JupyterLab
JupyterLab处理专属数据 更新时间:2025-11-04 18:00:00
“JupyterLab处理专属数据”为您提供了自主处理数据的空间,并支持构建自定义环境(放在/workspace目录下的文件关机后会保留),以便模型微调更加顺利的进行。同时,您也可以在JupyterLab通过终端命令实现模型微调和评估。
前提条件
- 您已经获取LlamaFactory Online账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,或前往充值,如需了解更多请联系我们。
- 您已经准备好需要处理的自定义数据集。数据上传方式可参考数据上传中的JupyterLab上传和SFTP上传下载。
概览
进入实例空间,点击“开始微调”选择合适的配置,启动实例后,点击右侧“JupyterLab处理专属数据”,即可进入JupyterLab工作空间。
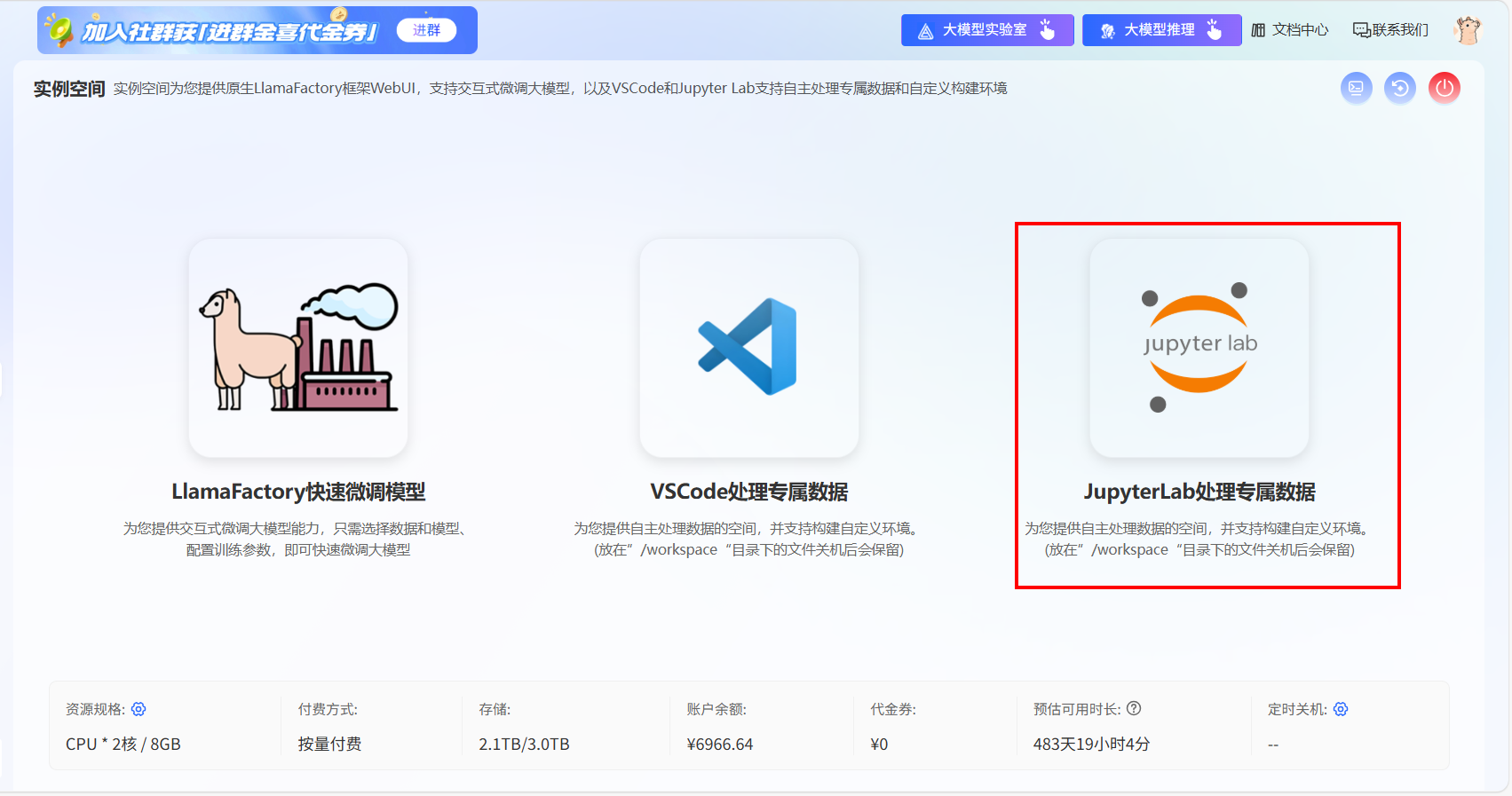
CPU实例资源配置卡数支持:2、4、8、16卡,您可按需选用。
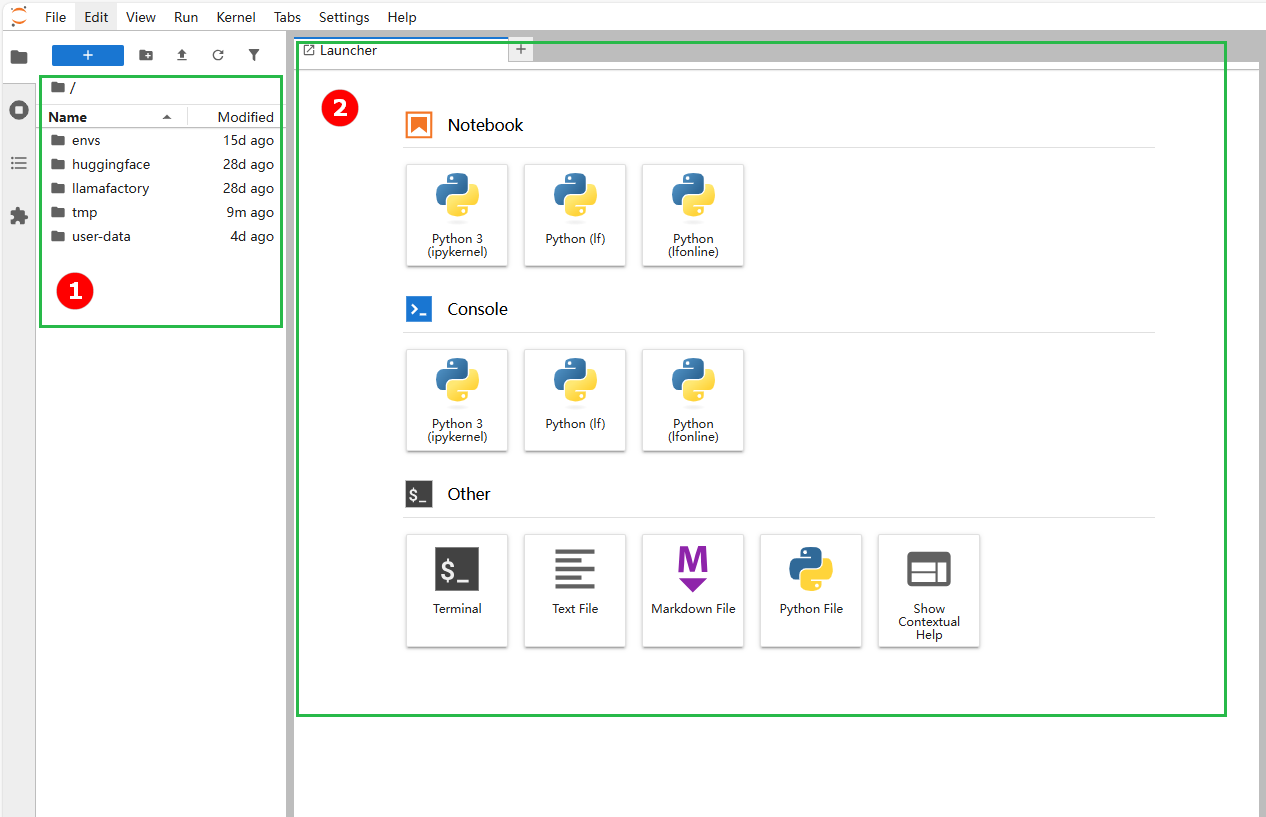
在JupyterLab工作空间,用户可以进行环境配置,下载模型、数据集,处理数据等微调模型的前期准备工作,也可以在终端通过命令进行模型微调和模型评估。高亮区域按序号说明如下。
① 文件目录。具体介绍请参考目录。
② 启动面板(Launcher)。 启动面板提供图形化界面,用户可以在该界面快速启动终端、Notebook、控制台、文本文件等。
操作步骤
环境配置
在 JupyterLab 的工作空间中,用户可以通过 conda 创建和管理不同的 Python 环境,envs 文件夹就是这些环境的具体存储位置。这样可以方便用户隔离不同项目的依赖,保证环境的独立和稳定。
-
默认的python环境
在 JupyterLab 的工作空间中,envs文件夹下的If_pkgs文件夹用于存储默认python环境的依赖工具。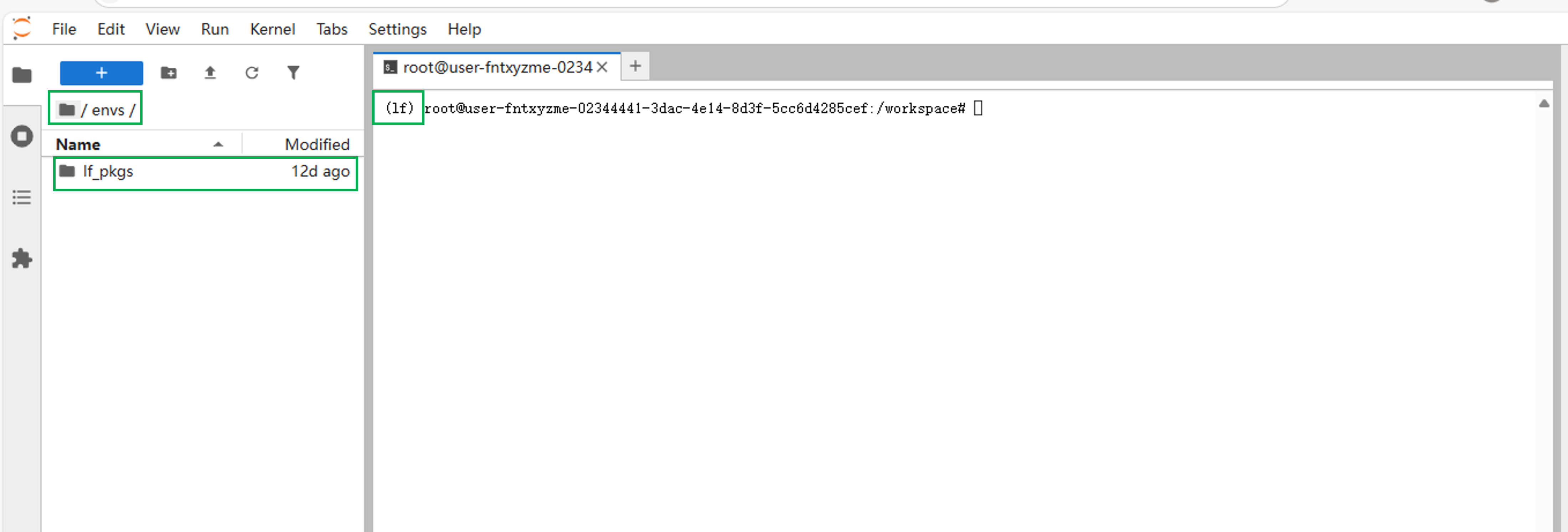 在终端输入命令
在终端输入命令conda env list,查看conda环境目录。"*"表示当前处于默认的"If"环境中。
-
自定义创建python环境
用户也可以根据需求创建新的python环境,步骤如下:
-
点击启动面板下方的"Terminal"进入终端。
-
输入命令创建新环境。用户可根据需求命名和选择合适的python版本。
conda create -n [name] python=[vision]提示本示例创建了一个名字为"test",python版本为3.11的新环境,故:
[name]:test
[vision]:3.11 -
下载完成后,可以看到envs目录下会新增一个“test”文件夹。输入命令可以切换到test环境中。
conda activate test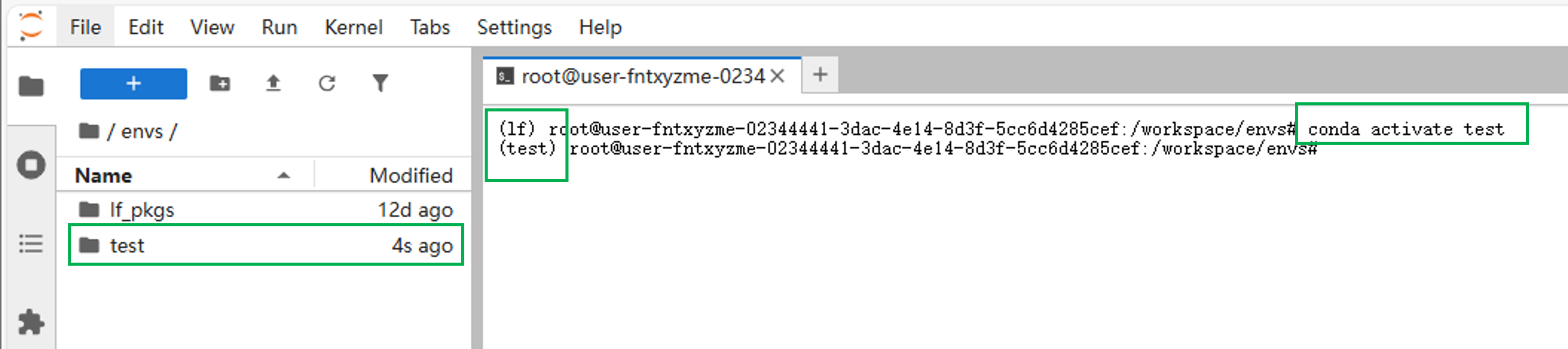
可以使用命令下载您需要的工具。(以下载用于python数据分析的pandas工具包为例)
conda install pandas提示- 可以在终端输入以下命令,查看 conda 的所有命令列表:conda --help
- 或者只看子命令列表:conda list
- 如果想看某个命令的详细用法,比如环境相关:conda env --help
使用Hugging Face工具下载模型
JupyterLab 工作空间文件目录下的“huggingface”文件夹是Hugging Face工具自动创建的本地缓存目录,可以用来存放下载的预训练模型文件、数据集缓存。
- huggingface下载模型操作步骤(以下载Qwen2.5-1.5B-Instruct为例)。
- 在JupyterLab工作空间中,点击启动面板(Launcher)中的"Terminal"进入终端。
- 在终端输入下载命令,完成下载。可以看到模型被放在
/huggingface/hub下方。huggingface-cli download --resume-download Qwen/Qwen2.5-1.5B-Instruct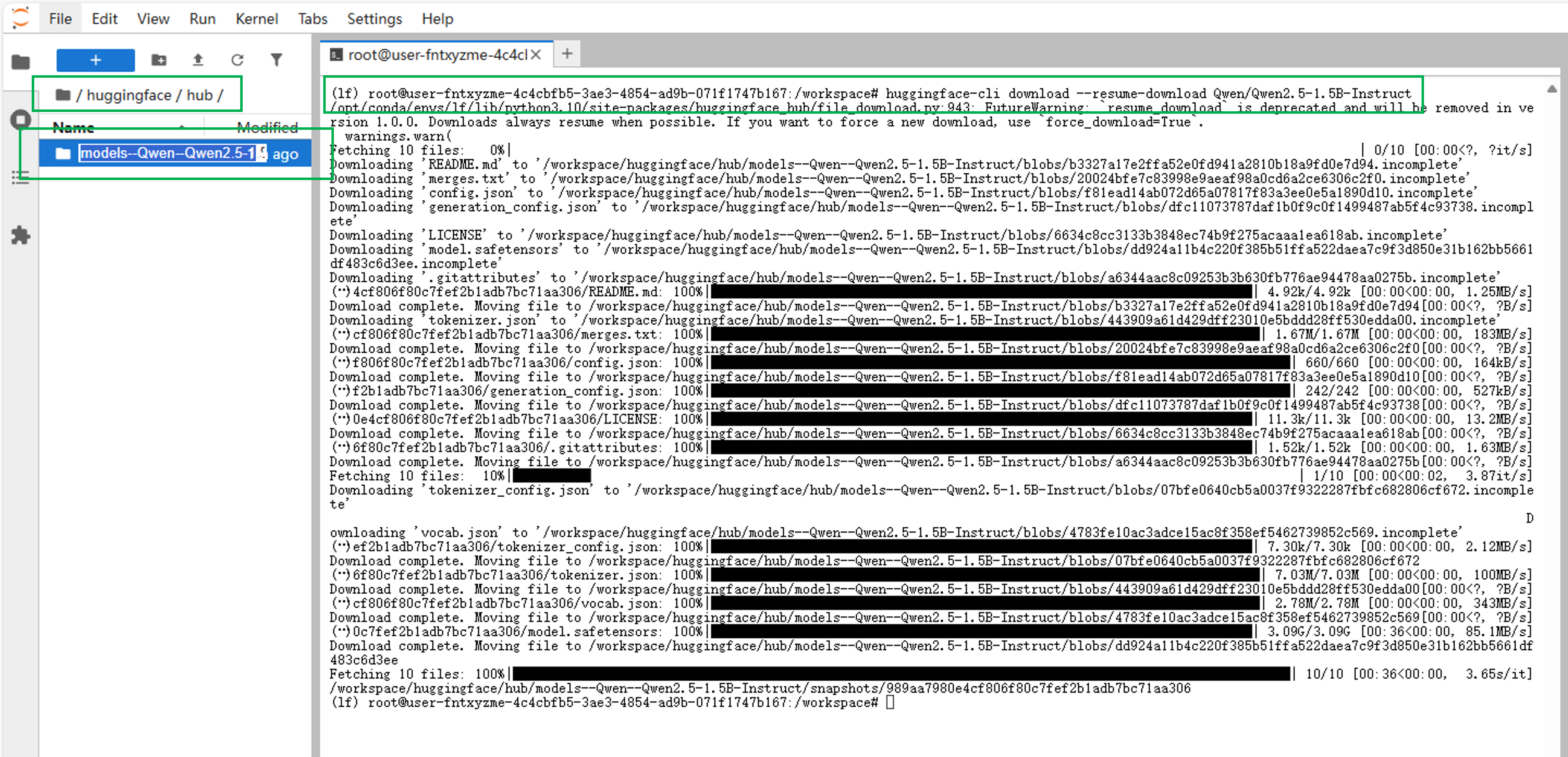
数据处理
数据集上传
用户可以通过JupyterLab上传自定义数据集。下面将以上传一份医学诊断数据集为例,来演示数据上传的流程。
- 在导航栏,点击
 切换到文件浏览器,进入到
切换到文件浏览器,进入到/llamafactory/data目录下。 - 新建文件夹。点击导航区域上方的
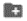 新建文件夹,或在导航区域的空白处点击鼠标右键新建文件夹。文件夹命名为"medical_sft"。
新建文件夹,或在导航区域的空白处点击鼠标右键新建文件夹。文件夹命名为"medical_sft"。
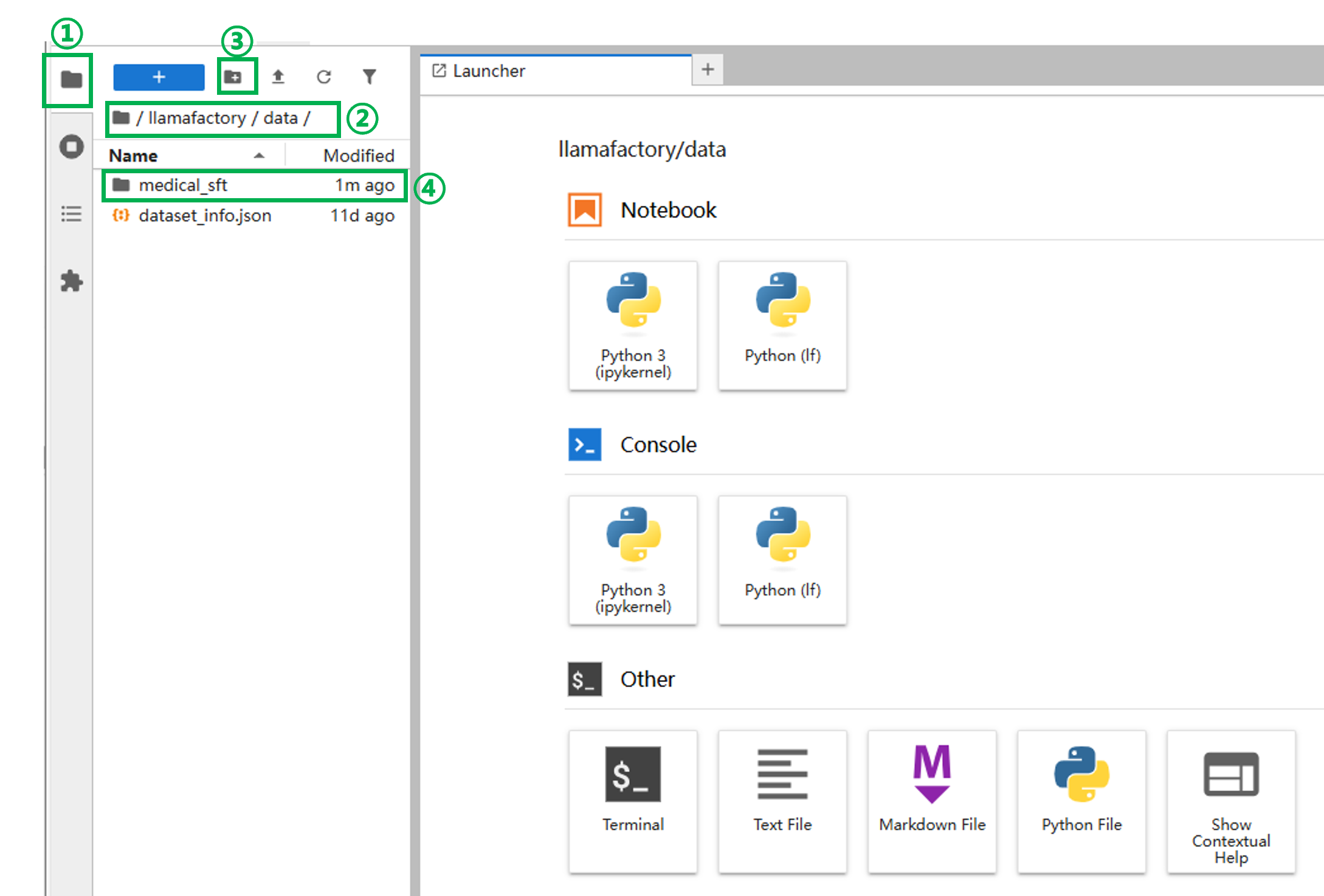
-
将本地数据集“medical_o1_sft_Chinese_alpaca_cot.jsonl”拖到
/llamafactory/data/medical_sft目录下。完成数据上传。
数据集配置
用户可以通过配置"dataset_info.json"文件,在微调模型界面中使用自己上传的数据集。
这里我们以数据集上传中上传的数据集为例,来演示如何配置"dataset_info.json"文件。
-
进入到
/llamafactory/data目录,以可编辑的形式打开"dataset_info.json"文件。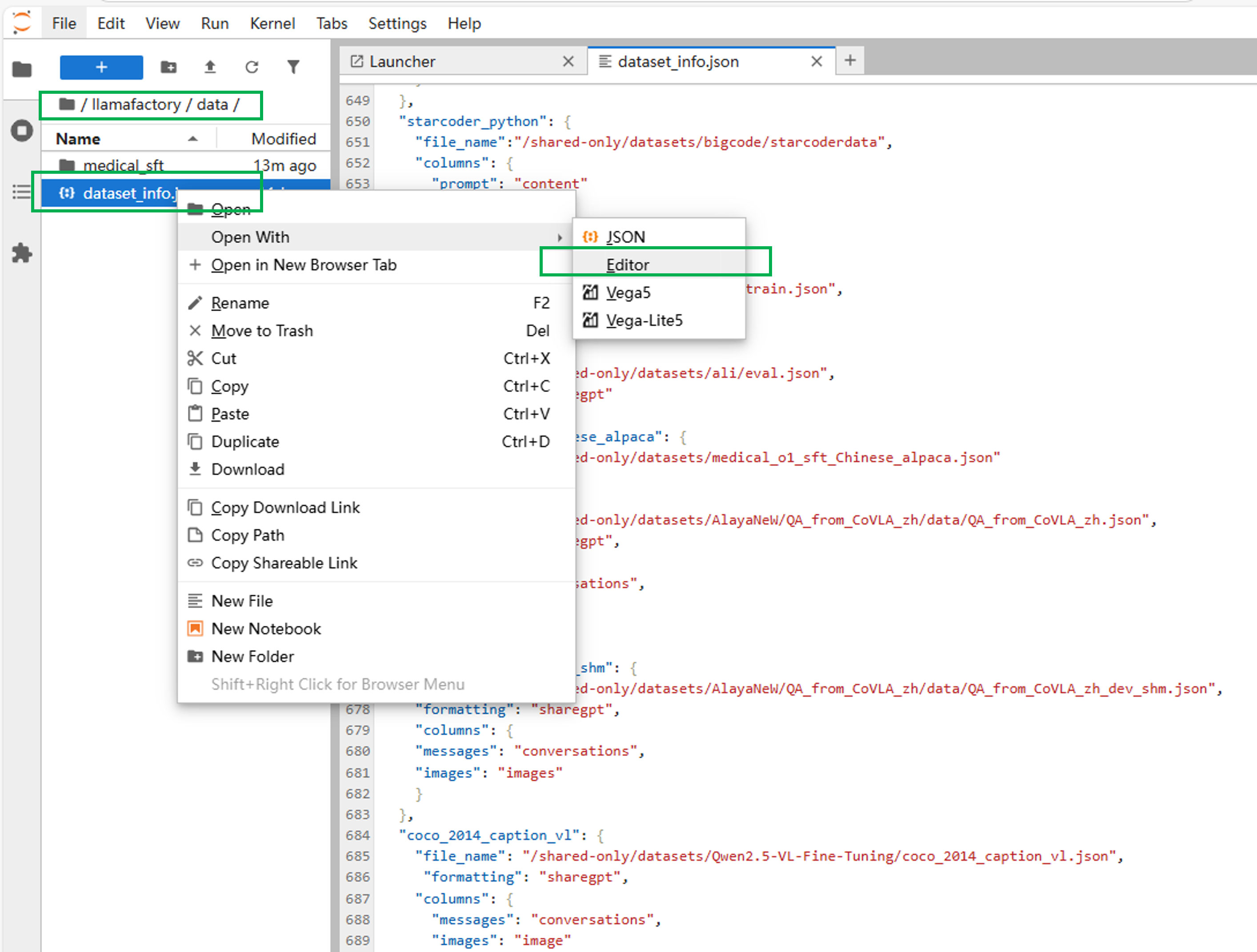
-
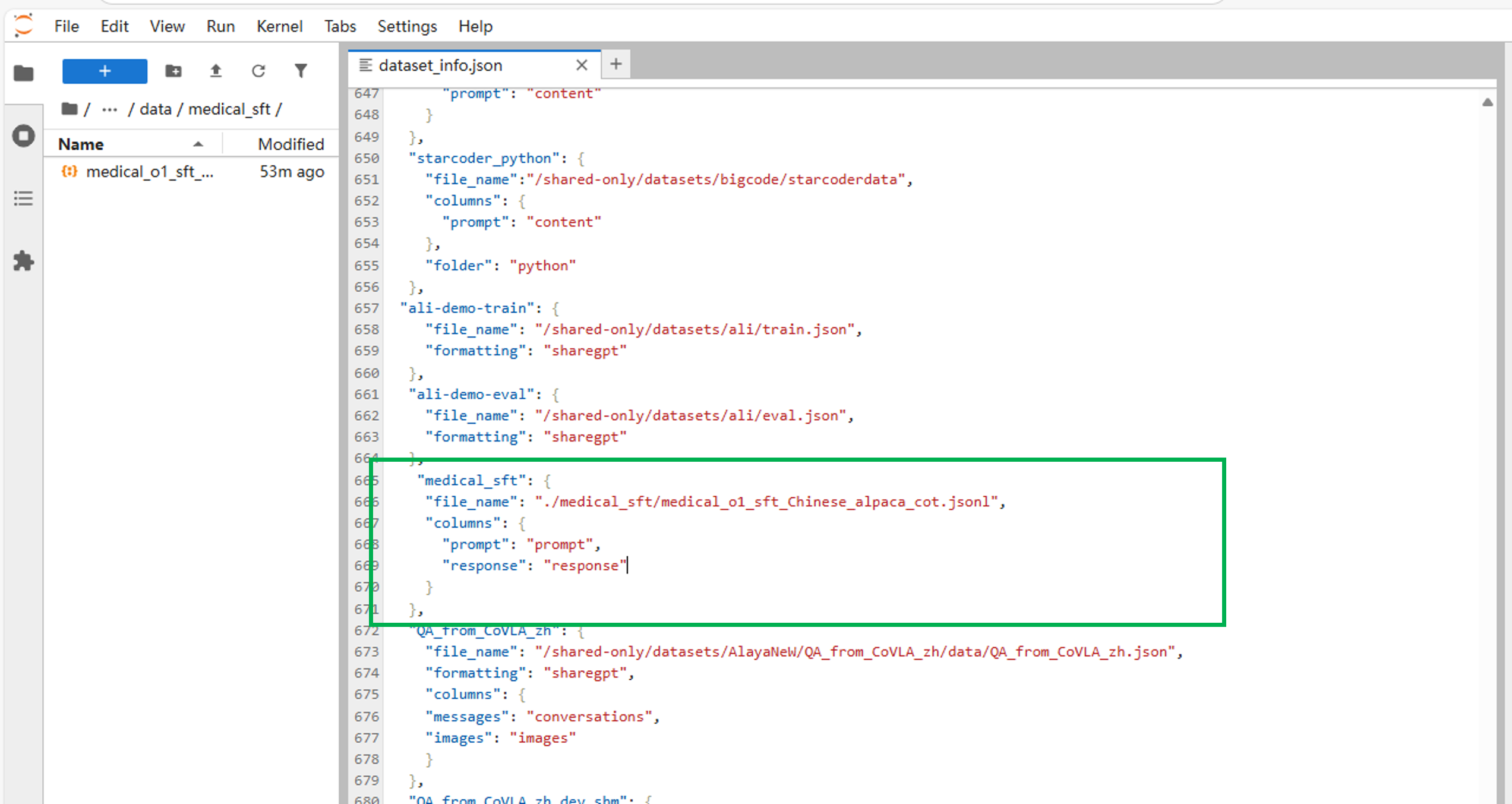
在"dataset_info.json"文件下添加以下代码。注意末尾的","是否需要,视情况而定(如果添加在其他对象之前,需要加“,”,如果添加在最后则不用,但要在前一个对象末尾加上“,”)。
"medical_sft": {
"file_name": "./medical_sft/medical_o1_sft_Chinese_alpaca_cot.jsonl",
"columns": {
"prompt": "prompt",
"response": "response"
}
},
-
验证配置数据集。
-
回到"LlamaFactory快速微调模型" Web UI页面,在数据集列表中找到“medical_sft”。 LlamaFactory快速微调模型
-
预览数据集。

数据转换
若用户从本地上传数据集后,需要对数据进行处理,可以参考数据转换。
模型训练
JupyterLab 中,用户可以通过终端使用命令进行模型微调,步骤如下。
-
获取微调命令。
- 回到“实例空间”页面,点击左侧“LlamaFactory快速微调模型”进入webUI界面。
- 配置参数。确定微调模型和数据集,根据需求配置其他参数。完成后点击页面下方“预览命令”,如下图高亮①所示;点击
 复制,如下图高亮②所示。
复制,如下图高亮②所示。
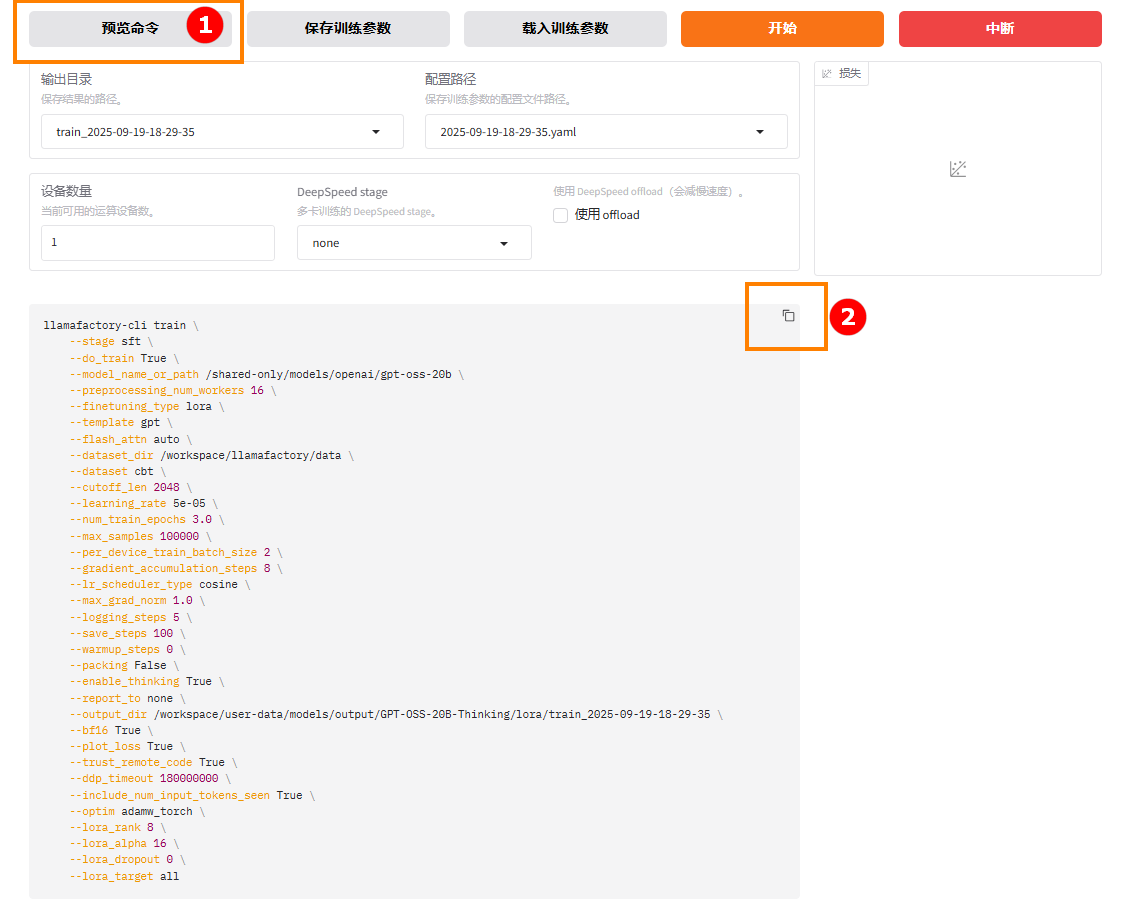
-
回到JupyterLab页面,点击启动面板(Launcher)中的"Terminal"进入终端。
-
将步骤2中获取的命令复制在终端命令行中,点击回车键开始训练。
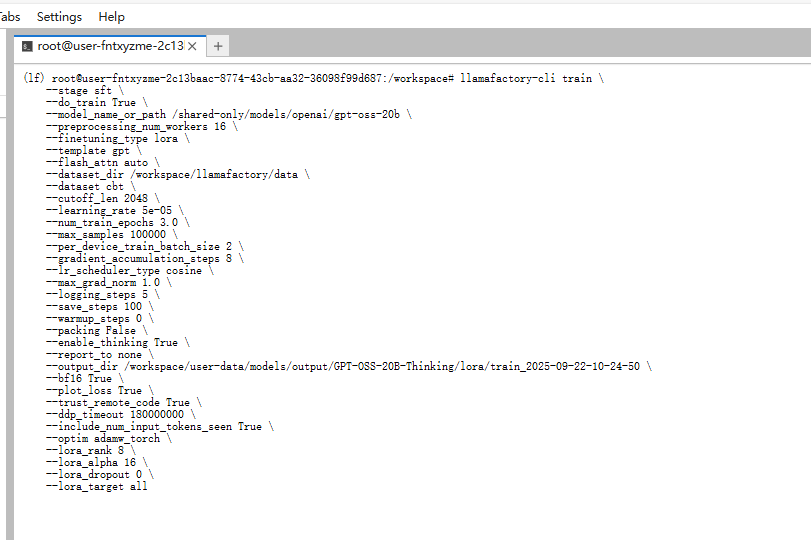
-
查看训练结果。 训练结束后,在路径
user-data/models/output下查看训练结果。
模型评估
- 目前LlamaFactory Online webUI不支持多卡评估,若模型部署和推理所需显存超过75G,则在LlamaFactory Online webUI上单卡无法进行模型评估,所以需要在jupyterlab的终端内运行LlamaFactory项目中的vllm_infer.py脚本,进行分布式评估。
- 一般情况下,当模型参数量达到32B及以上时,就需要使用多卡评估。
-
开始评估。 在jupyterlab上进行模型评估可参考《构建基于Llama3.1-70B的医疗诊断系统》的步骤8-12。
提示步骤中涉及到的文件目录名,模型路径,文件保存路径等,需要按照真实情况进行修改。
-
查看评估结果。 评估完成后,结果保存在路径
user-data/models/output下。