安装Flash Attention系统提示OOM问题排查
问题表现
用户在[JupyterLab处理专属数据/Terminal]终端页面自定义环境下运行如下所示的命令安装Flash Attention时页面持续停留在编译页面,例如下图所示。
pip install flash-attn -i https://pypi.tuna.tsinghua.edu.cn/simple
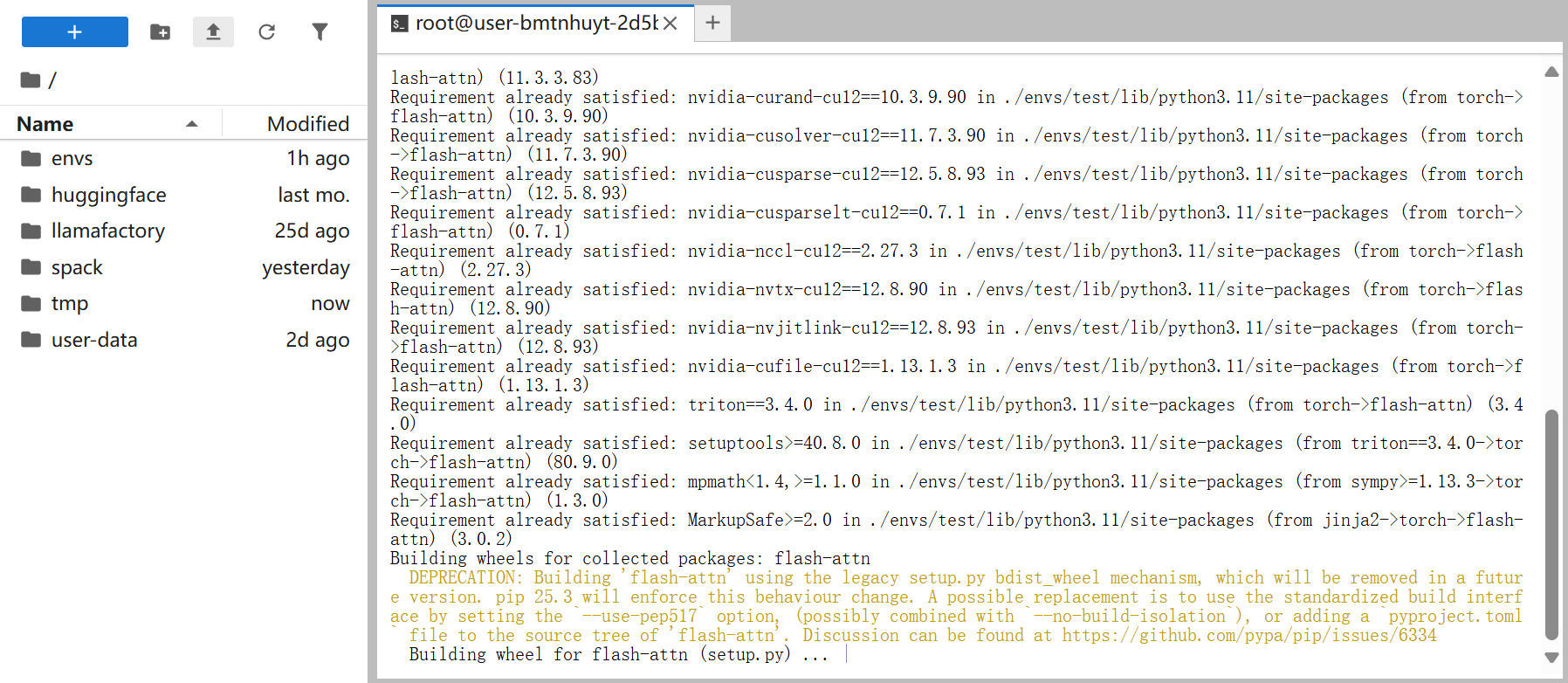 运行一段时间后,实例自动重启导致终端连接自动重连,系统弹窗如下所示。
运行一段时间后,实例自动重启导致终端连接自动重连,系统弹窗如下所示。
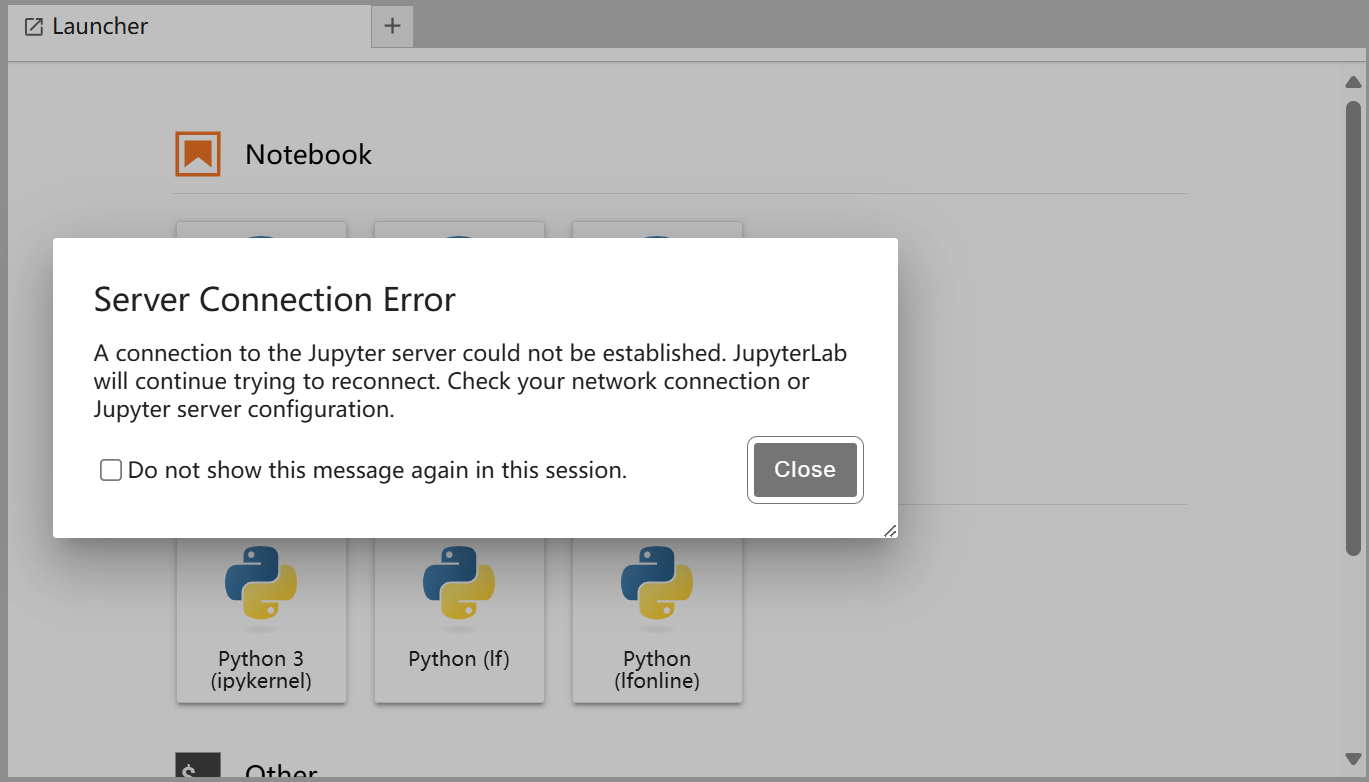
问题原因
在使用上述命令远程安装flash-attn时,系统将从源码进行编译构建。该过程涉及复杂的CUDA内核编译,由nvcc执行。由于编译过程中包含大量优化操作,并可能并行处理多个.cu文件,需频繁加载和存储庞大的中间数据结构,导致内存占用急剧上升,容易触发OOM(Out of Memory)错误,进而造成实例重启,需重新建立终端连接。
根据上述现象可知,采用源码编译方式安装Flash Attention对系统内存资源要求较高。为确保编译过程稳定,建议配置充足的内存资源。我们推荐系统至少配备400GB内存,建议至少选用H800 * 4卡GPU资源,以提升安装成功率与构建效率。
解决办法
-
打开[JupyterLab处理专属数据/Terminal]页面,在终端页面依次输入如下所示的命令查看PyTorch的版本。

-
访问Flash Attention公开的仓库地址,下载对应Python版本和cuda版本的release包,以
flash_attn-2.8.3+cu12torch2.7cxx11abiTRUE-cp310-cp310-linux_x86_64.whl为例。 -
下载完成后,返回[JupyterLab处理专属数据/Terminal]页面,单击
 新建一个
新建一个local_pkgs目录,然后将上步下载的文件拖拽至/workspace/local_pkgs目录下。提示您创建的目录应在
/workspace目录下。 -
在终端运行如下所示的命令,在本地直接安装预编译好的
flash-attn高性能二进制库。pip install /workspace/local_pkgs/flash_attn-2.8.3+cu12torch2.7cxx11abiTRUE-cp310-cp310-linux_x86_64.whl