更新时间:2025-07-17 18:30:25
专家微调模式设置了更丰富的参数,用户可以通过调整参数,把控模型训练的方法。
前提条件
- 用户已经获取LlamaFactory Online账户和密码,如果需要帮助或尚未注册,可参考注册账户完成注册。
- 当前账号的余额充裕,可满足模型微调服务的需要。点击可了解最新的活动及费用信息,如需了解更多请联系我们。
- 用户已经准备好符合格式的数据集和模型,您可使用平台内置的模型和数据集,或使用自定义数据集。如需使用自定义数据集,可参考数据处理部分完成数据集的上传和处理。
- 如您需要对模型进行专家微调,则点击 左侧边栏 或 总览 的 “模型微调” ,进行基础模型和数据集、训练参数、训练资源、任务模式的配置。
- 如果您需要使用自定义数据集,请在 data/data_info.json 中添加自定义数据集描述并确保数据集格式正确,否则可能会导致训练失败,详情参见 数据转换 和 数据集配置。
- 预处理数据集时使用的进程数量,“额外参数”详情参考 参数介绍。
基础配置
在基础配置环节,可以选择基础模型、训练数据、训练方式、验证集切分比例及微调方法。具体参数说明如下:

| 参数 | 说明 |
|---|
| 基础模型 | 基础模型为预置的主流模型,下拉可选择模型进行微调。 |
| 训练数据 | 包含公共数据和文件管理数据,支持同时使时选择多个数据集。 |
| 验证集切分比例 | 切分数据集中训练集和验证集的比例,具体比例数值根据数据量和任务需求确定。 |
| 训练方式 | 训练方式包括SFT、Reward Modeling、PPO、DPO、KTO、Pre-Training等。 |
| 微调方法 | 微调方法包括Lora微调、Freeze微调、全量更新等。 |
| 数据加速 | 开启可进行数据加速。 |
| 模型合并 | 开启可对模型进行合并。 |
训练配置
快速微调
相较于“专家微调”,“快速微调”模式简化了参数配置,用户只需配置基础参数,即可对模型进行微调训练,适用于“快速见效”的场景。详情请参见“快速微调”快速微调章节所述。
专家微调
- 点击训练配置框右上角的“专家微调”,进入专家微调模式。相较于快速微调模式,专家模式需要配置更丰富的参数。
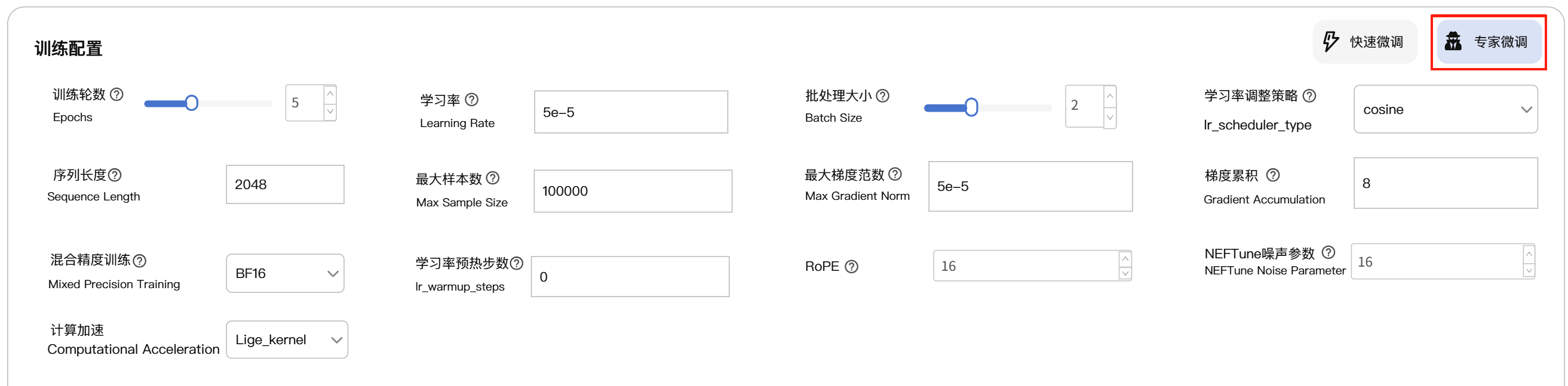
- 专家微调的训练配置扩展了LoRA参数设置、RLHF参数设置、GaLore参数设置等。具体说明如下:
参数说明
训练参数
| 参数 | 说明 | 推荐 |
|---|
| RoPE | | |
| NEFTnue噪声参数 | | |
| 计算加速 | | |
LoRA参数
| 参数 | 说明 | 推荐 |
|---|
| LoRA策略中的秩 | 决定了插入低秩矩阵的表达能力。 | 建议初始设置为8-16。 |
| LoRA缩放系数 | 用于调节低秩更新对原始模型的影响。 | 建议初始设置为秩的2倍或4倍。 |
| LoRA随机丢弃 | | |
| LoRA+学习率比例 | | |
| 新建适配器 | | |
| RSLoRA | | |
| DoRA | | |
| PiSSA | | |
| LoRA作用模块 | | |
| 其他训练模块 | | |
RLHF参数
| 参数 | 说明 | 推荐 |
|---|
| 冻结视觉编码器 | | |
| 冻结多模态投影器 | | |
| 冻结语言模型 | | |
| 图像最大像素 | | |
| 图像最小像素 | | |
| 视频最大像素 | | |
| 视频最小像素 | | |
GaLore参数
| 参数 | 说明 | 推荐 |
|---|
| GoLore优化器 | | |
| GaLore秩 | | |
| GaLore缩放系数 | | |
| 更新间隔 | | |
| GaLore作用模块 | | |
APOLLO参数
| 参数 | 说明 | 推荐 |
|---|
| APOLLO优化器 | | |
| APOLLO秩 | | |
| APOLLO缩放系数 | | |
| 更新间隔 | | |
| APOLLO作用模块 | | |
BAdam参数
| 参数 | 说明 | 推荐 |
|---|
| BAdam优化器 | | |
| BAdam模式 | | |
| 切换策略 | | |
| 切换频率 | | |
| BLock更新比例 | | |
其他参数
| 参数 | 说明 | 推荐 |
|---|
| 日志间隔 | | |
| Checkpoint间隔 | | |
| 额外参数 | | |
| 序列打包 | | |
| 无污染打包 | | |
| 不学习历史对话 | | |
| 学习提示词 | | |
| 更改词表大小 | | |
| LLaMA Pro | | |
| 思考模式 | | |
资源配置
您可选择微调训练时的GPU卡数,默认数值为自动推荐的GPU卡数。付费方式目前仅支持按量付费。
 具体GPU卡数的选择请参照“如何选择GPU卡数”。
具体GPU卡数的选择请参照“如何选择GPU卡数”。
任务模式
可根据不同的模型训练需求选择不同的任务模式,目前提供“极速尊享”、“延时惠享”、“长时省享”和“灵动超省”四种模式。

| 模式 | 排队时长 | 优惠折扣 | 适用场景 |
|---|
| 极速尊享 | 无需长时排队 | 无优惠折扣 | 适用于时效要求高的任务 |
| 延时惠享 | 1小时以内排队,1小时后立即进入极速尊享队列优先调度 | 享7-8折优惠 | 适用于紧迫程度较低的任务 |
| 长时省享 | 1-5小时以内排队,5小时后立即进入极速尊享队列优先调度 | 享6-7折优惠 | 适用于不紧迫的任务 |
| 灵动超省 | 5小时以上排队,资源不足时任务会被停止,充足时继续训练 | 享1-5折优惠 | 适用于灵活度高和中断容忍度高的任务 |
开始训练
 底部显示本次训练配置的资源总数、预估训练时长以及预估费用,消费明细中会显示代金券消费及账户余额消费明细,点击开始训练即可进行训练。
底部显示本次训练配置的资源总数、预估训练时长以及预估费用,消费明细中会显示代金券消费及账户余额消费明细,点击开始训练即可进行训练。