llamafactory online
-
首先在本地完成数据准备,参考https://www.weclone.love/zh/docs/deploy/data_preprocessing.html#%E6%95%B0%E6%8D%AE%E9%A2%84%E5%A4%84%E7%90%86
-
在实例空间选择CPU资源进行相关配置
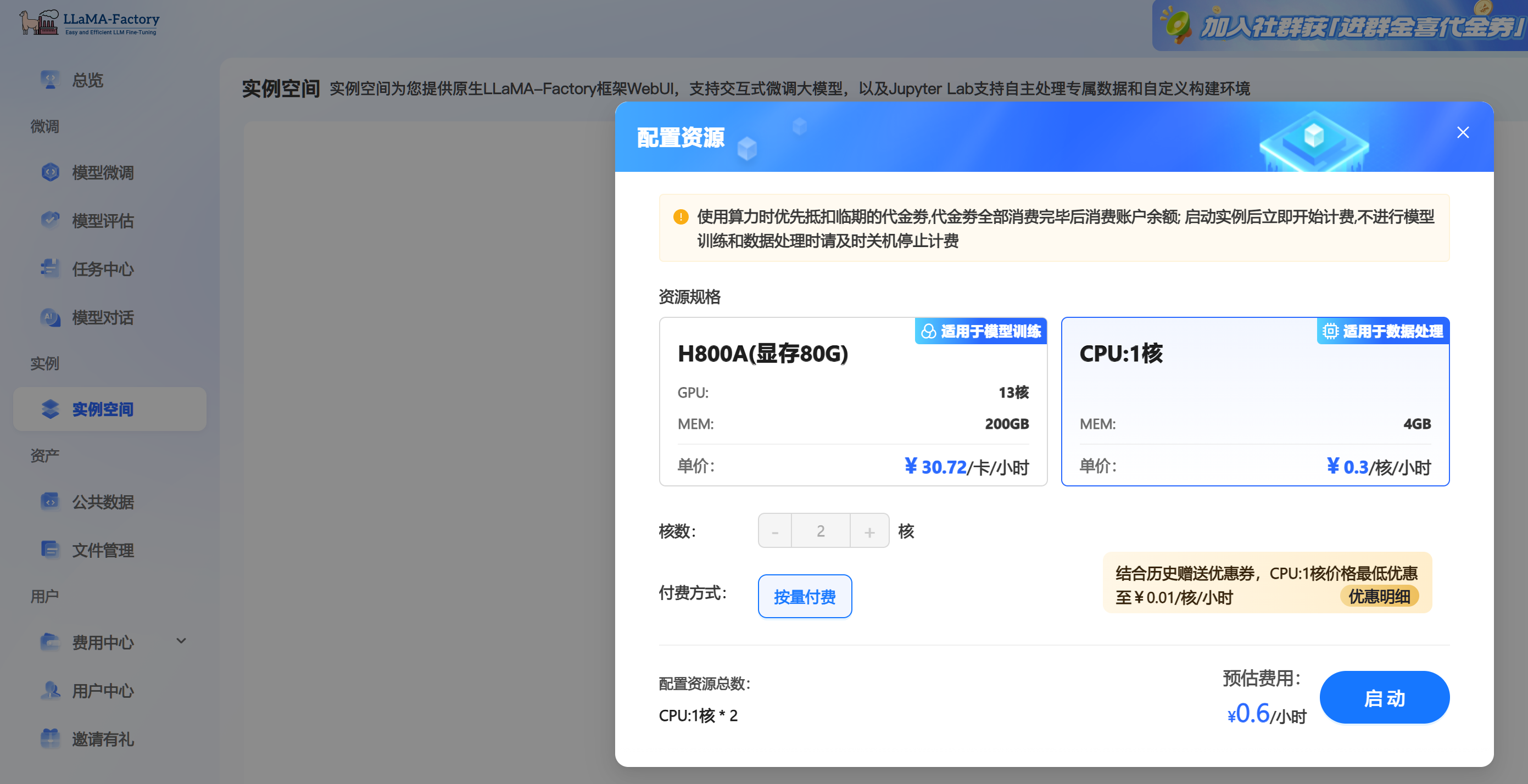
选择**JupyterLab处理专属数据,**将执行
weclone-cli make-dataset后的结果(sft-my.json和dataset_info.json)上传到/workspace/llamafactory/data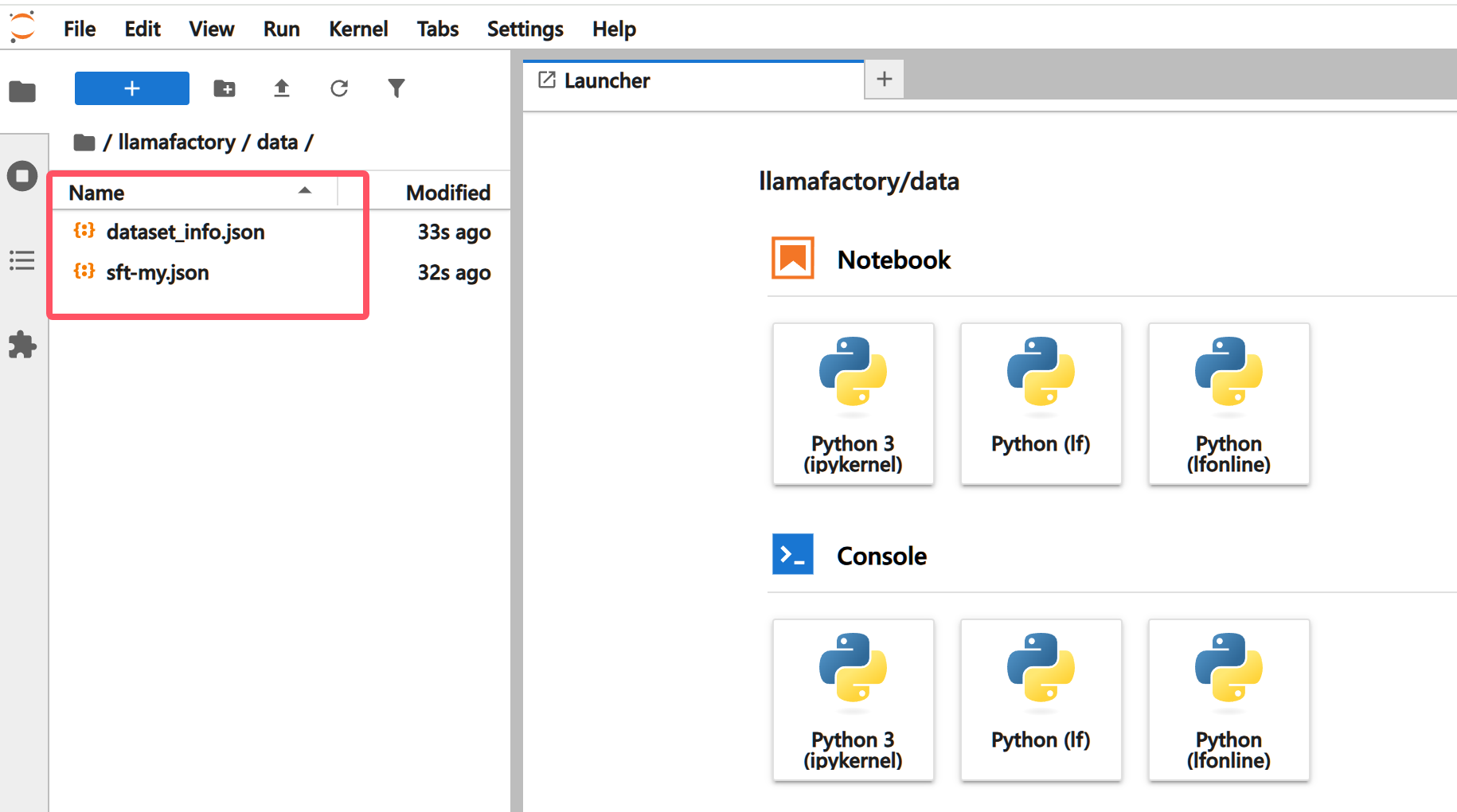
D:\llamafactory-online-docs\static\documents\Practice\llama\image 1.png
进入WebUI填写参数(可根据需要调整)
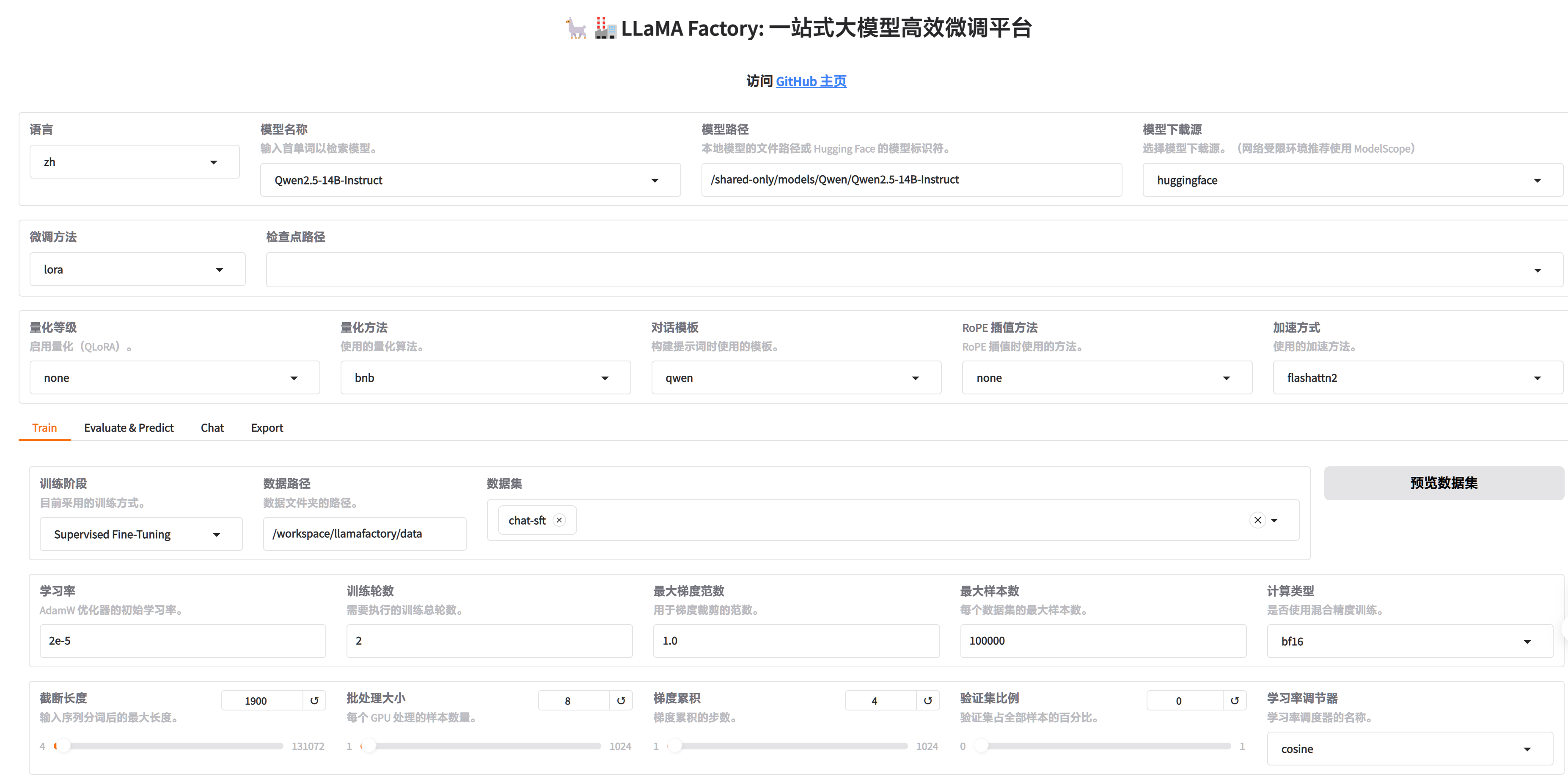
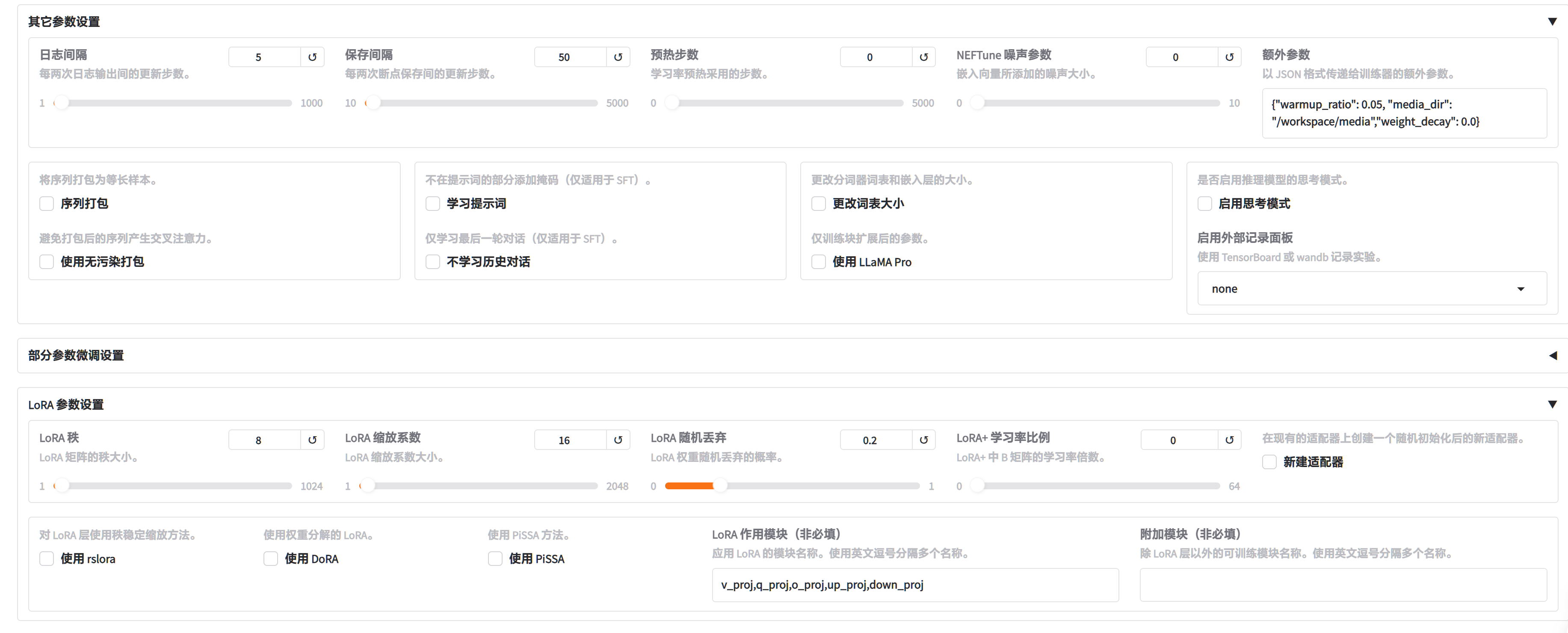
-
关机,重新启动实例,选择GPU资源,在WebUI点击最下方开始,开始微调
-
微调完成后可以点击chat进行测试(需要填写系统提示词,参考
settings.jsonc) -
最后将/workspace/user-data/models/output/Qwen2.5-14B-Instruct/lora目录的训练结果下载到本地进行部署,修改
settings.jsonc的adapter_name_or_path为你下载的目录名