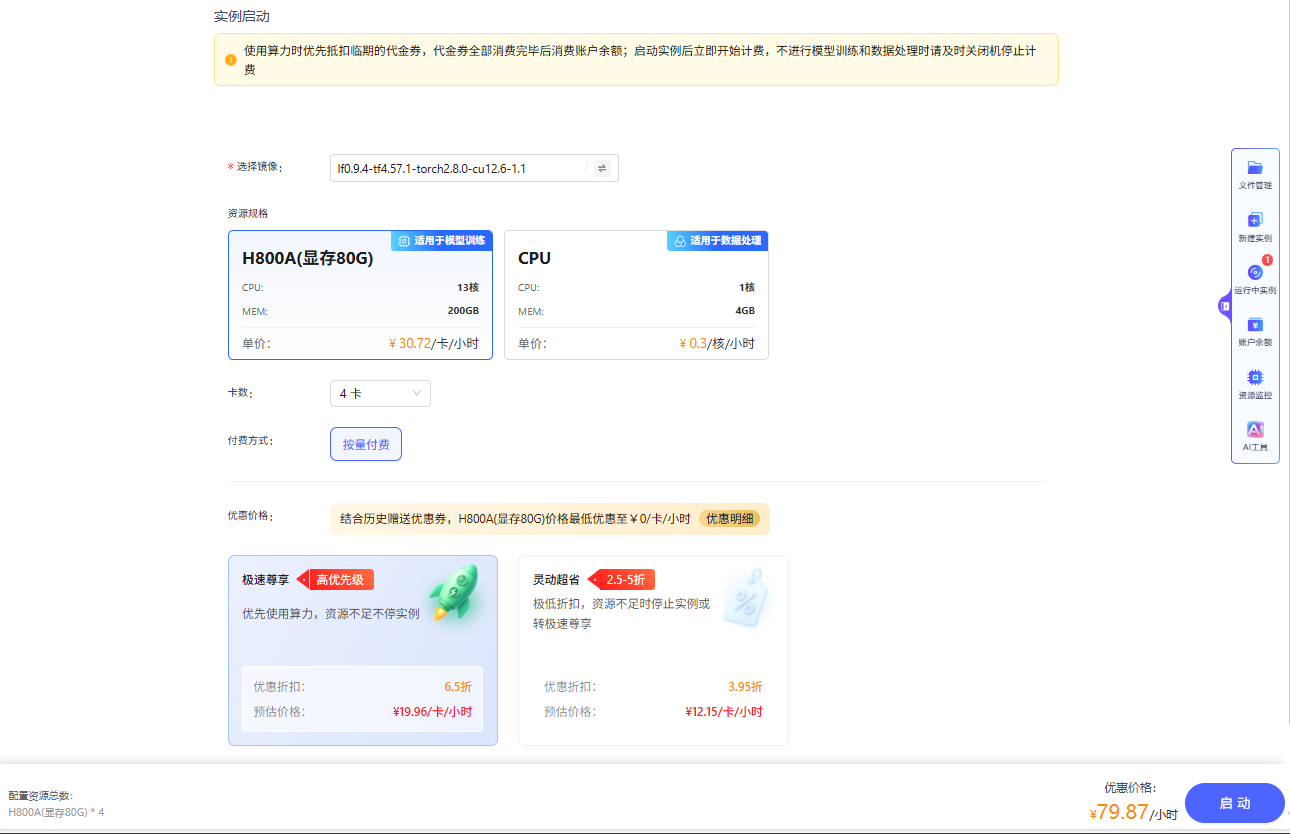
-
单击“启动”按钮,待实例启动后,点击[LlamaFactory快速微调模型]页签,进入LlamaFactory Online在线WebUI微调配置页面,语言选择
zh,如下图高亮①所示;模型名称选择Qwen2-Audio-7B-Instruct,如下图高亮②所示;系统默认填充模型路径/shared-only/models/Qwen/Qwen2-Audio-7B-Instruct。 -
微调方法选择
lora,如下图高亮④所示;选择“train”功能性,训练方式保持Supervised Fine-Tuning,如下图高亮⑤所示;数据路径保持/workspace/llamafactory/data,如下图高亮⑥所示;数据集选择平台已预置的CNPM_audio_train,如下图高亮⑦所示。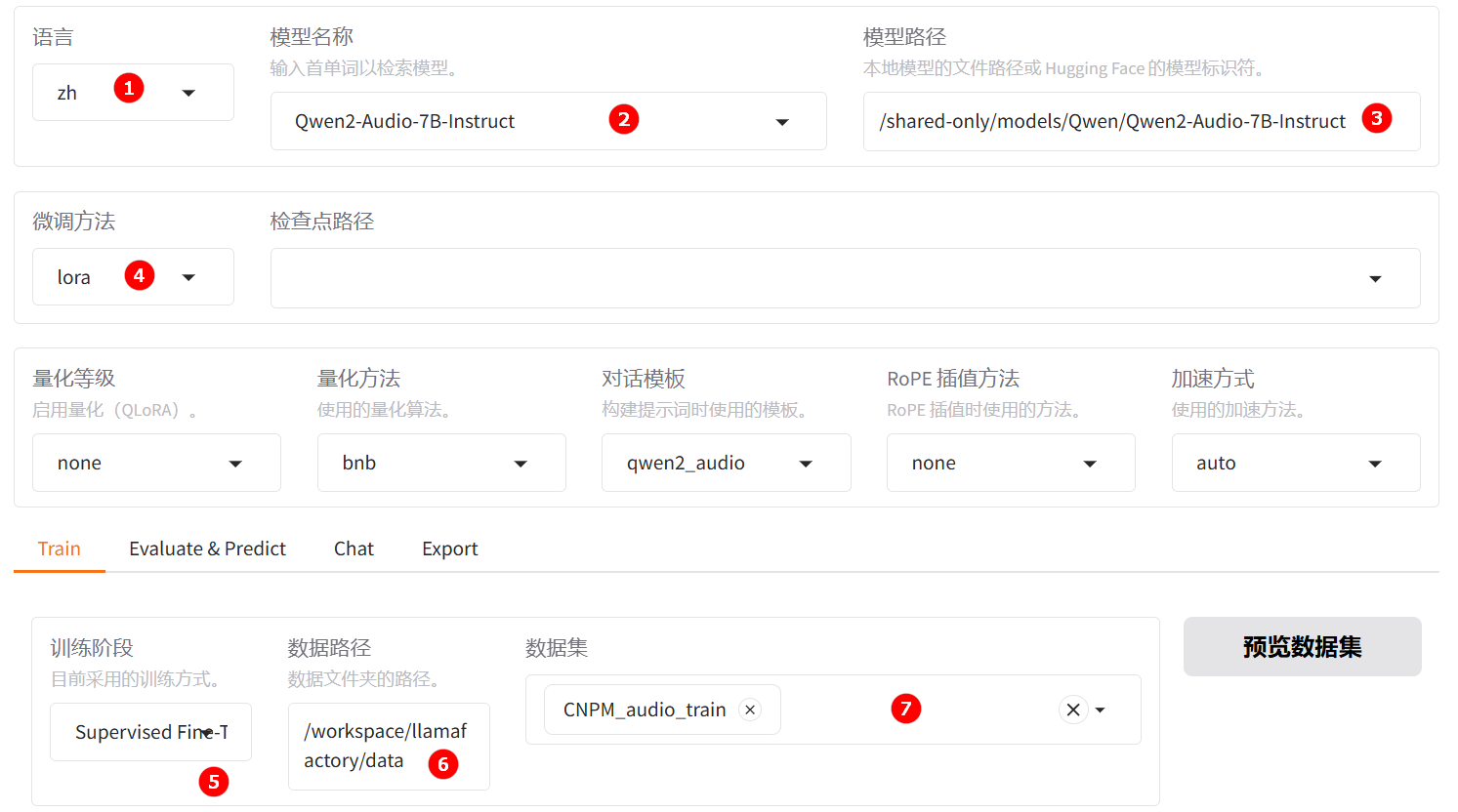
-
(可选)其余参数可根据实际需求调整,具体说明可参考参数说明,本实践中的其他参数均保持默认值。
-
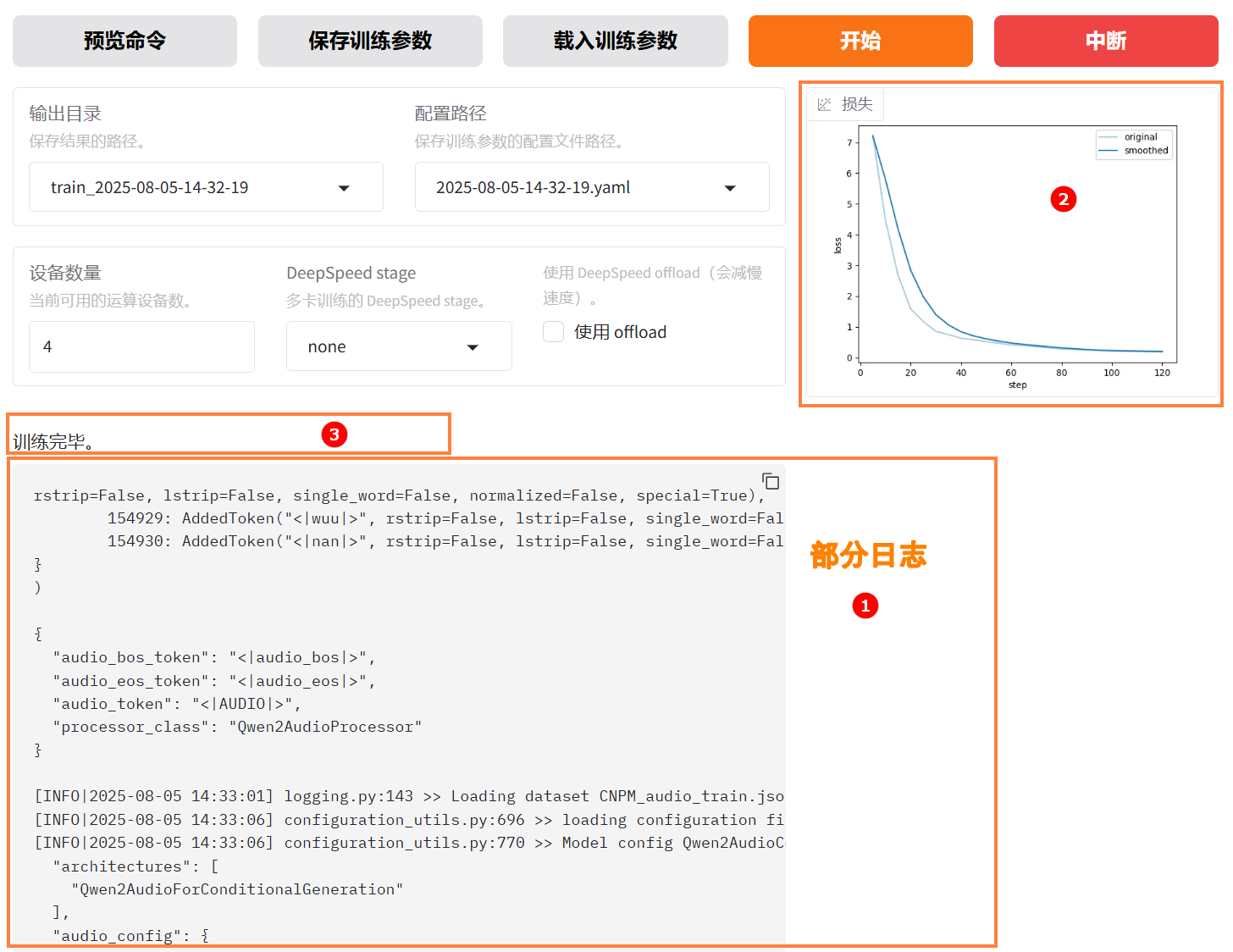
参数配置完成后,点击“开始”按钮启动微调任务。页面底部将实时显示微调过程中的日志信息,例如下图高亮①所示;同时展示当前微调进度及Loss变化曲线。经过多轮微调后,例如下图高亮②所示,从图中可以看出Loss逐渐趋于收敛。微调完成后,系统提示“训练完毕”,例如下图高亮③所示。
- 微调后模型对话
- 原生模型对话
-
切换至“chat”界面,如下图高亮①所示;选择上一步骤已经训练完成的检查点路径,如下图高亮②所示;单击“加载模型”按钮,微调的模型加载后,在系统提示词处填入提示词,如下图高亮③所示;在“Audio”传入解压后的示例音频,如下图高亮④所示,输入用户模拟词“这段音乐是什么调式?”,观察模型回答,如下图高亮⑥所示。
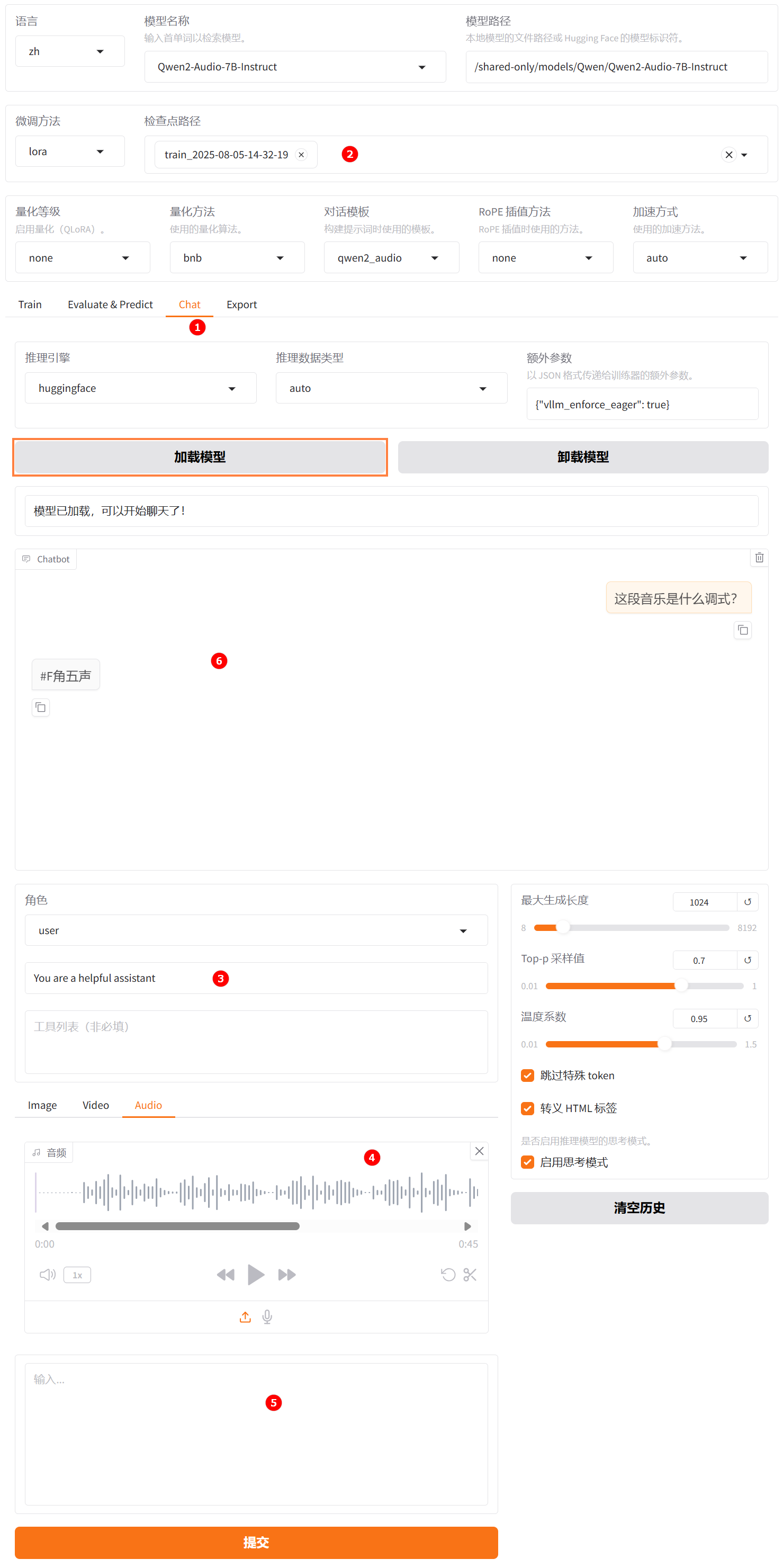
-
清空“检查点路径”中的LoRA配置,单击下图高亮②所示的“卸载模型”按钮,卸载微调后的模型,模型卸载完成后,单击“加载模型”按钮,加载原生的
Qwen2-Audio-7B-Instruct模型进行对话,其余配置保持不变。用户模拟词依旧输入“这段音乐是什么调式?”,观察模型回答,如下图高亮⑦所示。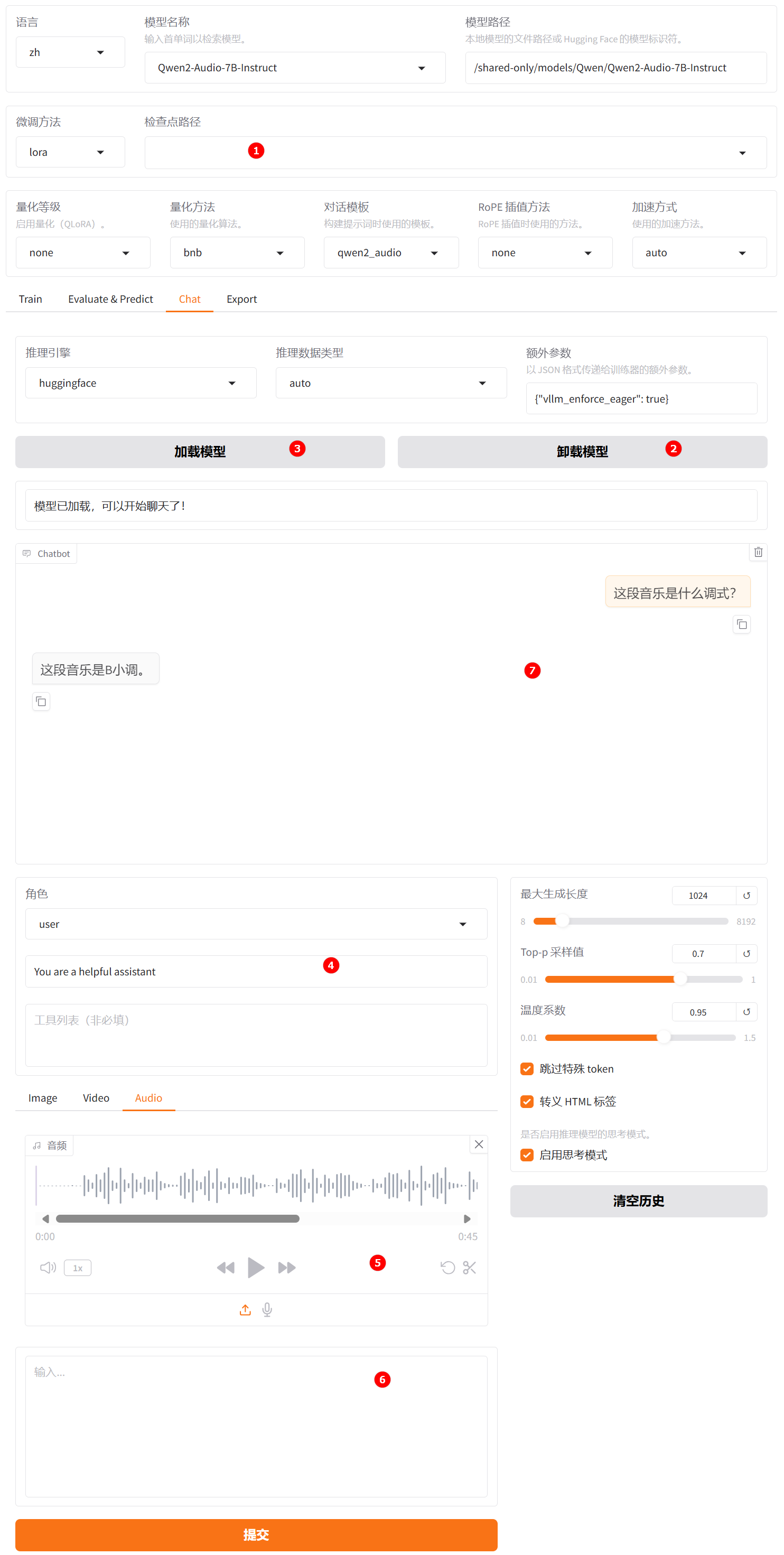
通过对比微调模型与原生模型的输出结果可以发现,微调后的模型在角色扮演方面表现出更强的契合度,其回答不仅更贴近系统预设的角色定位,也更符合用户的认知预期。
- 微调后模型评估
- 原生模型评估
-
切换至“Evaluate & Predict”页面,选择微调后模型的检查点路径,例如下图高亮①所示;然后选择平台预置的
CNPM_audio_train数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。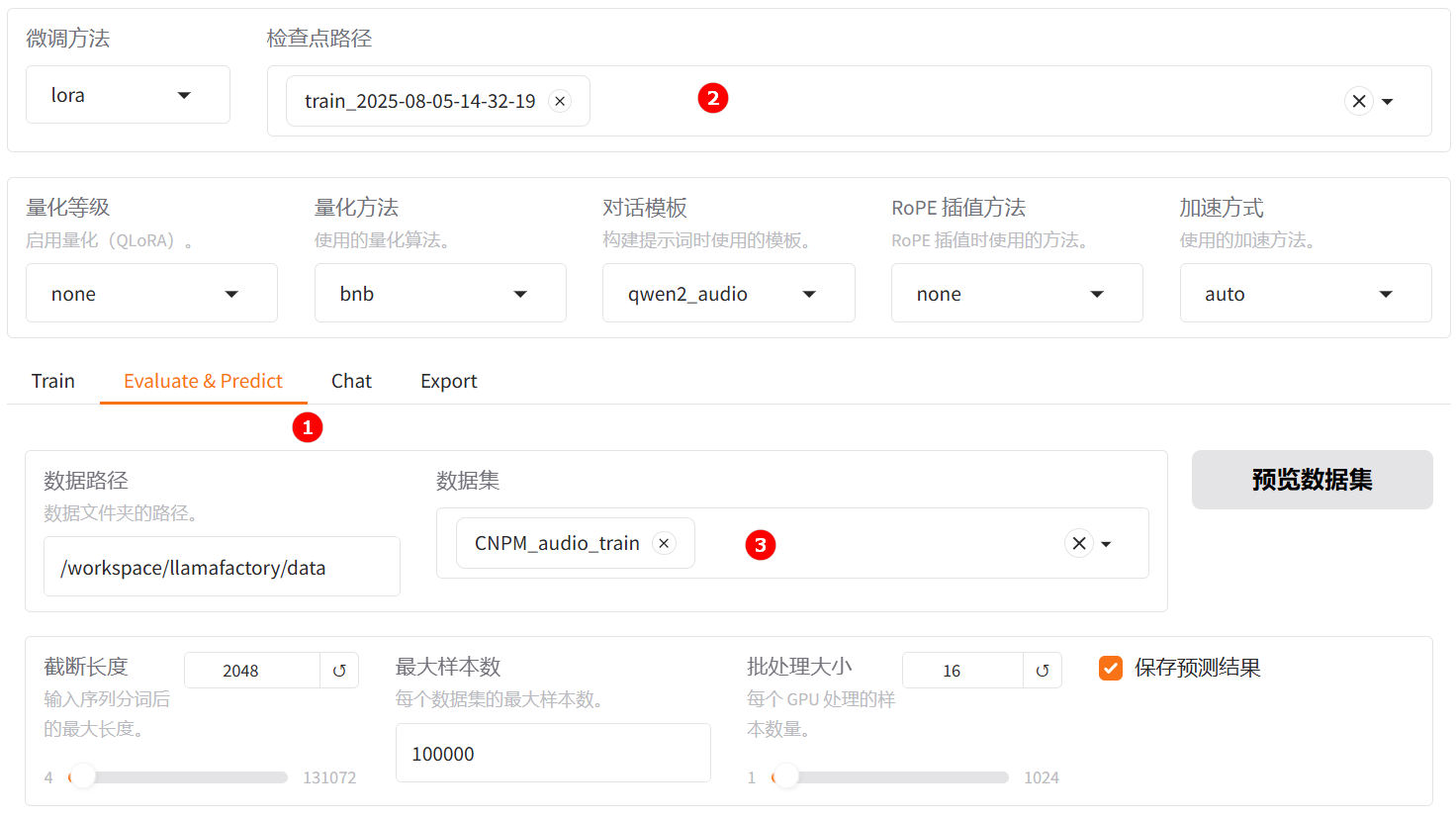
-
配置完成后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 52.251510546875,
"predict_model_preparation_time": 0.0068,
"predict_rouge-1": 69.82624921875,
"predict_rouge-2": 60.547182421875,
"predict_rouge-l": 69.466005859375,
"predict_runtime": 37.407,
"predict_samples_per_second": 6.496,
"predict_steps_per_second": 0.107
}结果解读:评价指标:
BLEU-4:52.25,ROUGE-1:69.83,ROUGE-2:60.55,ROUGE-L:69.47,各项指标均表明生成内容与参考答案在词汇、短语、句子结构和语义连贯性上高度匹配,具备良好的语言流畅性和信息覆盖能力。
-
切换至“Evaluate & Predict”页面,清空检查点路径配置,数据集依旧选择平台预置的
CNPM_audio_train数据集,并根据实际需求配置评估参数(本实践的参数设置如下图所示)。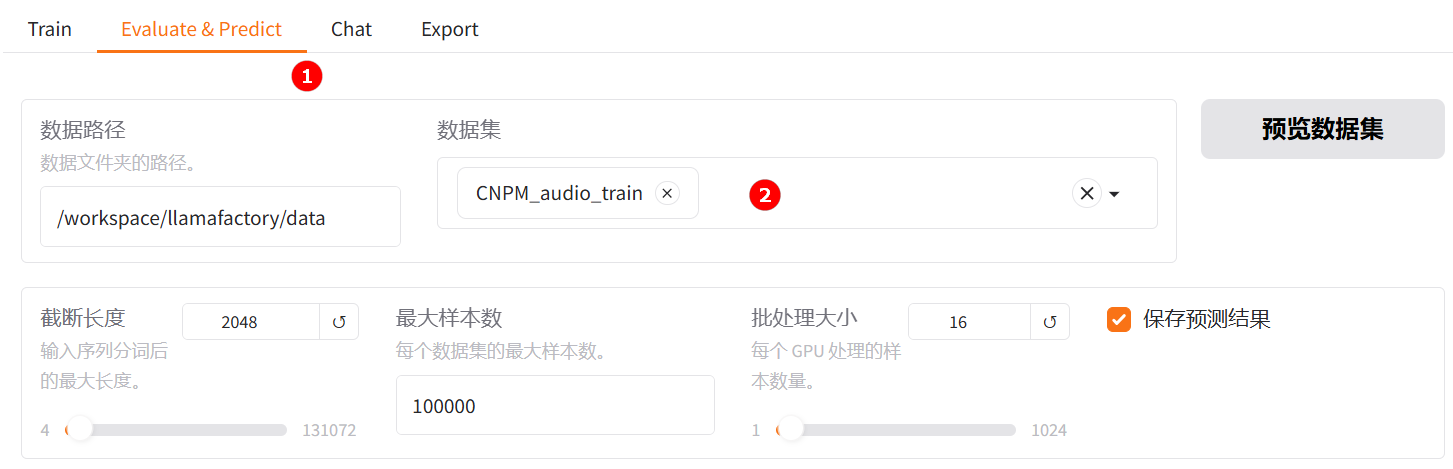
-
完成配置后,点击“开始”按钮即可启动评估,页面底部将实时显示评估过程中的日志信息,评估完成后,记录评估结果,结果如下所示。
{
"predict_bleu-4": 3.554647265625,
"predict_model_preparation_time": 0.0068,
"predict_rouge-1": 8.048133203125,
"predict_rouge-2": 0.078125,
"predict_rouge-l": 7.927941015624999,
"predict_runtime": 33.477,
"predict_samples_per_second": 7.259,
"predict_steps_per_second": 0.119
}结果解读:评价指标
BLEU-4:3.55,ROUGE-1:8.05,ROUGE-2接近0(0.078),ROUGE-L:7.93,各项指标均表明生成内容与参考答案在词汇、短语和句子结构上几乎无有效匹配,语义连贯性和信息覆盖度严重不足,生成质量有进一步提升。
对比微调后模型评估与原生模型评估结果可以看出,微调后模型在生成质量上表现优异(BLEU-4: 52.25, ROUGE-L: 69.47),表明其能生成语义准确、结构连贯的高质量输出;原生模型所有生成指标极低(BLEU-4: 3.55, ROUGE-L: 7.93),说明模型未能有效理解或生成相关内容。这反映出微调后模型具备实用价值。
总结
用户可通过LlamaFactory Online平台预置的模型及数据集完成快速微调与效果验证。从上述实践案例可以看出,基于Qwen2-Audio-7B-Instruct模型,采用LoRA方法在CNPM_audio_train角色扮演数据集上进行指令微调后,模型在角色语言风格还原、人格一致性与上下文理解能力方面均有显著提升。
经过深度微调,Qwen2-Audio-7B-Instruct语音增强版在角色音频交互领域实现了技术与人文的有机融合。模型不仅显著提升了对多语言语音语义与情感韵律的精准建模能力,更创新性地融入中国传统五声音阶的声学特征,强化了对戏曲腔调、民乐氛围与文化语境的感知与生成。推动AI在文化传承、艺术创新中的深度应用。