数据集生成
数据生成主要是为大模型训练或微调提供不同类型的数据生成方案,页面提供了两个核心工具:
- GraphGen:基于知识图谱自动生成多跳专业问答对,专注于为垂直领域的大模型注入精准知识,帮助模型攻克复杂推理类难题。
- FastDatasets:通过解析文档并结合模板批量生成指令数据,旨在快速构建通用大模型的指令遵循能力,从而大幅提升数据生成的准确率与效率。
用户可根据自身需求,选择适合的数据生成工具,以支持后续模型训练或优化工作。
前提条件
- 您已经获取LlamaFactory Online账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 如果您调用Baicai Infer(白菜AIGC)API服务,请确保账户余额足以支付调用费用,详情请参考计费规则、账户充值。使用其他模型API服务时,请确保该服务处于可用状态。
概览
在数据生成界面,您可以选择使用GraphGen或FastDatasets生成所需的数据集,页面如下图所示。

操作步骤
启动任务
- GraphGen
- FastDatasets
GraphGen首先基于源文本构建细粒度知识图谱,利用期望校准误差指标识别大模型的知识缺口,优先生成高价值长尾知识的问答对。此外,它通过多跳邻域采样捕获复杂关系,并结合风格控制生成,丰富问答数据的多样性。
-
使用已注册的LlamaFactory Online账号登录平台,选择[数据与模型/数据生成]菜单项,进入数据生成工具选择页面,选择“GraphGen”,例如下图所示。
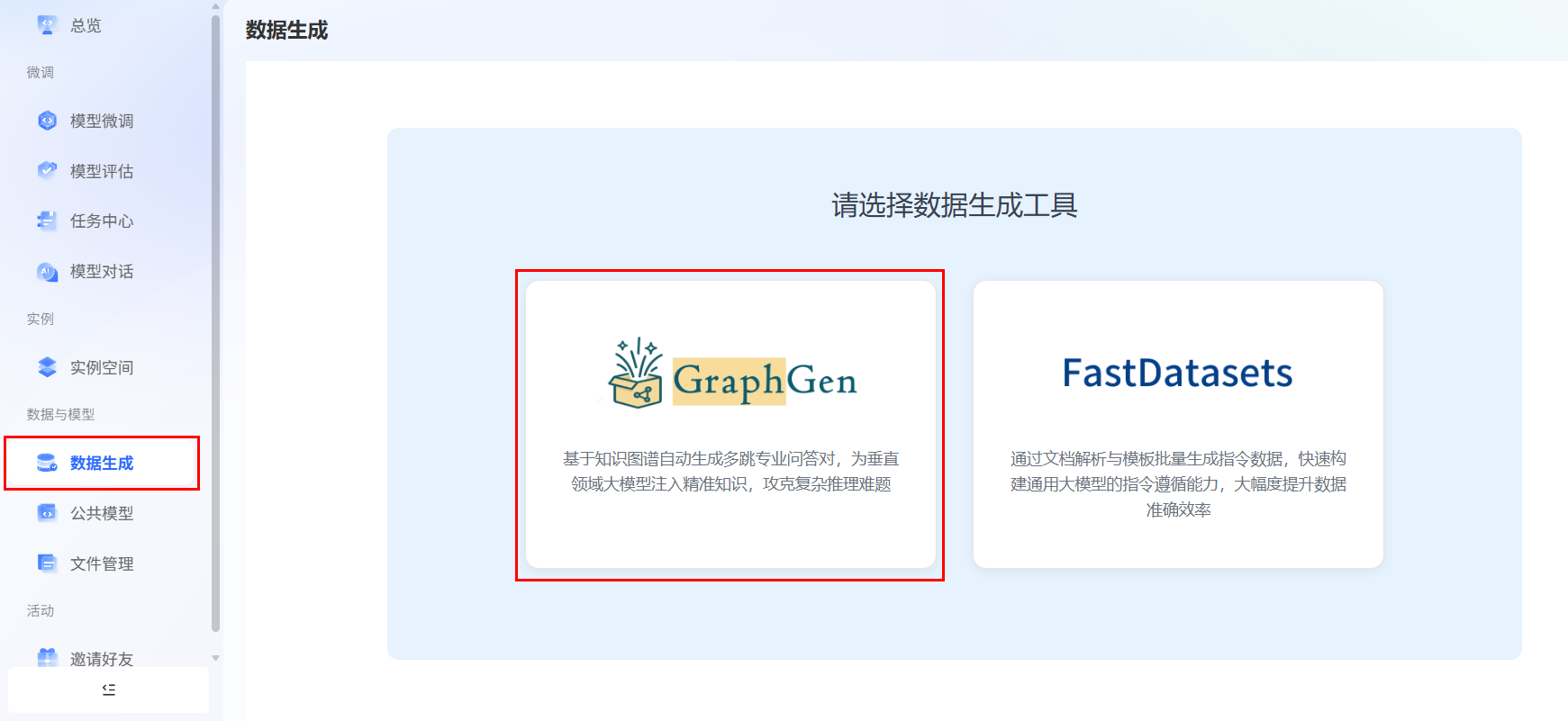
-
在GraphGen数据生成页面配置各参数,参数详情请参考下表,配置页面如下图所示。
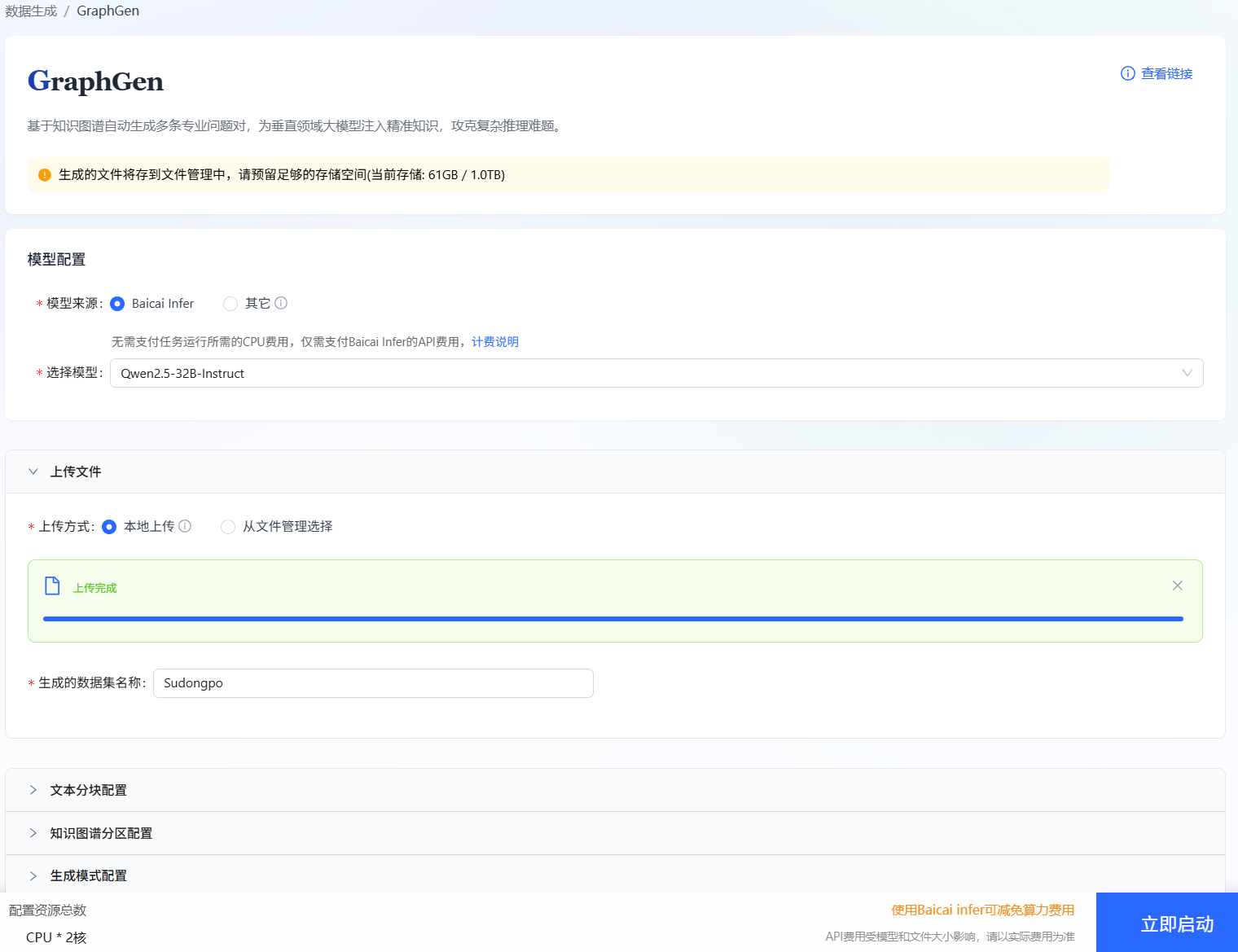
参数配置信息如下表所示:
序号 参数项 说明 1 模型来源 选择模型的服务提供商。
- 您可选择“Baicai Infer”作为生成数据集调用API服务的模型,该来源主要支持的模型有:Qwen2.5-32B-Instruct、Qwen3-32B以及Qwen2.5-VL-32B-Instruct。
- 您可选择“其它”模型来源,该来源需要您配置模型的模型地址(BaseURL/v1)、model以及调用模型的API Key,例如下图所示。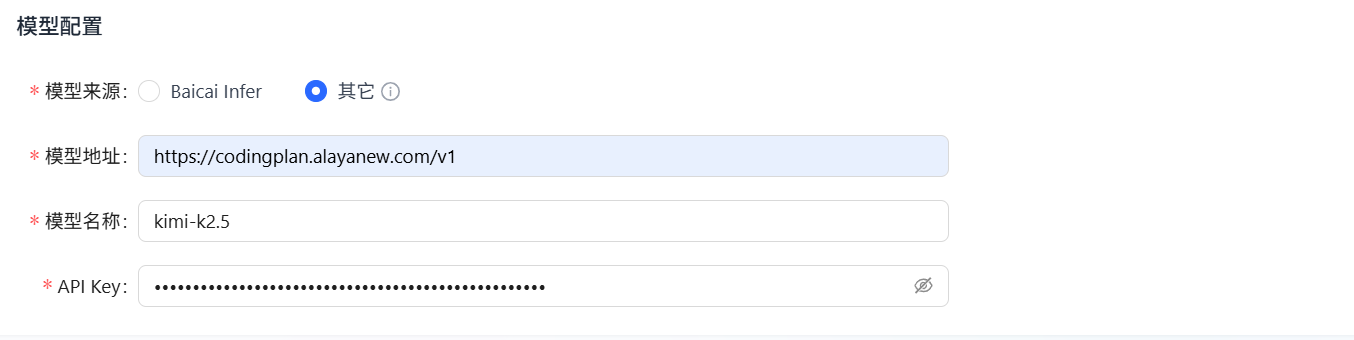
2 上传方式 选择GraphGen生成数据集的源文本,
- 您可选择通过“本地上传”上传本地文件。
- 您也可以选择“从文件管理选择”,例如下图所示。
3 生成的数据集名称 用户自定义生成数据集的名称,例如:“Sudongpo”。 4 文本分块配置 - 分块大小 (Chunk Size):设定将长文本切分成的每个片段的最大Token数量,以便模型能够处理。
- 分块重叠 (Chunk Overlap):设定相邻文本块之间重复内容的长度,以保持上下文语义的连贯性。5 知识图谱分区配置 - 分区方法 (Partition Method):选择用于构建知识图谱时对数据进行分区的特定算法策略。
- ECE最大单元数 (ECE Max Units):限制每个分区中包含的最大单元(如句子或段落)数量,以防分区过大。
- ECE最小单元数 (ECE Min Units):限制每个分区中包含的最小单元数量,以确保分区内容有足够信息量。
- ECE最大token数 (ECE Max Tokens):限制每个分区内文本内容的总Token数量上限,以适配模型的上下文窗口。
- ECE单元采样策略 (ECE Unit Sampling Strategy):定义从大量单元中选取数据构建分区时所采用的具体策略(如随机选取)。提示- 本地上传文件支持
CSV、JSON、JSONL、PDF、TXT格式,且文件大小不超过100MB。 - 用户上传的文件将存储于
user-data/upload目录,系统通过上传时间戳对文件进行区分。
- 本地上传文件支持
-
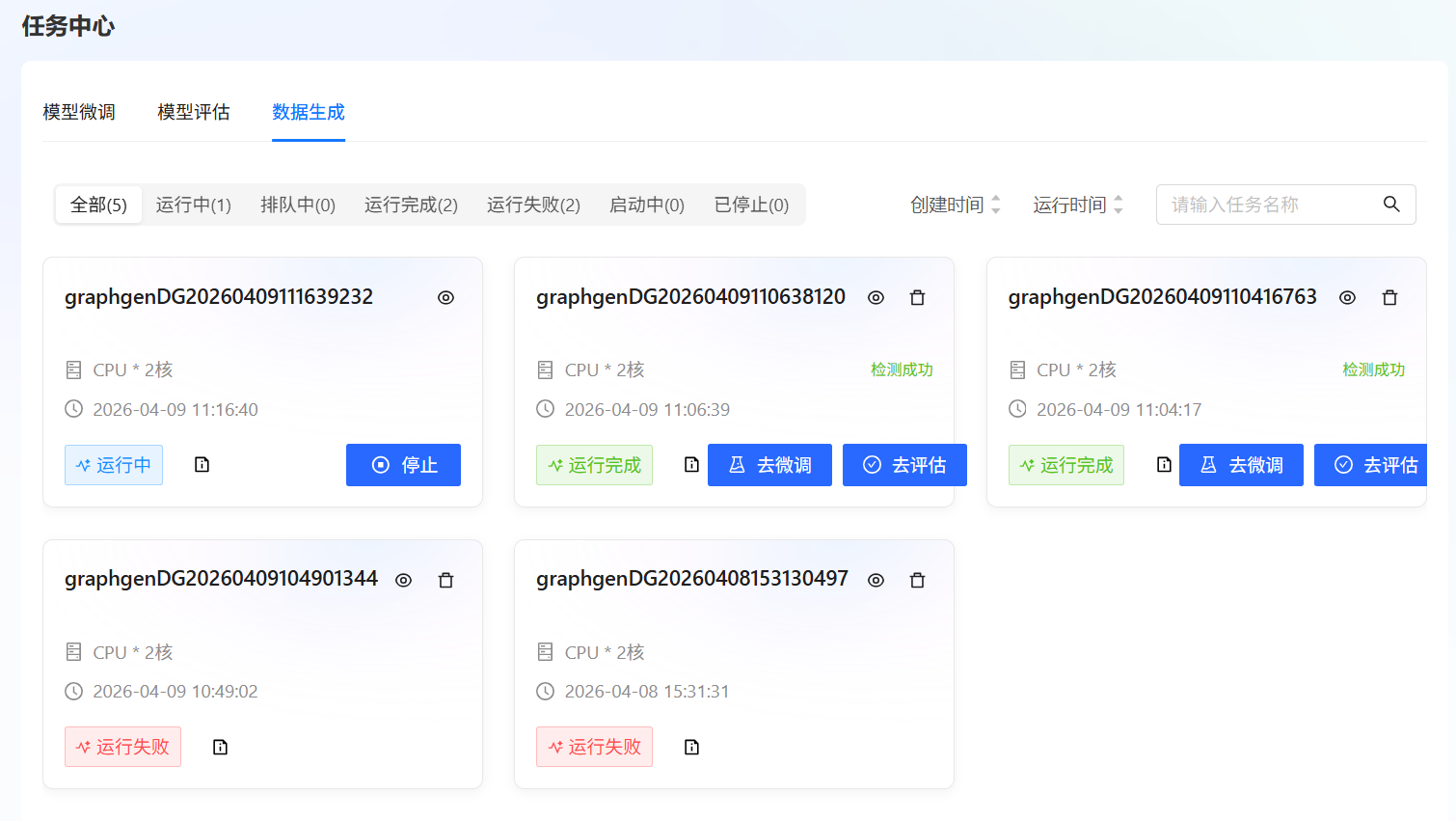
完成参数配置后,点击“立即启动”即可初始化数据生成任务。系统将自动跳转至[任务中心/数据生成]列表页面,如下图所示。
FastDatasets首先通过文档解析精准提取源文本内容,再利用模板批量生成标准化指令数据,快速构建通用大模型的指令遵循能力。此外,它通过优化数据处理流程与生成策略,在提升数据准确性的同时,大幅增强数据生产的整体效率。
-
使用已注册的LlamaFactory Online账号登录平台,选择[数据与模型/数据生成]菜单项,进入数据生成工具选择页面,选择“FastDatasets”,例如下图所示。

-
在FastDatasets数据生成页面配置各参数,参数详情请参考下表,配置页面如下图所示。
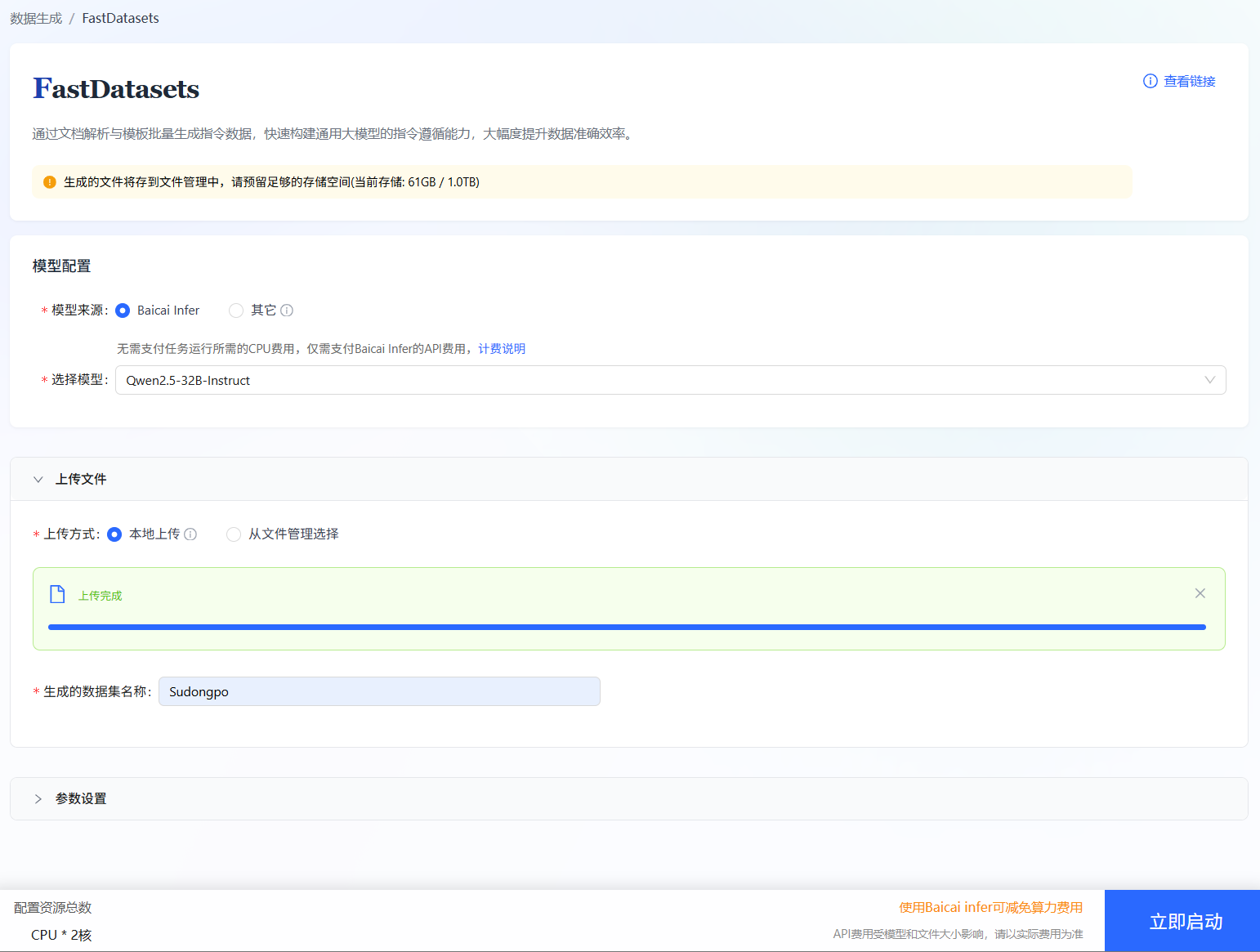
参数配置信息如下表所示:
序号 参数项 说明 1 模型来源 选择模型的服务提供商。
- 您可选择“Baicai Infer”作为生成数据集调用API服务的模型,该来源主要支持的模型有:Qwen2.5-32B-Instruct、Qwen3-32B以及Qwen2.5-VL-32B-Instruct。
- 您可选择“其它”模型来源,该来源需要您配置模型的模型地址(BaseURL/v1)、model以及调用模型的API Key,例如下图所示。2 上传方式 选择FastDatasets生成数据集的源文本,
- 您可选择通过“本地上传”上传本地文件。
- 您也可以选择“从文件管理选择”,例如下图所示。3 生成的数据集名称 用户自定义生成数据集的名称,例如:“Sudongpo”。 4 参数设置 - 最小分块长度:设定文本切片的最短字符限制(200),防止片段过短导致语义缺失。
- 最大分块长度:设定文本切片的最长字符限制(1000),确保片段适合模型处理且不过载。
- 每块问题数:指定针对每一个文本切片需要生成的问答对数量(2个),控制数据生成的密度。- 输出格式:指定生成数据的文件结构标准(Alpaca),以适配特定模型的微调训练需求。提示- 本地上传文件支持
MD、PDF、TXT格式,且文件大小不超过100MB。 - 用户上传的文件将存储于
user-data/upload目录,系统通过上传时间戳对文件进行区分。
- 本地上传文件支持
查看任务
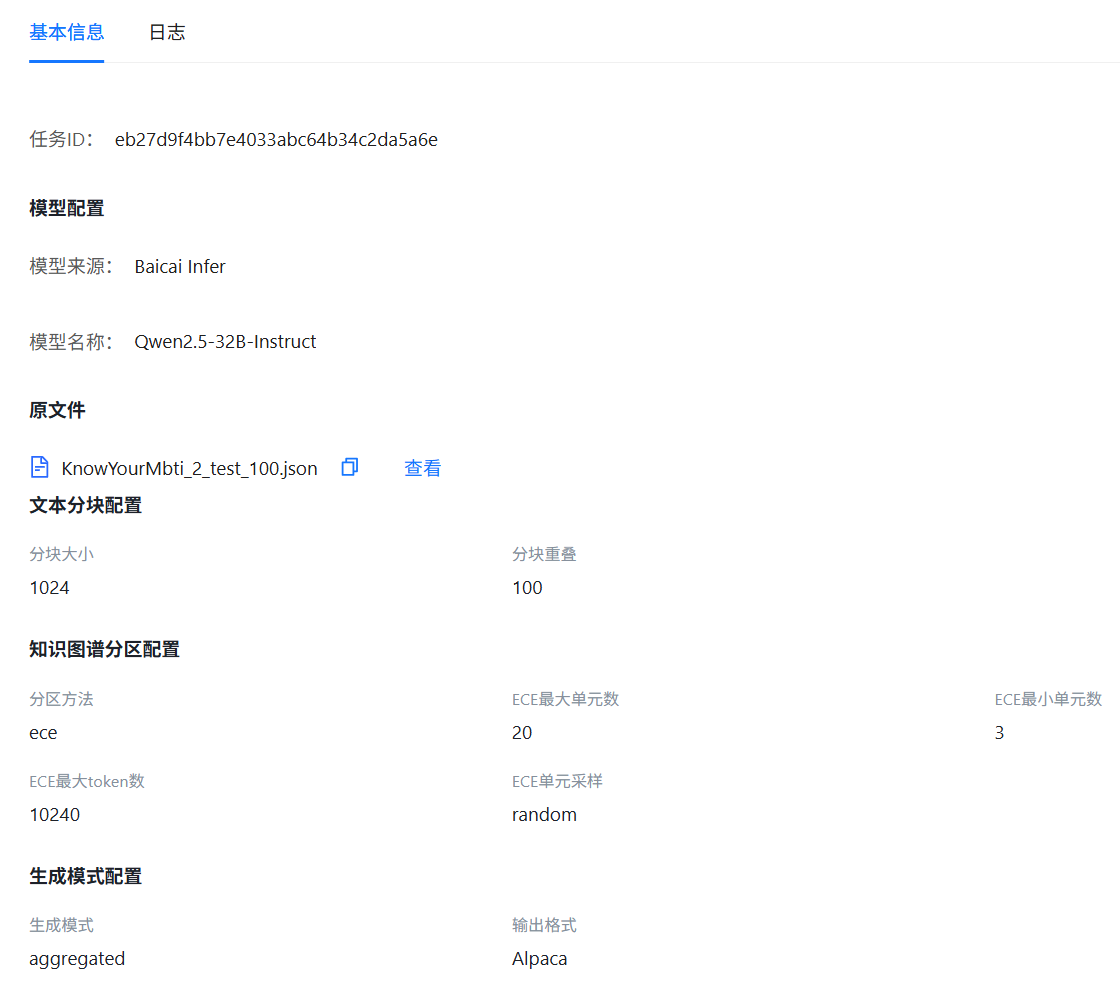
数据生成任务初始化期间,状态显示为“排队中”。在该状态及后续阶段,点击 图标即可查看任务详情,包括任务ID、模型配置、原文件处理及生成模式等,页面如下图所示。
图标即可查看任务详情,包括任务ID、模型配置、原文件处理及生成模式等,页面如下图所示。
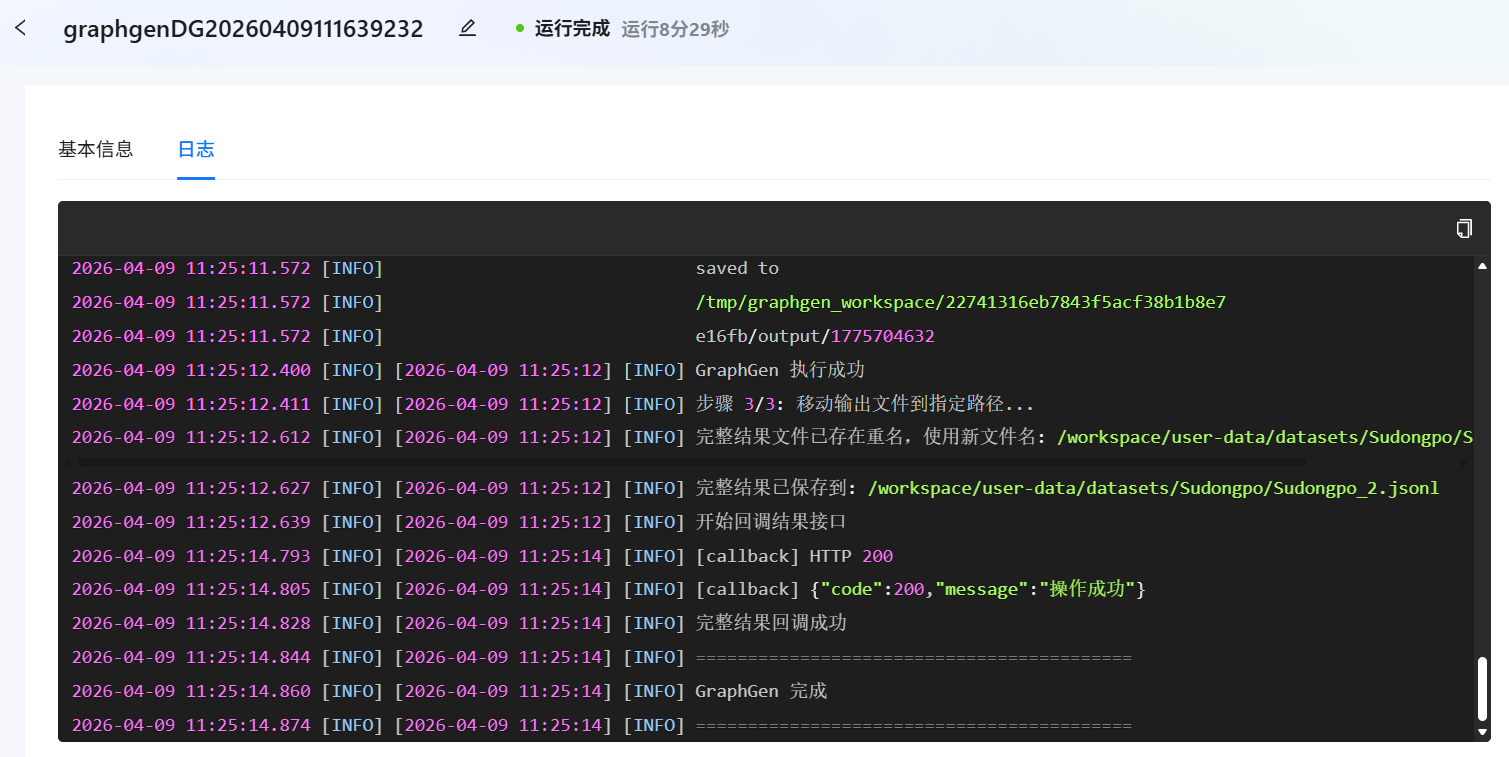
数据生成任务状态转换为“运行中”,在该状态及后续阶段,点击 图标可查看任务运行日志,如下图所示。
图标可查看任务运行日志,如下图所示。
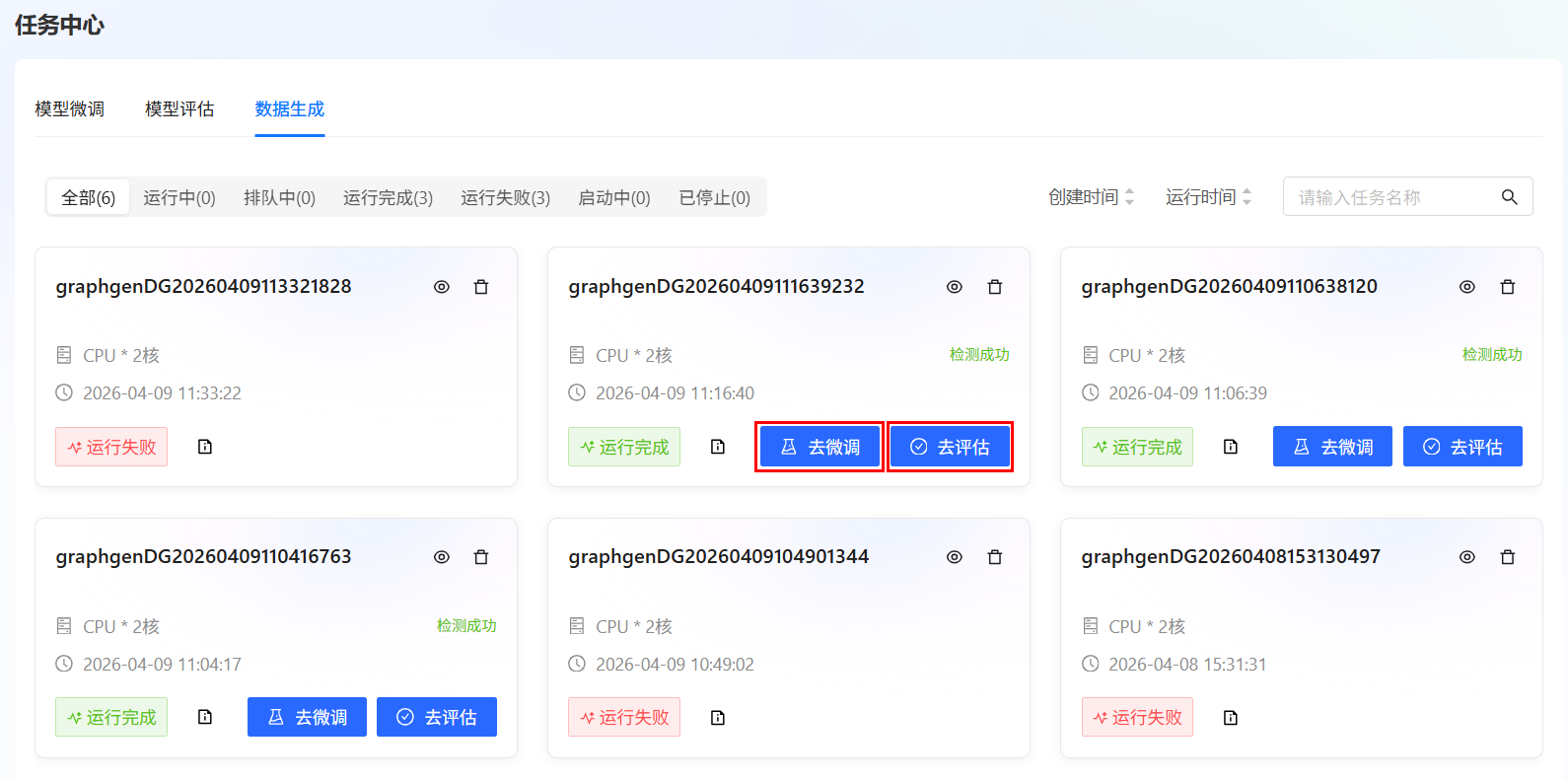
数据生成任务完成后,系统将自动检测生成的数据集是否符合平台规范,规范详情可查看数据集类型。检测通过后,您可以选择点击“去微调”进行模型微调,或点击“去评估”进行模型评估。具体操作请参考模型微调 、模型评估,页面如下图所示。
切换至[数据与模型/文件管理]菜单项,在user-data/datasets目录下可查看以生成的数据集文件,如下图所示。
- 若数据集自动检测结果为“检测失败”,建议您前往数据生成任务日志排查报错原因,根据报错原因做相应处理。
- 若生成数据集时配置的数据集名称重复,系统会将同名的数据集存入以该名称命名的文件夹内,并按时间顺序升序编号排列。